[논문리뷰] Visual-ERM: Reward Modeling for Visual Equivalence
링크: 논문 PDF로 바로 열기
저자: Ziyu Liu, Shengyuan Ding, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Vision-to-Code : 차트, 테이블, SVG와 같은 구조화된 시각적 입력을 코드 또는 마크다운과 같은 실행 가능하거나 구조화된 표현으로 재구성하는 작업을 의미합니다.
- Reward Model (RM) : Reinforcement Learning (RL)에서 정책 최적화를 안내하는 피드백 신호를 제공하는 모델입니다.
- Visual-ERM (Visual Equivalence Reward Model) : 렌더링된 시각적 공간에서 직접 Vision-to-Code 품질을 평가하는 미세 조정되고, 해석 가능하며, 작업에 구애받지 않는 피드백을 제공하는 멀티모달 생성형 Reward Model입니다.
- VisualCritic-RewardBench (VC-RewardBench) : 구조화된 시각 데이터(차트, 테이블, SVG)에서 미세한 이미지 간 불일치 판단을 평가하기 위한 벤치마크입니다.
- Test-Time Scaling (TTS) : 모델이 Reward Model의 피드백을 기반으로 출력을 반복적으로 자기 개선(self-refinement)하는 프로세스입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Vision-to-Code 작업은 AI 지원 프론트엔드 개발, 과학 논문 파싱, 지식 관리 및 시스템 통합과 같은 다양한 하위 시스템에 필수적인 핵심 기능입니다. 그러나 현재 Vision-to-Code 모델은 주로 Supervised Fine-Tuning (SFT) 을 통해 성능을 개선하며, 이는 방대한 데이터 주입이 필요하고 교차 도메인 일반화 능력이 부족하다는 한계가 있습니다. Reinforcement Learning (RL) 은 유망한 대안이지만, 신뢰할 수 있는 Reward Supervision의 필요성이라는 새로운 과제를 안고 있습니다.
기존의 Reward 접근 방식은 크게 두 가지로 나뉩니다. 첫째, Text-based metrics (예: Edit Distance, Tree Edit Distance Similarity ( TEDS ))는 순전히 텍스트 도메인에서 작동하여 정렬, 간격, 레이아웃 오류와 같은 중요한 시각적 단서를 놓치고 Reward Hacking 에 취약합니다. 둘째, Vision-encoder rewards (예: DINO )는 시각 인코더에서 추출된 표현의 유사성을 비교하지만, 이는 coarse-grained하고 의미론적으로 편향되어 미세한 시각적 세부 사항에 둔감하며, 이 또한 Reward Hacking 에 취약합니다
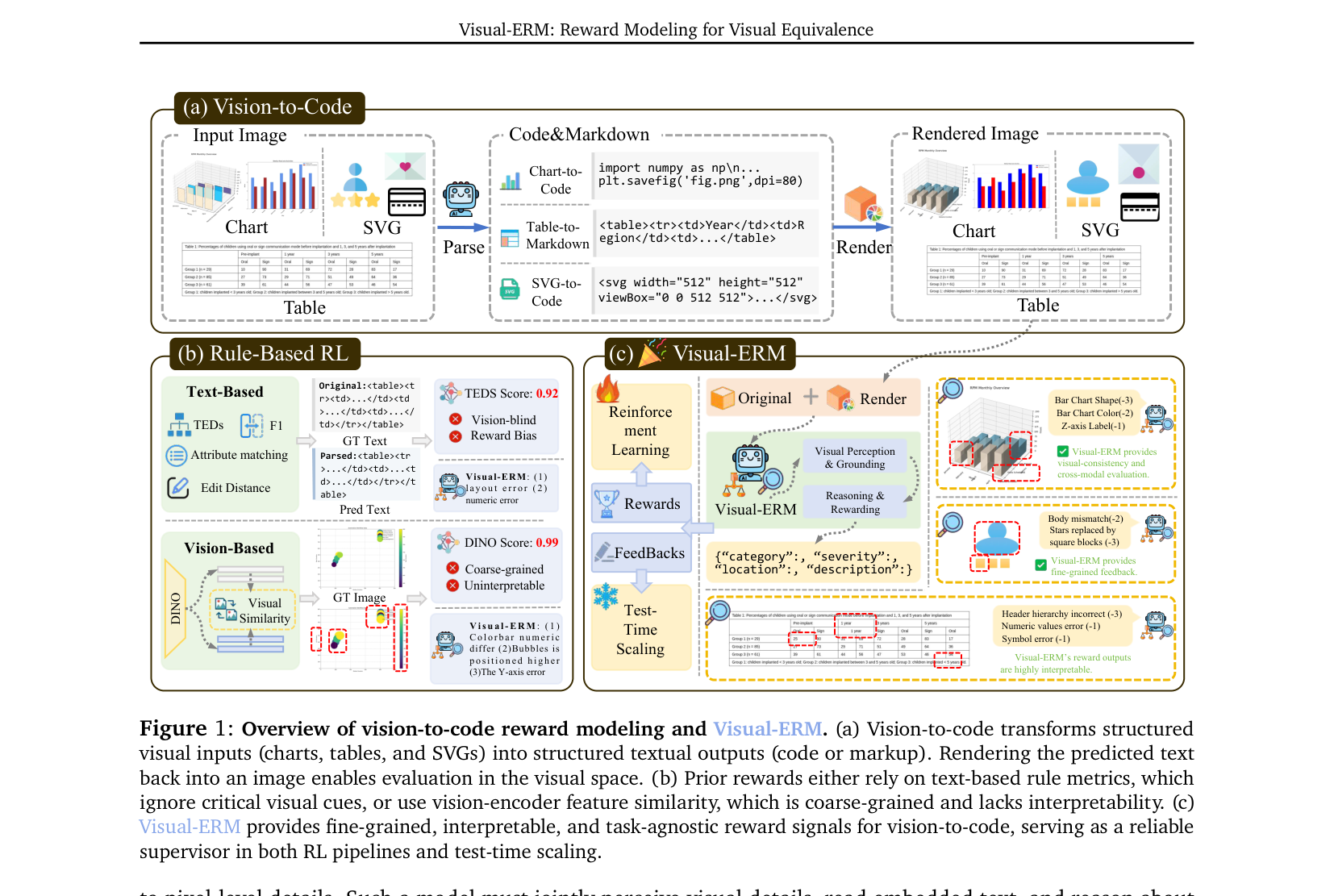 Figure 1: Overview of vision-to-code reward modeling and Visual-ERM.
Figure 1: Overview of vision-to-code reward modeling and Visual-ERM.
. 이러한 기존 방법들은 미세한 시각적 불일치를 정확하게 포착하지 못하고 잘못 정렬된 Reward Signal을 제공하여, Vision-to-Code RL 훈련에 부적합합니다. 이러한 한계는 Reward Model이 텍스트 및 시각적 증거를 통합하는 근본적으로 다른 접근 방식이 필요함을 시사합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 이러한 한계를 해결하기 위해 Visual Equivalence Reward Model (Visual-ERM) 을 제안합니다. Visual-ERM 은 멀티모달 생성형 Reward Model로, 렌더링된 시각적 공간에서 직접 Vision-to-Code 품질에 대한 fine-grained, 해석 가능하며, 작업에 구애받지 않는 피드백을 제공합니다. 이는 전역 구조와 로컬 시각적 세부 사항을 함께 모델링하여 Reward Signal의 세 가지 핵심 속성을 제공합니다: (i) Fine-grained: 미세한 시각적 불일치를 포착합니다. (ii) Interpretable: Test-Time Scaling (TTS) 을 위한 반성과 수정(reflection and revision)을 안내하는 진단 피드백을 생성합니다. (iii) Task-agnostic: 단일 RM 이 Chart-to-Code, Table-to-Markdown, SVG-to-Code 전반에 걸쳐 일반화됩니다.
Visual-ERM 은 Qwen3-VL-8B-Instruct 를 기반으로 구축되며, GPT-5-mini 로부터의 증류(distillation)를 통해 fine-grained 주석이 포함된 이미지 쌍( Dreward )으로 supervised fine-tuning (SFT)하여 훈련됩니다 [Figure 2]. 이 모델은 GRPO 알고리즘을 사용하는 RL 파이프라인과 TTS 에 통합됩니다. Reward Model의 품질을 직접 측정하기 위해, 차트, 테이블, SVG 전반의 fine-grained 이미지 간 불일치 판단을 평가하는 VisualCritic-RewardBench (VC-RewardBench) 벤치마크를 도입했습니다.
주요 실험 결과는 다음과 같습니다:
- VC-RewardBench 에서 Visual-ERM 은 Qwen3-VL-235B-Instruct 를 크게 능가하며, F1h/F1s/Sc 지표에서 각각 +36.8/+38.2/+40.9 포인트 향상된 성능을 보여주었습니다
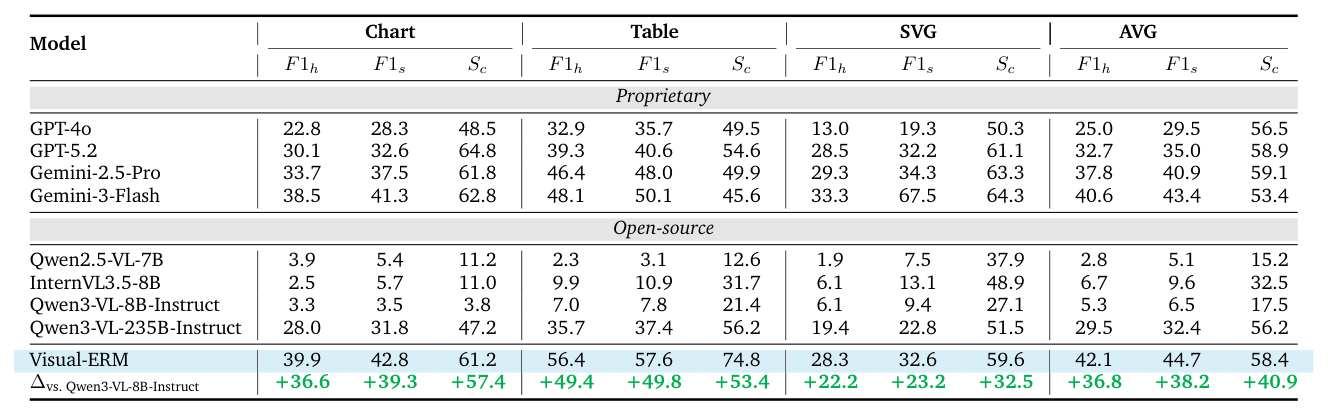 Table 4: Evaluation Results on Visual-ERM-Bench.
Table 4: Evaluation Results on Visual-ERM-Bench.
. 이는 Visual-ERM 이 fine-grained 불일치 감지 및 충실도 판단에서 뛰어난 전문성을 가지고 있음을 나타냅니다.
- Chart-to-Code 작업에서 Visual-ERM 을 RL 에 통합했을 때, Qwen3-VL-8B-Instruct 의 평균 점수를 +8.4 포인트 향상시켰습니다
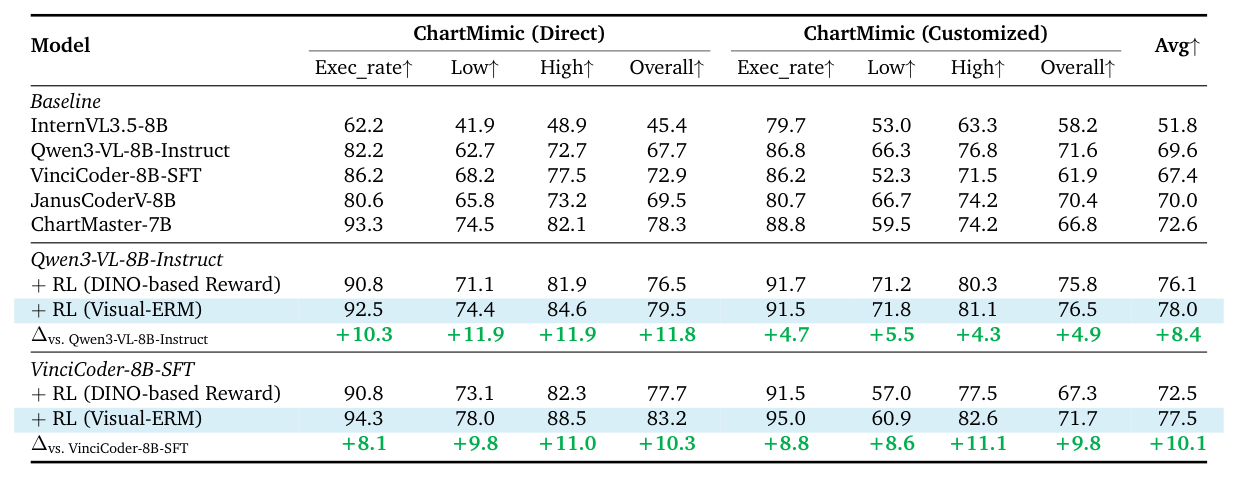 Table 1: Evaluation Results on Chart-to-Code Tasks.
Table 1: Evaluation Results on Chart-to-Code Tasks.
. 또한 이미 강력한 VinciCoder-8B-SFT 모델에서도 +10.3 및 +9.8 포인트의 일관된 성능 향상을 가져왔습니다.
- Table-to-Markdown Parsing 에서는 Visual-ERM 기반 RL 이 Qwen3-VL-8B-Instruct 에 대해 전체적으로 +2.7 포인트의 일관된 성능 향상을 달성했습니다 [Table 2].
- SVG-to-Code Parsing 에서는 Visual-ERM 기반 RL 이 백본 전반에 걸쳐 평균 +4.1 포인트의 일관된 이득을 제공했습니다 [Table 3].
- Test-Time Scaling (TTS) 에서 Visual-ERM 을 활용한 reflection 및 revision은 Chart-to-Code 작업에서 Qwen3-VL-8B-Instruct 에 +8.0 포인트, RL 튜닝 모델에 +3.1 포인트의 추가적인 성능 향상을 가져왔습니다 [Table 5].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Vision-to-Code 출력의 시각적 동등성을 평가하기 위한 멀티모달 생성형 Reward Model인 Visual-ERM 을 제안합니다. Visual-ERM 은 fine-grained하고 해석 가능하며 작업에 구애받지 않는 Supervision을 제공함으로써 기존의 텍스트 기반 및 Vision-encoder 유사성 Reward의 근본적인 한계인 모달리티 편향과 Reward Hacking 문제를 해결합니다.
또한, fine-grained 이미지 간 불일치 판단을 직접 평가하기 위한 VisualCritic-RewardBench 벤치마크를 도입했습니다. 실험 결과는 Visual-ERM 이 Reinforcement Learning 과 Test-Time Scaling 모두에 효과적인 Supervisor이며, 여러 작업에서 Vision-to-Code 성능을 일관되게 향상시킴을 보여줍니다. 이 연구는 fine-grained 시각적 Reward Supervision이 Vision-to-Code RL 에 필요하고도 충분함을 시사하며, 구조화된 시각 데이터 처리를 위한 더욱 신뢰할 수 있고 일반화 가능한 LVLMs 개발에 중요한 영향을 미칩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] MaxProof: Scaling Mathematical Proof with Generative-Verifier RL and Population-Level Test-Time Scaling
- [논문리뷰] Skill-RM: Unifying Heterogeneous Evaluation Criteria via Agent Skill
- [논문리뷰] Small RL Controller, Large Language Model: RL-Guided Adaptive Sampling for Test-Time Scaling
- [논문리뷰] iVGR: Internalizing Visually Grounded Reasoning for MLLMs with Reinforcement Learning
- [논문리뷰] RUBRIC-ARROW: Alternating Pointwise Rubric Reward Modeling for LLM Post-training in Non-verifiable Domains
Review 의 다른글
- 이전글 [논문리뷰] Video Streaming Thinking: VideoLLMs Can Watch and Think Simultaneously
- 현재글 : [논문리뷰] Visual-ERM: Reward Modeling for Visual Equivalence
- 다음글 [논문리뷰] daVinci-Env: Open SWE Environment Synthesis at Scale
댓글