[논문리뷰] Demystifing Video Reasoning
링크: 논문 PDF로 바로 열기
저자: Ruisi Wang, Zhongang Cai, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Chain-of-Frames (CoF) : 기존 연구에서 비디오 Reasoning이 비디오 프레임들을 따라 순차적으로 전개된다고 가정한 가설입니다.
- Chain-of-Steps (CoS) : 본 연구에서 제안하는 메커니즘으로, 비디오 모델 내 Reasoning이 주로 Diffusion Denoising Steps을 따라 발생함을 의미합니다.
- Diffusion Transformers (DiTs) : 비디오 생성 모델에서 사용되는 Transformer 기반의 Diffusion 모델 아키텍처입니다.
- Working Memory : 모델이 Reasoning 과정 전반에 걸쳐 필수 정보를 (예: Object Permanence) 유지하는 능력입니다.
- Training-Free Ensemble : Inference 시점에 여러 개의 동일 모델에서 생성된 Latent Trajectories를 통합하여 Reasoning 성능을 개선하는 전략입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
최근 Diffusion 기반 비디오 생성 모델이 Spatiotemporally Consistent한 시각 환경에서 비 trivial한 Reasoning 능력을 보이는 현상이 발견되었습니다. 기존 연구에서는 이러한 능력을 Chain-of-Frames (CoF) 메커니즘, 즉 Reasoning이 비디오 프레임들을 따라 순차적으로 전개된다는 가설로 설명했습니다. 그러나 비디오 Reasoning의 근본적인 메커니즘은 여전히 광범위하게 탐구되지 않은 상태였습니다. 저자들은 이러한 기존 가설에 도전하고, Diffusion 기반 비디오 모델에서 Reasoning이 실제로 어떻게 발생하는지 체계적으로 조사하여 Underlying Mechanism을 밝히는 것을 목표로 삼았습니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 Chain-of-Frames (CoF) 가설에 이의를 제기하고, Reasoning이 주로 Diffusion Denoising Steps을 따라 전개되는 Chain-of-Steps (CoS) 메커니즘을 밝혀냈습니다. 질적 분석과 타겟 프로빙 실험을 통해, 모델이 초기 Denoising Steps에서 여러 Candidate Solution을 탐색하고 점진적으로 최종 Answer로 수렴하는 과정인 CoS를 확인했습니다 [Figure 1, Figure 2]. 특히, 특정 Diffusion Step에서 노이즈를 주입하는 Noise at Step 방식은 모델 성능을 0.685 에서 0.3 미만으로 크게 저하시킨 반면, 프레임별로 노이즈를 주입하는 Noise at Frame 방식은 훨씬 약한 영향을 미 미쳐 CoS 가설을 강력하게 뒷받침했습니다 [Figure 3].
또한, Diffusion 모델에서 세 가지 주요 Emergent Reasoning Behaviors를 발견했습니다. 첫째, Working Memory로, Object Permanence와 같이 지속적인 참조가 필요한 Task에서 필수적인 Persistent Reference를 가능하게 합니다 [Figure 4]. 둘째, Self-correction and Enhancement로, 부정확한 중간 Solution에서 복구하고 불완전한 Answer를 정교화하는 능력입니다 [Figure 4]. 셋째, Perception before Action으로, 초기 Steps에서 Semantic Grounding을 확립하고 이후 Steps에서 Structured Manipulation을 수행합니다 [Figure 5].
Diffusion Transformers (DiTs) 내부의 Layer-wise Mechanistic Analysis를 통해 Self-evolved Functional Specialization을 밝혀냈습니다. 초기 Layers는 Dense Perceptual Structure를 인코딩하고, 중간 Layers는 Reasoning을 수행하며, 후기 Layers는 Latent Representation을 통합합니다 [Figure 6(a)]. 특히 Layer-wise Latent Swapping Experiment에서는 Layer 20 의 Representation을 교체했을 때 Inference 결과가 완전히 뒤바뀌는 것을 확인하여, 이 Layers가 Reasoning에 결정적인 정보를 담고 있음을 입증했습니다 [Figure 6(b)].
이러한 통찰력을 바탕으로, Inference 시점에 동일 모델의 Latent Trajectories를 세 가지 다른 Random Seed로 앙상블하는 간단한 Training-Free Ensemble 전략을 제안했습니다. 이 접근 방식은 Reasoning 경로의 다양성을 높여 정확한 Solution으로 수렴할 가능성을 높입니다. VBVR-Bench 벤치마크에서 이 Ensemble Method는 Baseline 0.685 대비 0.716 의 성능을 달성하며 2% 의 절대적인 성능 향상을 보였습니다
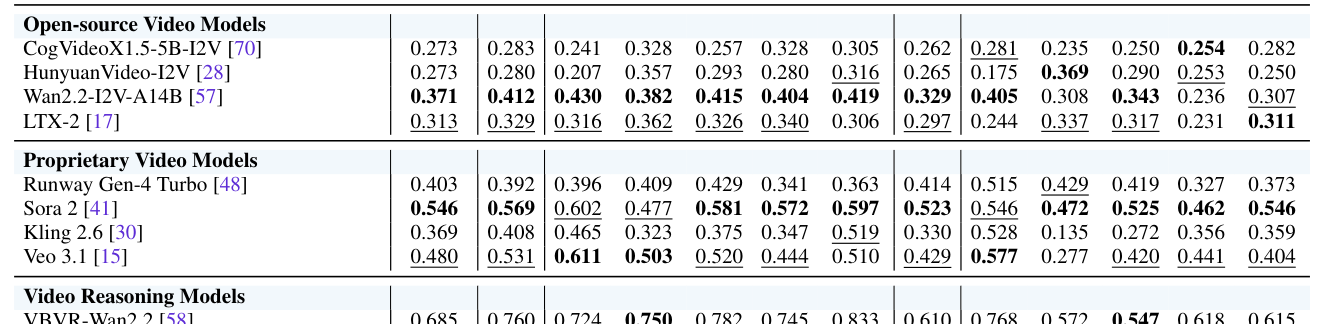 Table 1: Benchmarking results on VBVR-Bench. Overall In-Domain (ID) and Out-of-Domain (OOD) scores are reported alongside category-wise performance. Higher is better. Bold: best in group; underline: second best.
Table 1: Benchmarking results on VBVR-Bench. Overall In-Domain (ID) and Out-of-Domain (OOD) scores are reported alongside category-wise performance. Higher is better. Bold: best in group; underline: second best.
.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 비디오 Reasoning이 프레임 간 순차적 Reasoning(CoF)이 아닌, Diffusion Denoising Steps을 따라 전개되는 Chain-of-Steps (CoS) 메커니즘을 통해 이루어진다는 사실을 명확히 밝혔습니다. 또한, Working Memory, Self-correction and Enhancement, Perception before Action과 같은 Emergent Reasoning Behaviors와 Diffusion Transformers 내부의 Layer Specialization을 식별했습니다. 이러한 발견을 활용한 Training-Free Ensemble 전략은 Reasoning 성능을 효과적으로 개선할 수 있음을 입증했습니다. 이 연구는 비디오 생성 모델에서 Reasoning이 어떻게 발생하는지에 대한 체계적인 이해를 제공하며, 미래의 비디오 Reasoning 시스템 설계 및 인공지능 분야 발전에 중요한 토대를 마련했습니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Video Models Can Reason with Verifiable Rewards
- [논문리뷰] SynCity 3000: Bootstrapping Scene-Scale 3D Diffusion
- [논문리뷰] MV-Forcing: Long Multi-View Video Generation via 4D-Grounded Spatio-Temporal Self-Forcing
- [논문리뷰] Multi-Resolution Flow Matching: Training-Free Diffusion Acceleration via Staged Sampling
- [논문리뷰] PhotoQuilt: Training-Free Arbitrary-Resolution Photomosaics via Bootstrapped Tiled Denoising
Review 의 다른글
- 이전글 [논문리뷰] AgentProcessBench: Diagnosing Step-Level Process Quality in Tool-Using Agents
- 현재글 : [논문리뷰] Demystifing Video Reasoning
- 다음글 [논문리뷰] Efficient Reasoning on the Edge
댓글