[논문리뷰] ShotStream: Streaming Multi-Shot Video Generation for Interactive Storytelling
링크: 논문 PDF로 바로 열기
Part 1: 요약 본문
저자: Yawen Luo, Xiaoyu Shi, Junhao Zhuang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Multi-shot Video Generation : 다양한 장면 전환을 통해 일관된 서사를 유지하며 여러 개의 쇼트를 연속적으로 생성하는 비디오 생성 기술.
- Causal Architecture : 이전 쇼트 또는 프레임에만 조건화하여 다음 쇼트 또는 프레임을 순차적으로 생성하는 아키텍처로, 실시간 상호작용과 낮은 Latency를 가능하게 함.
- Distribution Matching Distillation (DMD) : 느리고 다단계(multi-step)의 Diffusion Model을 빠르고 소단계(few-step)의 Student Generator로 증류하여 고품질을 유지하면서 생성 속도를 향상시키는 기법.
- Self Forcing : Autoregressive Video Generation에서 Training-Test Gap으로 인한 Error Accumulation을 완화하기 위해, 훈련 시 Ground-Truth 데이터 대신 이전에 자체 생성된 출력을 조건으로 사용하는 학습 패러다임.
- Dual-Cache Memory Mechanism : Inter-shot Consistency를 위한 Global Context Cache와 Intra-shot Consistency를 위한 Local Context Cache를 포함하는 메모리 메커니즘으로, 시각적 일관성을 유지.
- RoPE Discontinuity Indicator : Dual-Cache Memory Mechanism에서 Global Context와 Local Context 간의 Temporal Ambiguity를 해소하기 위해, 각 Shot Boundary에 Discrete Temporal Jump를 도입하여 두 캐시를 명시적으로 구분하는 전략.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
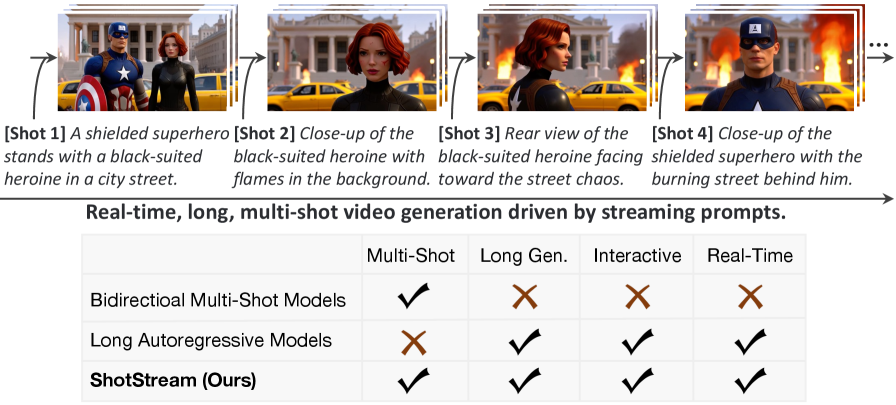
최근 Text-to-Video Model들은 단일 쇼트(single-shot) 비디오 생성에서 높은 성능을 보이지만, 영화나 TV와 같은 긴 서사적 스토리텔링(Long-form Narrative Storytelling)을 위해서는 Multi-shot Video Generation 이 필수적입니다. 기존 Multi-shot Video Generation 방법론들은 주로 Bidirectional Architecture에 의존하여 Temporal 및 Narrative Consistency를 확보합니다. 그러나 이러한 Bidirectional Architecture는 두 가지 주요 한계를 가집니다: 첫째, Interactivity 부족 으로 인해 전체 Multi-shot Sequence를 한 번에 생성해야 하며, 실시간 Streaming Prompt 입력을 통한 상호작용적인 내러티브 조절이 어렵습니다. 둘째, Context Length에 비례하여 Quadratic하게 증가하는 Bidirectional Attention의 계산 비용 때문에 높은 Latency 를 보입니다. 예를 들어, HoloCine 은 240프레임 Multi-shot Video 생성에 약 25분 이 소요됩니다. 저자들은 이러한 기존 방법론의 한계를 극복하고, 사용자가 Streaming Prompt를 통해 동적으로 내러티브를 지시하며 효율적인 On-the-fly Frame Generation을 가능하게 하는 새로운 Causal Multi-shot Architecture의 필요성을 제기합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 기존 Multi-shot Synthesis 태스크를 과거의 Context에 조건화된 Next-shot Generation으로 재정의하여 ShotStream이라는 새로운 Causal Multi-shot Architecture 를 제안합니다 [cite: 1, Figure 2]. 이 방법론은 크게 두 단계로 진행됩니다. 첫째, Text-to-Video Model을 Fine-tuning하여 Bidirectional Next-Shot Teacher Model을 구축합니다. 이 Teacher Model은 수백 프레임의 과거 Shot 정보를 모두 유지하는 대신, Dynamic Sampling Strategy 를 통해 Sparse Context Frames만을 활용하여 Temporal Redundancy를 줄이고 메모리 효율성을 높입니다. 또한, Conditional Context Frames의 Caption과 Target Frames의 Caption을 모두 Cross-attention을 통해 주입하여 In-context Learning 능력을 향상시킵니다 [cite: 1, Figure 3].
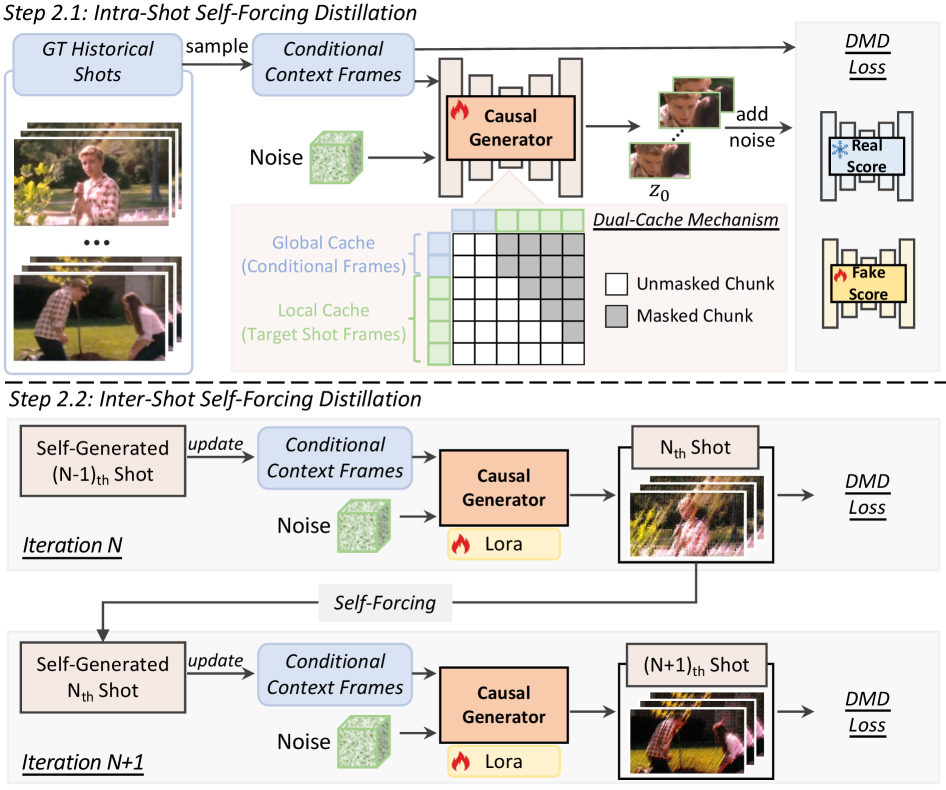
둘째, 이 느린 Multi-step Bidirectional Teacher Model을 Distribution Matching Distillation (DMD) 을 통해 효율적인 4-step Causal Student Model 로 증류합니다 [cite: 1, Figure 4]. Causal Architecture로의 전환 시 발생하는 두 가지 주요 도전 과제인 Inter-shot Consistency 유지와 Autoregressive Generation 과정에서의 Error Accumulation 방지를 위해 두 가지 핵심 혁신을 도입합니다.
- Dual-Cache Memory Mechanism : Global Context Cache는 Inter-shot Consistency를 위해 Sparse Conditional Historical Frames를 저장하고, Local Context Cache는 Intra-shot Consistency를 위해 현재 Shot 내에서 생성된 Frames를 유지합니다. 두 캐시 간의 Temporal Ambiguity를 해소하기 위해 RoPE Discontinuity Indicator 를 도입하여 Shot Boundary에서 Discrete Temporal Jump를 발생시킴으로써 Global 및 Local Context를 명시적으로 분리합니다 [cite: 1, Figure 4].
- Two-Stage Distillation Strategy : Training-Test Gap으로 인한 Error Accumulation을 완화하기 위해 Intra-shot Self-forcing과 Inter-shot Self-forcing으로 구성된 Progressive Distillation 전략을 제안합니다 [cite: 1, Figure 4]. 첫 번째 단계인 Intra-shot Self-forcing 에서는 Ground-Truth Historical Shots에 조건화하여 Current Shot을 Chunk-by-chunk으로 생성하며 기본적인 Next-shot Generation 능력을 확립합니다. 두 번째 단계인 Inter-shot Self-forcing 에서는 자체 생성된 과거 Shot들을 조건으로 사용하여 Multi-shot Video를 Shot-by-shot으로 생성함으로써 Inference 시나리오를 모방하고 Train-Test Gap을 효과적으로 줄입니다 [cite: 1, Figure 4].
실험 결과, ShotStream은 단일 NVIDIA H200 GPU 에서 16 FPS 의 효율적인 속도로 길고 서사적으로 일관된 Multi-shot Video를 생성합니다 [cite: 1, Figure 1]. 정량적 평가에서 ShotStream은 Visual Consistency, Prompt Adherence, Shot Transition Control 등 주요 지표에서 기존 방법론들을 능가하는 State-of-the-art 성능을 달성했습니다 [cite: 1, Table 1]. 특히 Bidirectional Model 대비 25배 이상의 Throughput 개선 을 보였습니다. 사용자 연구(User Study)에서도 54명의 참가자 중 87.69% 가 ShotStream의 Visual Consistency를, 76.15% 가 Prompt Following을, 83.08% 가 Visual Quality를 선호하여 주관적 평가에서도 우위를 입증했습니다 [cite: 1, Table 2, Figure 5].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 인터랙티브한 긴 서사적 스토리텔링을 가능하게 하는 새로운 Causal Multi-shot Video Generation Architecture인 ShotStream 을 소개합니다. ShotStream은 Multi-shot Synthesis를 Streaming Next-shot Generation 태스크로 재정의하고, Bidirectional Teacher Model을 훈련한 후 이를 효율적인 Causal Architecture로 증류하는 Two-stage Distillation Strategy 를 제안합니다. 또한, Dual-Cache Memory Mechanism 과 RoPE Discontinuity Indicator 를 통해 Inter-shot 및 Intra-shot Visual Consistency를 효과적으로 확보합니다. 이 연구는 기존 Bidirectional Multi-shot Model들의 높은 Latency와 Interactivity 부족 문제를 해결하며, Single GPU에서 16 FPS 의 속도를 달성하여 실시간 Interactive Storytelling의 가능성을 열었습니다. ShotStream은 Autoregressive Long Video Generation Model의 Multi-shot Sequence 생성 능력을 확장함으로써, 해당 분야의 학계 및 산업계에 실시간, 인터랙티브, 장편 스토리텔링의 새로운 방향을 제시하는 중요한 시사점을 가집니다.

⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] MV-Forcing: Long Multi-View Video Generation via 4D-Grounded Spatio-Temporal Self-Forcing
- [논문리뷰] AAD-1: Asymmetric Adversarial Distillation for One-Step Autoregressive Video Generation
- [논문리뷰] INSPATIO-WORLD: A Real-Time 4D World Simulator via Spatiotemporal Autoregressive Modeling
- [논문리뷰] Solaris: Building a Multiplayer Video World Model in Minecraft
- [논문리뷰] Context Forcing: Consistent Autoregressive Video Generation with Long Context
Review 의 다른글
- 이전글 [논문리뷰] RealChart2Code: Advancing Chart-to-Code Generation with Real Data and Multi-Task Evaluation
- 현재글 : [논문리뷰] ShotStream: Streaming Multi-Shot Video Generation for Interactive Storytelling
- 다음글 [논문리뷰] Sommelier: Scalable Open Multi-turn Audio Pre-processing for Full-duplex Speech Language Models
댓글