[논문리뷰] daVinci-Env: Open SWE Environment Synthesis at Scale
링크: 논문 PDF로 바로 열기
저자: Dayuan Fu, Shenyu Wu, et al.
1. Key Terms & Definitions
- OpenSWE : 대규모의 실행 가능하며 검증 가능한 Docker 기반 Software Engineering (SWE) 환경을 제공하는 투명한 프레임워크. SWE Agent 훈련을 위해 고안됨.
- SWE-bench Verified : SWE Agent의 성능을 평가하기 위해 사용되는 표준 벤치마크 데이터셋으로, 실제 GitHub 이슈와 PR 쌍으로 구성됨.
- Dockerfile : Docker 이미지를 빌드하기 위한 일련의 명령어를 포함하는 텍스트 파일. OpenSWE 환경 구성의 핵심 요소.
- Trajectory Sampling : Agent가 환경과 상호작용하는 과정에서 발생하는 일련의 행동과 관찰을 기록하는 데이터 수집 과정.
- Difficulty-Aware Curation : 환경의 내재적 난이도를 평가하여, 너무 쉽거나 해결 불가능한 인스턴스를 필터링하고 학습 효율성을 극대화하는 적절한 난이도의 환경을 선별하는 과정.
2. Motivation & Problem Statement
Large Language Models (LLMs)의 발전은 자율적인 Software Engineering (SWE) agent 개발을 가속화하고 있지만, 이러한 agent를 효과적으로 훈련하기 위해서는 대규모의 실행 가능하며 검증 가능한 환경이 필수적입니다. 이러한 환경은 반복적인 코드 편집, 테스트 실행, 솔루션 개선을 위한 동적 피드백 루프를 제공해야 합니다. 그러나 기존의 오픈 소스 데이터셋은 규모와 저장소 다양성 측면에서 제한적이며, 산업계 솔루션은 비공개 인프라를 사용하므로 대부분의 학술 연구 그룹에 높은 진입 장벽을 만듭니다. 또한, 환경 구축에 드는 엄청난 계산 및 인프라 비용 외에도, 환경의 Quality 및 Difficulty Distribution 이 agent 훈련 효율성에 매우 중요합니다. [Figure 2]에서 설명하듯이, 실제 저장소에서 합성된 환경은 PR-Issue Misalignment (제출된 패치가 설명된 이슈를 실제로 해결하지 못함) 또는 Triviality (이슈 설명만으로 해결책이 직접적으로 드러남)와 같은 문제로 인해 해결 불가능하거나 충분히 도전적이지 않아 의미 있는 학습 신호를 제공하지 못하는 경우가 많습니다. 본 연구는 이러한 문제를 해결하고, 확장 가능하며 투명한 고품질 SWE 환경을 제공하는 것을 목표로 합니다.
3. Method & Key Results
본 연구는 SWE agent 훈련을 위한 가장 큰 규모의 완전 투명 프레임워크인 OpenSWE 를 제안합니다. OpenSWE는 12.8k 개 이상의 저장소에서 파생된 45,320 개의 실행 가능한 Docker 환경으로 구성되며, 모든 Dockerfile , 평가 스크립트 및 인프라가 재현성을 위해 완전히 오픈 소스로 공개됩니다
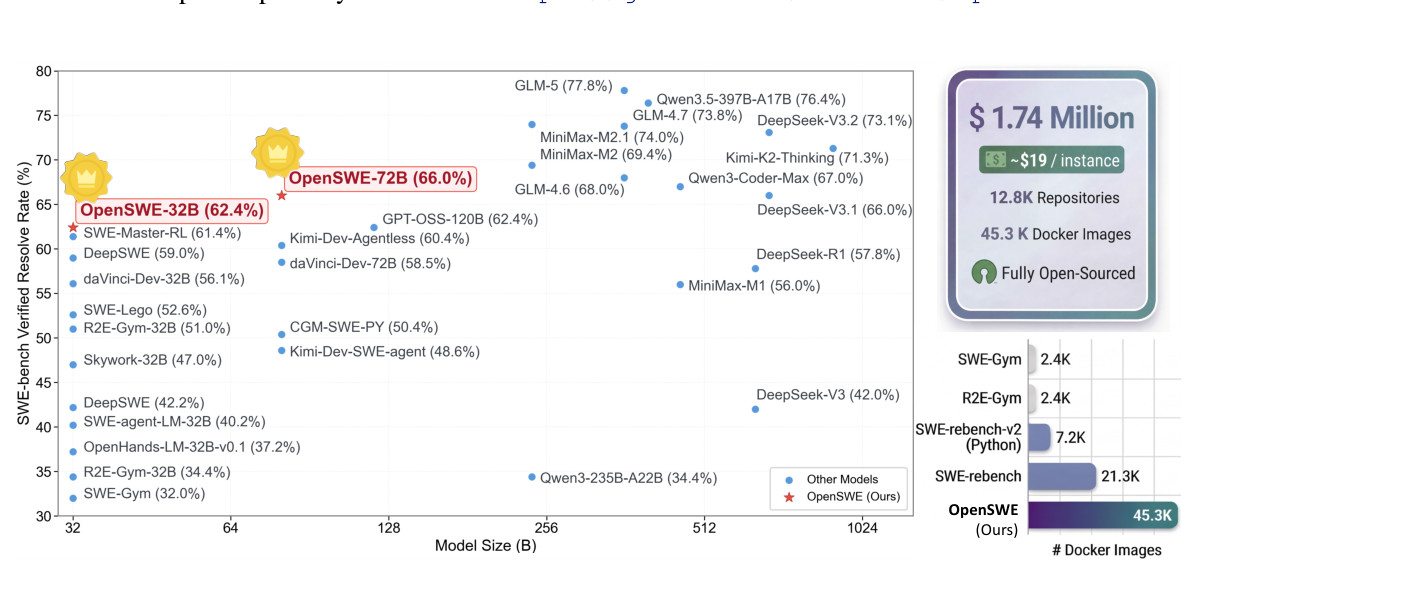 Figure 1: Image construction and performance overview of OpenSWE.
Figure 1: Image construction and performance overview of OpenSWE.
. 이 프레임워크는 64-node distributed cluster 에 배포된 multi-agent synthesis pipeline 을 통해 구축되며, 저장소 탐색, Dockerfile 생성, 평가 스크립트 생성, 반복적인 테스트 분석을 자동화합니다
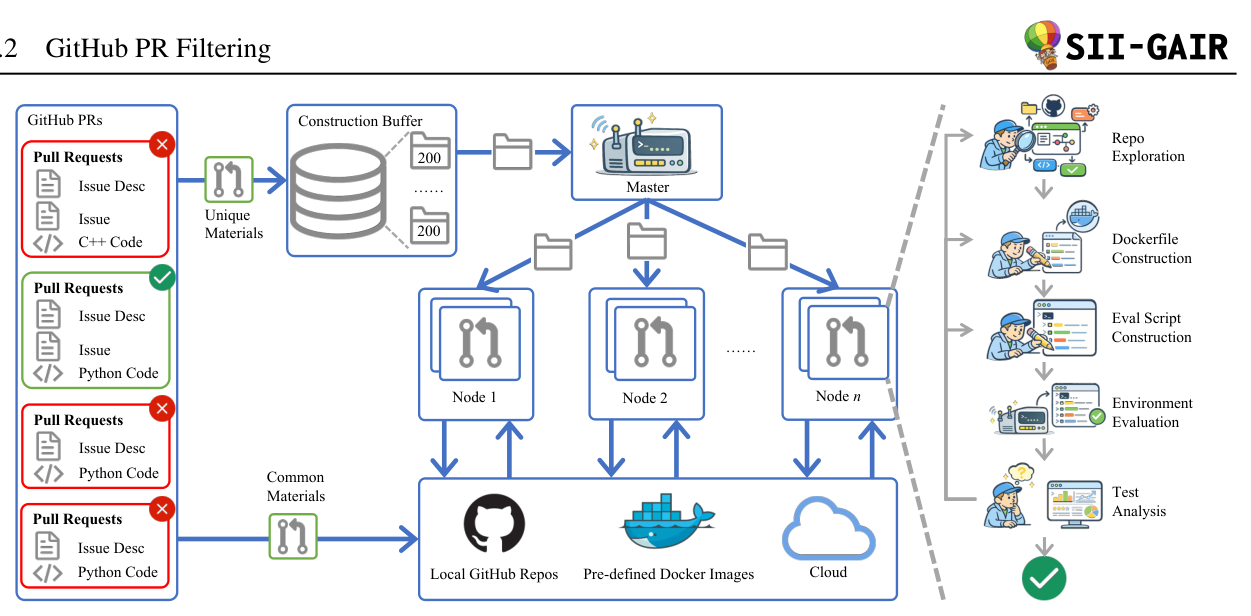 Figure 3: The framework of OpenSWE.
Figure 3: The framework of OpenSWE.
. 단순한 규모 확장뿐만 아니라, Quality-Centric Filtering pipeline 을 도입하여 해결 불가능하거나 충분히 도전적이지 않은 인스턴스를 걸러내고 학습 효율성을 극대화하는 적절한 난이도의 환경만을 선별합니다. 전체 프로젝트에는 환경 구축에 약 $891K , Trajectory Sampling 및 Difficulty-Aware Curation 에 추가로 약 $576K 가 소요되어 총 $1.47 million 의 투자가 이루어졌으며, 이를 통해 약 9,000 개의 Quality Guaranteed Environments 에서 13,000 개의 Curated Trajectories 를 확보했습니다.
광범위한 실험 결과는 OpenSWE의 효과를 입증합니다. SWE-bench Verified 벤치마크에서 OpenSWE-32B 모델은 62.4% , OpenSWE-72B 모델은 66.0% 의 Resolve Rate 를 달성하며 Qwen2.5 시리즈 기반 SFT 방법론 중 SOTA 를 수립했습니다
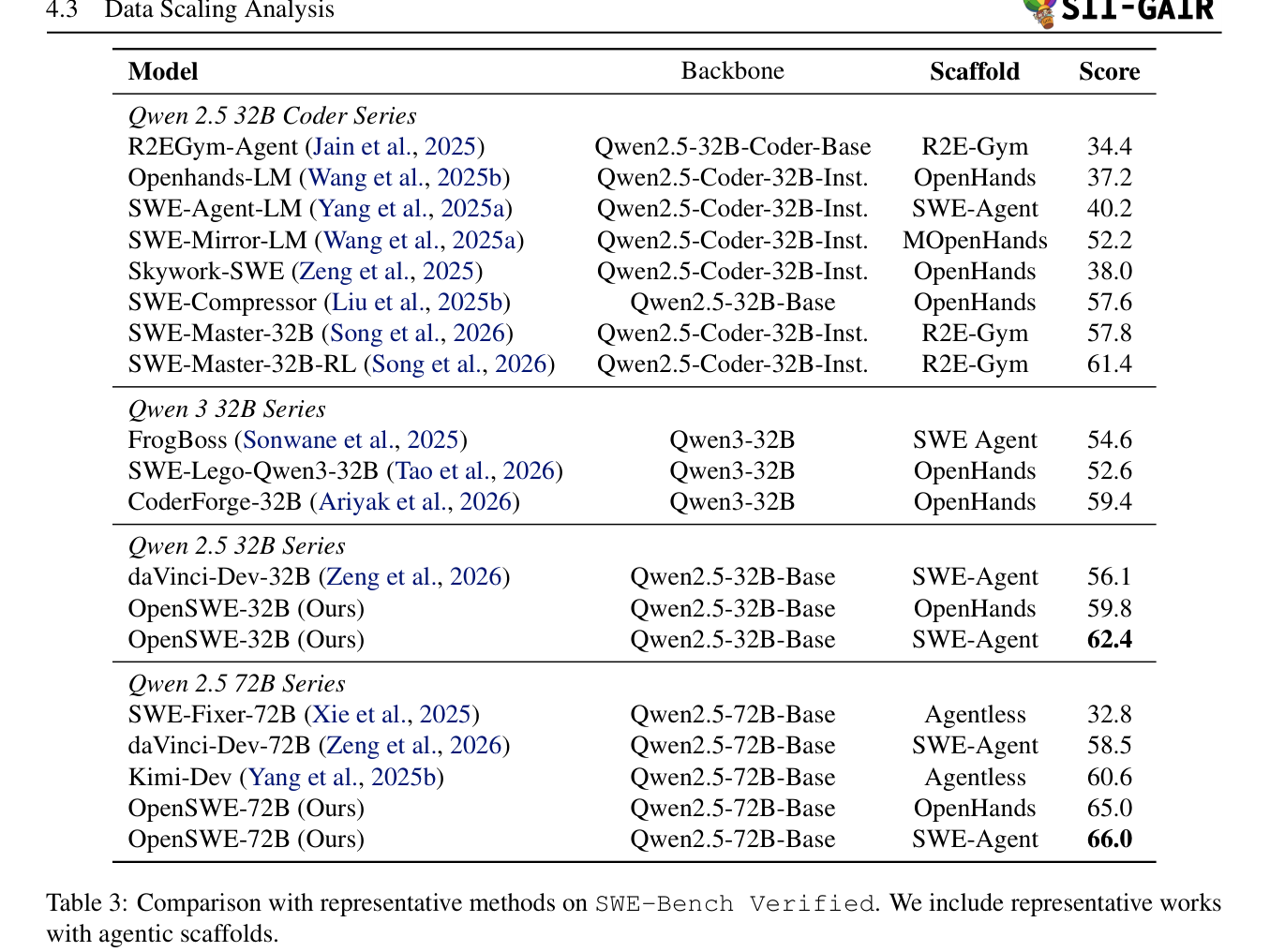 Table 3: Comparison with representative methods on SWE-Bench Verified. We include representative works with agentic scaffolds.
Table 3: Comparison with representative methods on SWE-Bench Verified. We include representative works with agentic scaffolds.
. OpenSWE로 훈련된 모델은 SWE-rebench 로 훈련된 모델을 모든 설정에서 일관되게 능가하며, [Table 4]에서 볼 수 있듯이 32B SWE-Agent 설정에서 OpenSWE는 62.4% 를 달성하여 SWE-rebench 의 50.2% 대비 12.2% 의 상당한 절대 성능 향상을 보였습니다. 데이터 스케일링 분석 결과, Log-Linear Improvement Trend 가 포착되었으며, [Figure 4]에서 나타나듯이 현재 예산 범위 내에서는 Saturation 징후가 보이지 않아 추가 데이터 스케일링이 성능 향상으로 이어질 것임을 시사합니다. 또한, SWE 중심 훈련은 Mathematical Reasoning 에서 최대 12 points (MATH-500) 및 Science Benchmarks 에서 최대 5 points (SciBench)의 상당한 Out-of-Domain Improvements 를 가져왔으며, Factual Recall 은 저하되지 않았습니다 (MMLU remains flat) [Table 5].
4. Conclusion & Impact
본 연구는 SWE agent 훈련을 위한 최대 규모의 완전 투명 프레임워크인 OpenSWE 를 성공적으로 구축하고 공개했습니다. 45,320 개의 실행 가능한 Docker 환경과 모든 인프라를 오픈 소스로 제공함으로써, 학계 및 산업계의 SWE agent 연구에 중요한 기여를 합니다. Multi-agent synthesis pipeline 과 Quality-Centric Filtering 을 통해 구축된 High-Quality Environment 는 SWE agent의 Training Effectiveness 를 크게 향상시키며, SWE-bench Verified 에서 SOTA 성능을 달성함과 동시에 Out-of-Domain Improvements 까지 이끌어냈습니다. 이는 데이터 스케일링과 난이도 기반 큐레이션의 상호 보완적인 중요성을 강조하며, 앞으로 더욱 강력하고 일반화된 SWE agent 개발의 기반을 마련할 것으로 기대됩니다. OpenSWE는 재현 가능한 연구를 촉진하고 커뮤니티 주도 개선을 가능하게 할 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] ScaleEnv: Scaling Environment Synthesis from Scratch for Generalist Interactive Tool-Use Agent Training
- [논문리뷰] daVinci-Dev: Agent-native Mid-training for Software Engineering
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] PluraMath: Extending Mathematical Reasoning Evaluation Beyond High-Resource Languages
- [논문리뷰] Hierarchical Sparse Attention Done Right: Toward Infinite Context Modeling
Review 의 다른글
- 이전글 [논문리뷰] Visual-ERM: Reward Modeling for Visual Equivalence
- 현재글 : [논문리뷰] daVinci-Env: Open SWE Environment Synthesis at Scale
- 다음글 [논문리뷰] AgentProcessBench: Diagnosing Step-Level Process Quality in Tool-Using Agents
댓글