[논문리뷰] RealChart2Code: Advancing Chart-to-Code Generation with Real Data and Multi-Task Evaluation
링크: 논문 PDF로 바로 열기
The paper "RealChart2Code: Advancing Chart-to-Code Generation with Real Data and Multi-Task Evaluation" introduces a new benchmark for evaluating Vision-Language Models (VLMs) in generating code for complex, multi-panel visualizations from real-world data.
First, I need to extract the author information. Authors: Jiajun Zhang, Yuying Li, Zhixun Li, Xingyu Guo, Jingzhuo Wu, Leqi Zheng, Yiran Yang, Jianke Zhang, Qingbin Li, Shannan Yan, Zhetong Li, Changguo Jia, Junfei Wu, Zilei Wang, Qiang Liu, Liang Wang. Some authors have asterisks, indicating "Equal contribution". For the summary, I will list the first few authors and then "et al." as requested.
Keywords: Chart-to-Code Generation, Vision-Language Models, Multi-Task Evaluation, Real-World Data, Code Refinement, Data Visualization, Benchmark.
Now, I will go through the sections as requested:
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- Vision-Language Models (VLMs) : 이미지와 텍스트를 동시에 이해하고 처리할 수 있는 인공지능 모델로, 본 논문에서는 차트 이미지로부터 시각화 코드를 생성하는 능력을 평가한다.
- Chart-to-Code Generation : 주어진 차트 이미지(visualization)를 정확히 재현하는 프로그래밍 코드(Python Matplotlib 등)를 생성하는 태스크를 의미한다. 이는 사용자가 원본 코드가 없는 상황에서 차트를 편집, 확장 또는 재사용할 수 있도록 돕는다.
- Multi-turn Conversational Setting : 모델이 초기 생성된 코드의 오류를 사용자의 피드백을 통해 반복적으로 수정하고 개선하는 과정을 평가하는 상호작용적 환경을 지칭한다. 이는 RealChart2Code 벤치마크의 Chart Refinement 태스크에 해당한다.
- Real-world Data : 기존 벤치마크에서 주로 사용되던 합성 데이터(synthetic data)나 단순화된 데이터와 달리, Kaggle과 같은 실제 오픈소스 저장소에서 수집된 대규모의 복잡하고 노이즈가 많은 데이터를 의미한다.
- Complexity Gap : 기존의 단순한 벤치마크에서 VLM이 높은 성능을 보이지만, RealChart2Code와 같이 복잡한 멀티패널 레이아웃과 실제 데이터를 다루는 태스크에서는 성능이 크게 하락하는 현상을 지칭한다.
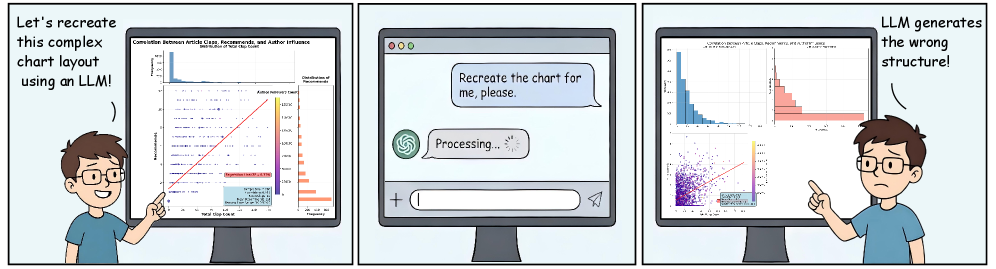
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) Vision-Language Models (VLMs)는 다양한 도메인에서 인상적인 코드 생성 능력을 보여주었지만, 복잡한 멀티패널 시각화를 실제 데이터로부터 재현하는 능력 은 아직 충분히 평가되지 않았다. 기존의 Chart-to-Code generation 벤치마크들은 주로 단순한 차트 유형과 단일 패널 레이아웃에 초점을 맞추었으며, 데이터 유출 위험이 있는 기존 차트-코드 쌍이나 과학 논문의 그림을 복제한 합성 데이터에 의존하는 경향이 있었다. 또한, 멀티턴 대화형 환경에서 코드 Refinement 능력을 평가하는 Metric이 부족하다는 한계가 있었다. Figure 1에서 볼 수 있듯이, 최신 VLM조차도 복잡한 멀티플롯 구조를 정확하게 재현하는 데 어려움을 겪고, 후속 Refinement 과정에서도 효과적인 개선을 이루지 못하는 문제가 발생한다. 이러한 문제점을 해결하고, LLM의 실제 환경에서의 Chart-to-Code 능력을 체계적으로 평가하기 위해 RealChart2Code 벤치마크가 필요하다.
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 저자들은 2,896개의 인스턴스로 구성된 새로운 대규모 벤치마크인 RealChart2Code 를 제안한다. 이 벤치마크는 실제 Kaggle 데이터셋을 기반으로 하며, 복잡한 차트 구조와 다양한 차트 유형을 포함한다. RealChart2Code는 다음 세 가지 주요 태스크를 통해 모델을 평가한다.
- Chart Replication : 차트 이미지로부터 시각화 코드를 역설계하여 VLM의 핵심 visual-to-code translation 능력을 측정한다

- Chart Reproduction : 차트 이미지, 원본 데이터, 메타데이터를 제공하여 대규모 실제 데이터를 사용하여 올바른 플롯을 생성하는 모델의 능력을 평가한다 [Figure 2].
- Chart Refinement : 미리 정의된 오류가 있는 차트를 멀티턴 대화를 통해 수정하도록 요구하여 반복적인 디버깅 능력을 평가한다 [Figure 2].
데이터 큐레이션 과정은 (1) Data Collection and Filtering, (2) Visualization Task Design, (3) Ground-Truth Code Implementation, (4) Error Injection의 4단계 파이프라인으로 구성된다. Kaggle에서 수집된 1,036개의 고품질 데이터셋을 기반으로 1,016개의 고유하고 복잡한 시각화를 설계하고, Matplotlib 및 관련 라이브러리를 사용하여 전문가들이 ground-truth 코드를 직접 구현했다. Chart Refinement 태스크를 위해 수동으로 다양한 유형의 오류를 주입하여 864개의 Refinement 태스크를 생성했다.
저자들은 5개의 proprietary 모델과 9개의 open-weight 모델을 포함한 총 14개 의 선도적인 VLM을 RealChart2Code 벤치마크에서 평가했다. 평가 결과, 기존의 단순한 벤치마크에서 높은 성능을 보였던 대부분의 모델들이 RealChart2Code에서는 상당한 성능 저하 를 겪는 것으로 나타났다. 특히, Claude-4.5-Opus 가 평균 점수 8.2 로 proprietary 모델 중 가장 높은 성능을 보였고, Gemini-3-Pro-Preview 가 8.1 로 뒤를 이었다 [Table 2]. 반면, open-source 모델 중 최고 성능을 보인 Qwen3-VL-235B 와 Intern-VL-3.5-241B 는 각각 3.6 및 3.4 점으로, 선두 proprietary 모델의 절반 이하의 점수를 기록하며 상당한 성능 격차(performance gap) 를 보였다 [Table 2]. 또한, 기존 벤치마크에서 Qwen3-VL-235B 가 75 이상의 높은 점수를 얻었음에도 불구하고 RealChart2Code에서는 3.6 으로 급격히 하락하는 현상이 관찰되었다. 이는 RealChart2Code가 모델의 복잡한 차트 구조 및 실제 대규모 데이터 처리 능력 을 효과적으로 구분함을 시사한다.
## 4. Conclusion & Impact (결론 및 시사점) 본 연구는 Vision-Language Models (VLMs)의 현실적이고 복잡한 데이터 시각화 태스크에 대한 체계적인 평가 부족 문제를 해결했다. 저자들은 실제 데이터셋을 기반으로 Chart Replication, Chart Reproduction, 그리고 Iterative Refinement 능력을 평가하는 대규모 벤치마크인 RealChart2Code 를 도입했다. 14개의 주요 모델에 대한 포괄적인 평가는 현재 LLM이 단순한 플로팅에는 능숙하지만, 복잡한 멀티패널 레이아웃과 실제 데이터를 다룰 때 심각한 성능 저하 를 겪는다는 것을 입증했다. 특히, proprietary 모델은 우수한 visual reasoning 능력을 보인 반면, open-weight 모델은 구문 오류(syntax errors) 및 공간 논리(spatial logic) 문제로 자주 어려움을 겪는다는 뚜렷한 capability gap 이 확인되었다. 이 연구는 VLM의 현재 한계에 대한 귀중한 통찰력을 제공하며, 복잡한 훈련 예제의 부족 문제를 해결하고 모델의 복잡한 레이아웃에 대한 일반화 능력을 향상시키기 위한 향후 연구 방향을 제시한다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] Sparse Delta Memory: Scaling the State of Linear RNNs through Sparsity
Review 의 다른글
- 이전글 [논문리뷰] PackForcing: Short Video Training Suffices for Long Video Sampling and Long Context Inference
- 현재글 : [논문리뷰] RealChart2Code: Advancing Chart-to-Code Generation with Real Data and Multi-Task Evaluation
- 다음글 [논문리뷰] ShotStream: Streaming Multi-Shot Video Generation for Interactive Storytelling
댓글