[논문리뷰] Language on Demand, Knowledge at Core: Composing LLMs with Encoder-Decoder Translation Models for Extensible Multilinguality
링크: 논문 PDF로 바로 열기
저자: Mengyu Bu, Yang Feng, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
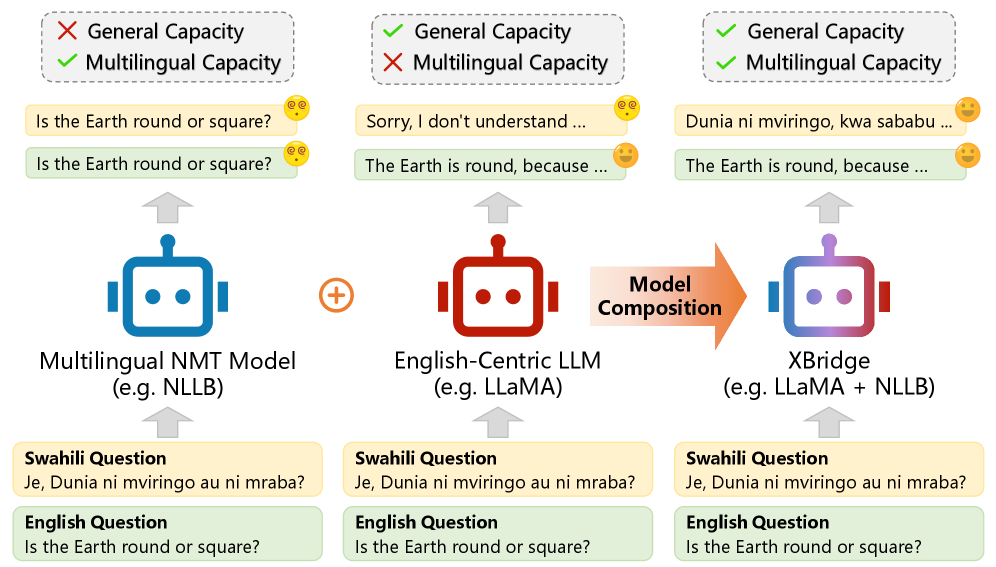
- XBridge : Pretrained multilingual NMT (Neural Machine Translation) 모델과 LLM (Large Language Model)을 통합하여 다국어 이해 및 생성을 외부 모델로 오프로드하고, LLM은 영어 중심의 지식 및 추론 코어로 유지하는 합성(compositional) 프레임워크입니다.
- LLMs (Large Language Models) : 일반적인 지능과 추론 능력을 나타내는 대규모 언어 모델을 지칭하며, 본 논문에서는 다국어 성능 불균형 문제를 겪는 모델을 의미합니다.
- Encoder-Decoder Translation Models : 다국어 이해 및 생성에 특화된 사전 학습된 인코더-디코더 기반 신경망 기계 번역 모델을 의미합니다.
- Optimal Transport (OT)-based Alignment : 모델 간의 이질적인 토큰화 및 표현 공간으로 인해 발생하는 의미적 불일치를 해결하기 위해 LLM-디코더 인터페이스에서 미세한 의미 일관성을 부여하는 정렬 기법입니다.
- Cross-Model Mapping Layers : 다국어 인코더와 LLM, 그리고 LLM과 다국어 디코더 간의 표현(representation) 간극을 연결하는 경량화된 레이어입니다.
- Extensible Multilinguality : 최소한의 추가 파라미터와 학습 데이터, 효율적인 학습을 통해 LLM의 다국어 기능을 저자원 및 이전에 보지 못한 언어(unseen languages)로 확장하는 능력을 의미합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
최근 Large Language Models (LLMs)은 뛰어난 일반 지능과 추론 능력을 보여주지만, 다국어 성능에서는 심각한 불균형을 보입니다. LLM이 상당한 교차 언어 지식(cross-lingual knowledge)을 통합된 semantic space에 인코딩하고 있음에도 불구하고, 저자원 또는 이전에 보지 못한 언어(unseen languages)와 이러한 지식을 안정적으로 연결하는 데 어려움을 겪습니다. 기존의 접근 방식들은 다국어 인코더를 통합하여 다국어 이해 능력을 향상시키지만, 생성 능력은 여전히 LLM의 영어 중심 언어 분포에 의해 제한되는 한계가 있었습니다. 또한, 사전 학습된 NMT 모델의 인코더와 디코더가 통일된 representation space 내에서 함께 학습되는 반면, 그 사이에 frozen LLM을 삽입하면 LLM의 입력 공간에서 내부 지식 처리로 형성된 다른 출력 공간으로의 변환이 발생하여 semantic misalignment를 초래합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 LLM의 다국어 확장을 위해 사전 학습된 multilingual NMT 모델과 LLM을 합성하는 XBridge 프레임워크를 제안합니다. XBridge는 encoder-LLM-decoder 아키텍처를 채택하며, multilingual encoder는 다국어 입력에 대한 robust semantic representation을 제공하고, frozen LLM은 지식 처리를 위한 영어 중심의 코어로 작동하며, multilingual decoder는 target language로 출력을 생성합니다 [Figure 1, 2]. 이 방법론은 모델 간의 이질적인 표현(heterogeneous representation) 공간을 명시적으로 정렬하여, frozen LLM 삽입으로 인한 semantic mismatch를 해결합니다. 이를 위해 경량화된 cross-model mapping layers 와 optimal transport (OT)-based alignment objective 를 도입하여 다국어 생성 시 fine-grained semantic consistency를 확보합니다.
안정적인 최적화를 위해 3단계 학습 전략 을 사용합니다
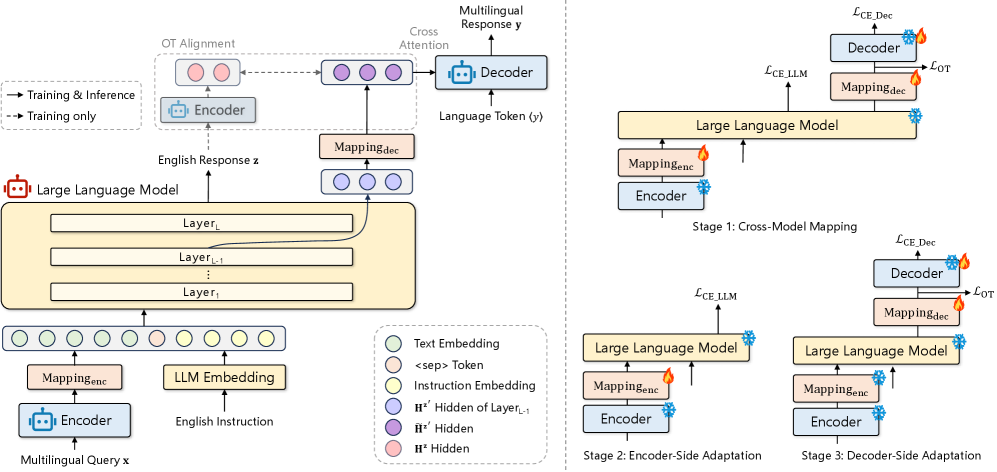
- Stage 1: Cross-Model Mapping : trilingual translation data를 사용하여 multilingual encoder, LLM, multilingual decoder 간의 coarse-grained semantic alignment를 확립합니다.
- Stage 2: Encoder-Side Adaptation : task-specific instruction data를 통해 LLM이 multilingual representation을 사용하여 작업을 수행하도록
Mapping_enc를 fine-tune합니다. - Stage 3: Decoder-Side Adaptation : multilingual generation 품질 향상을 위해
Mapping_dec와 decoder cross-attention layers를 업데이트합니다.
실험 결과, XBridge는 4개의 LLM (MetaMath-7B, LLaMA3-8B, Aya-23-8B, Qwen2.5-7B-Instruct)에 걸쳐 다국어 이해, 추론, 요약 및 생성 태스크에서 강력한 baseline들을 능가하는 성능 을 보였습니다. 특히, 저자원 및 이전에 보지 못한 언어 에서 LLM의 핵심 기능을 저해하지 않으면서 상당한 성능 향상을 달성했습니다. FLORES-101 벤치마크에서는 XBridge가 multilingual understanding 및 generation 성능을 크게 향상시키며 외부 NLLB-200-1.3B 모델에 근접한 결과를 보여주었습니다 [Table 1]. MGSM 에서의 multilingual reasoning accuracy는 XBridge의 LLM 출력과 decoder 출력 모두 영어 LLM 출력에 필적하는 정확도를 달성하여, 디코더가 추론 내용을 언어 전반에 걸쳐 충실하게 표현할 수 있음을 입증했습니다
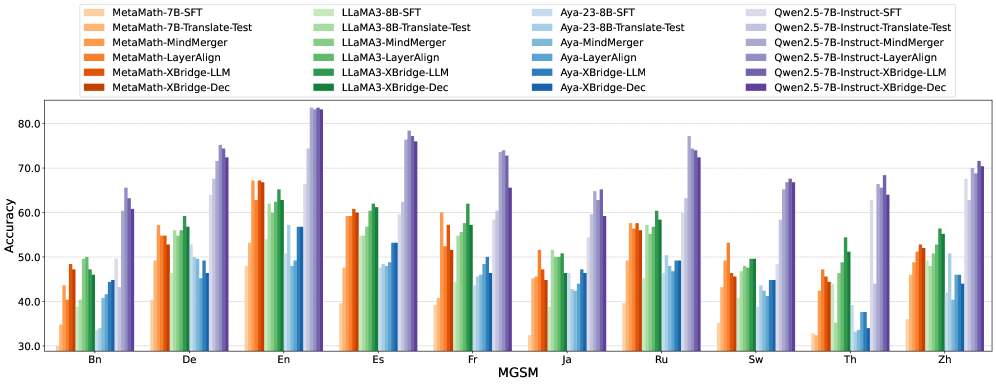
XL-Sum 에서는 XBridge가 encoder-augmented baseline보다 지속적으로 우수하며, SFT baseline보다 더 나은 평균 성능을 보여주었습니다 [Figure 3]. 또한, OT alignment 가 이질적인 표현 공간 간의 토큰 수준 정렬에 중요한 역할을 하며, 제거 시 다국어 생성 성능이 저하됨을 ablation study를 통해 확인했습니다 [Figure 4]. XBridge는 최소한의 추가 파라미터와 제한된 학습 데이터만으로 LLM을 재학습하지 않고도 저자원 및 이전에 보지 못한 언어의 성능을 외부 NMT 모델 수준으로 끌어올려 언어 간 격차를 크게 줄였습니다.
4. Conclusion & Impact (결론 및 시사점)
본 논문에서는 LLM의 multilingual capability를 외부 encoder-decoder NMT 모델로 오프로드하고 LLM을 영어 중심의 지식 처리 코어로 유지하는 XBridge 라는 합성 프레임워크를 제안합니다. 광범위한 실험을 통해 XBridge는 LLM의 핵심 능력을 손상시키지 않으면서 저자원 및 이전에 보지 못한 언어에 대한 성능을 외부 NMT 모델 수준으로 끌어올려 효율적인 다국어 확장을 가능하게 함을 입증했습니다. 이 연구는 대규모 다국어 사전 학습이나 LLM의 fine-tuning에 드는 비용 없이도 multilingual LLM을 개발할 수 있는 parameter-efficient한 솔루션을 제공하여, 학계 및 산업계에서 보다 접근하기 쉽고 확장 가능한 다국어 AI 시스템 구축에 중요한 시사점을 줍니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Smaller Models are Natural Explorers for Policy-Level Diversity in GRPO
- [논문리뷰] End-to-End Context Compression at Scale
- [논문리뷰] Domain-Specific Data Synthesis for LLMs via Minimal Sufficient Representation Learning
- [논문리뷰] Geometry-Aware Image Flow Matching
- [논문리뷰] You Only Need Minimal RLVR Training: Extrapolating LLMs via Rank-1 Trajectories
Review 의 다른글
- 이전글 [논문리뷰] Hyperagents
- 현재글 : [논문리뷰] Language on Demand, Knowledge at Core: Composing LLMs with Encoder-Decoder Translation Models for Extensible Multilinguality
- 다음글 [논문리뷰] LoopRPT: Reinforcement Pre-Training for Looped Language Models
댓글