[논문리뷰] AgentProcessBench: Diagnosing Step-Level Process Quality in Tool-Using Agents
링크: 논문 PDF로 바로 열기
저자: Shengda Fan, Xuyan Ye, Yupeng Huo, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- LLMs (Large Language Models) : 자연어 처리 작업을 수행하는 대규모 인공지능 모델로, 본 논문에서는 외부 환경 및 도구와 상호작용하는 agent로 활용됩니다.
- Tool-using agents : LLM의 기능을 외부 도구(예: 검색 엔진, CLI 셸, API)와 결합하여 복잡한 작업을 수행하는 autonomous agent입니다.
- Process Reward Models (PRMs) : Agent의 trajectory 내 개별 step의 품질을 평가하고 피드백을 제공하여, 학습 및 추론 과정에서 step-level supervision을 가능하게 하는 모델입니다.
- AgentProcessBench : 본 논문에서 제안하는 벤치마크로, realistic한 tool-using agent trajectory에서 step-level process quality를 진단하고 평가하기 위해 인간이 주석을 단 데이터를 제공합니다.
- StepAcc (Step Accuracy) : 모델 예측과 인간 주석 간의 micro-averaged agreement ratio를 계산하여 전체 step-level labeling 품질을 측정하는 지표입니다.
- FirstErrAcc (First-Error Accuracy) : trajectory 내에서 첫 번째로 발생하는 잘못된 step을 정확히 식별하는 모델의 능력을 측정하는 지표로, 초기 critical failure detection에 중점을 둡니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
LLMs가 tool-using agent로 발전하면서 외부 환경과 상호작용하는 능력은 크게 향상되었지만, long-horizon 상호작용에서는 여전히 취약합니다. 특히 mathematical reasoning과 달리 tool-use 실패는 종종 되돌릴 수 없는 side effects를 야기하므로, 정확한 step-level verification이 매우 중요합니다. 그러나 기존 process-level benchmark들은 주로 closed-world 수학적 도메인에 국한되어 있어, tool execution의 dynamic하고 open-ended한 특성을 포착하지 못합니다. 또한, GAIA나 r²-Bench와 같은 표준 agent benchmark는 End-to-End task success만 보고할 뿐 PRM 평가를 위한 step-level signal을 제공하지 않습니다. 이러한 한계점을 해결하기 위해 realistic한 multi-turn, tool-using interaction에서 step-level process evaluation을 위한 표준화된, 인간이 검증한 benchmark의 필요성이 제기됩니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 LLM의 tool-using trajectory 내 중간 step의 effectiveness를 평가하기 위한 최초의 인간 주석 벤치마크인 AgentProcessBench 를 제안합니다. 이 벤치마크는 task description과 interaction trajectory가 주어졌을 때, 각 assistant step에 대해 +1 (correct/effective) , 0 (neutral/exploratory) , -1 (incorrect/harmful) 의 ternary signal을 부여하도록 모델에 요구합니다. Labeling ambiguity를 줄이기 위해 error-propagation rule을 채택하고, 1,000개 의 diverse trajectory와 8,509개 의 인간 주석 step으로 구성되며, 89.1% 의 높은 inter-annotator agreement를 달성했습니다. 데이터는 HotpotQA, GAIA, BFCL, r²-Bench의 4개 벤치마크와 5개 모델 아키텍처에서 생성된 trajectory를 통합하여 다양성을 확보했습니다.
광범위한 실험 결과는 여러 핵심 insight를 도출합니다.
첫째, 아래 Figure 1에 나타났듯이, 약한 policy 모델들은 early termination으로 인해 StepAcc가 과도하게 높게 나타나는 경향이 있어 FirstErrAcc의 중요성을 강조합니다.
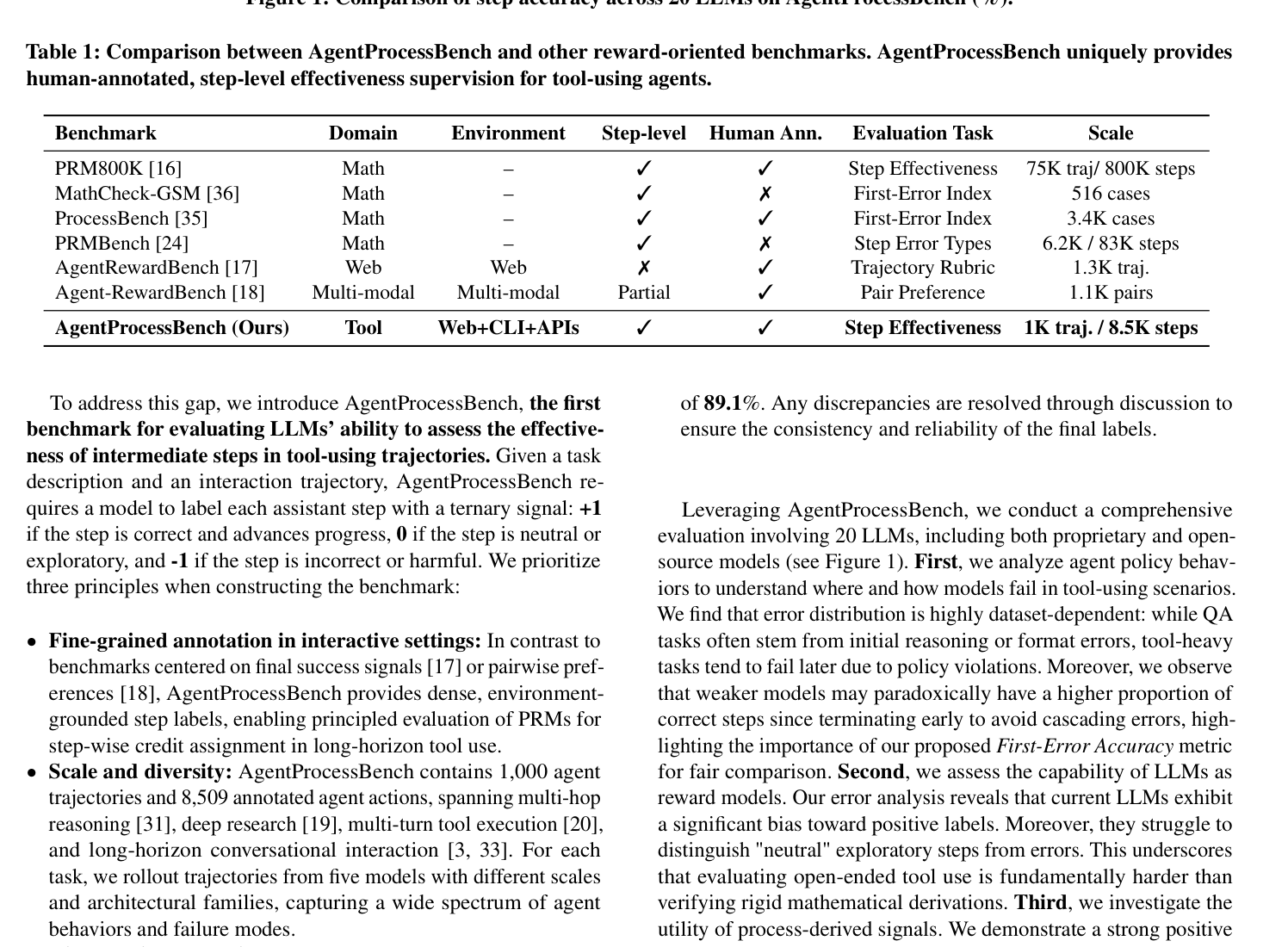 Figure 1: Comparison of step accuracy across 20 LLMs on AgentProcessBench (%).
Figure 1: Comparison of step accuracy across 20 LLMs on AgentProcessBench (%).
둘째, 현재 모델들은 neutral step과 erroneous step을 구분하는 데 어려움을 겪고 있으며, 이는 open-ended tool use 평가가 rigid한 수학적 추론 검증보다 근본적으로 어렵다는 것을 시사합니다.
셋째, 아래 Table 3에서 보듯이, proprietary 모델(예: Gemini-3-Flash-Preview-Thinking)은 81.6%의 평균 StepAcc와 65.8%의 평균 FirstErrAcc를 달성하며 open-source 모델 을 지속적으로 능가합니다. 또한 Thinking 모델 은 동일한 parameter scale에서 instruct 모델보다 성능이 크게 우수합니다(예: Qwen3-8B Thinking 은 StepAcc에서 6.1% , FirstErrAcc에서 5.3% 더 높습니다). Model scale 또한 성능과 강한 상관관계를 보이며, 3B 에서 70B 로 확장될수록 모든 metrics에서 결과가 향상됩니다.
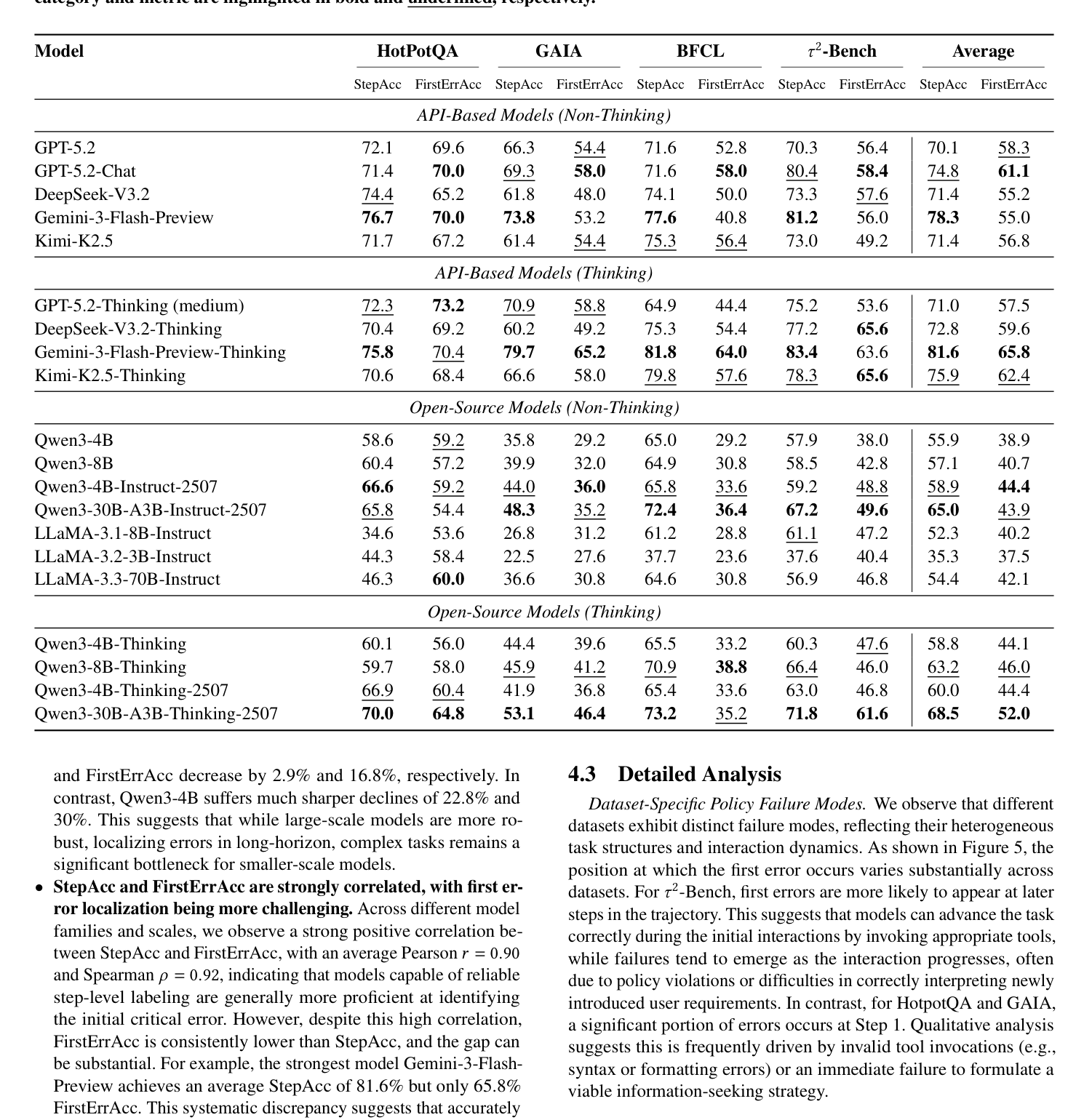 Table 3: Evaluation results on AgentProcessBench, reporting StepAcc and FirstErrAcc (%). Best and second-best results for each category and metric are highlighted in bold and underlined, respectively.
Table 3: Evaluation results on AgentProcessBench, reporting StepAcc and FirstErrAcc (%). Best and second-best results for each category and metric are highlighted in bold and underlined, respectively.
마지막으로, [Figure 7] 에 따르면 StepAcc와 FirstErrAcc는 강한 양의 상관관계를 보이지만 ( Pearson r = 0.90 , Spearman p = 0.92 ), FirstErrAcc가 StepAcc보다 일관되게 낮게 나타나 첫 번째 critical error를 정확히 찾아내는 것이 더 어렵다는 것을 보여줍니다. 또한 process-derived signal은 outcome supervision에 보완적인 가치를 제공하여 Best-of-N 평가를 향상시키는 것으로 나타났습니다.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 tool-using agent의 intermediate step effectiveness를 평가하기 위한 최초의 인간 주석 벤치마크인 AgentProcessBench 를 소개합니다. 20개 LLM에 대한 광범위한 평가는 proprietary 모델과 thinking 모델의 우수성, neutral step과 error step을 구별하는 현재 모델의 어려움, 그리고 process-derived signal의 보완적 가치에 대한 중요한 통찰력을 제공합니다. AgentProcessBench 는 tool-using process reward model 연구를 촉진하고, 더욱 강력하고 신뢰할 수 있는 agentic 시스템 개발을 위한 초석이 될 것입니다. 향후 연구는 AgentProcessBench 를 GUI 기반 agent 및 컴퓨터 사용 agent와 같은 추가 도메인으로 확장할 계획입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] RoboDojo: A Unified Sim-and-Real Benchmark for Comprehensive Evaluation of Generalist Robot Manipulation Policies
- [논문리뷰] MuseBench: Benchmarking Intent-Level Audiovisual Arts Understanding in MLLMs
- [논문리뷰] Speaker-Aware Temporal Aggregation Strategies on Segment Representations for Depression Detection in Dyadic Interaction: A Benchmark Study
- [논문리뷰] DataComp-VLM: Improved Open Datasets for Vision-Language Models
- [논문리뷰] When Search Agents Should Ask: DiscoBench for Clarification-Aware Deep Search
Review 의 다른글
- 이전글 [논문리뷰] daVinci-Env: Open SWE Environment Synthesis at Scale
- 현재글 : [논문리뷰] AgentProcessBench: Diagnosing Step-Level Process Quality in Tool-Using Agents
- 다음글 [논문리뷰] Demystifing Video Reasoning
댓글