[논문리뷰] PackForcing: Short Video Training Suffices for Long Video Sampling and Long Context Inference
링크: 논문 PDF로 바로 열기
저자: Xiaofeng Mao, Shaohao Rui, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- PackForcing : 선형적인 KV-cache growth , temporal repetition , 그리고 compounding errors 와 같은 장시간 비디오 생성의 주요 제약 사항들을 해결하기 위해 고안된 통합 프레임워크로, 새로운 three-partition KV-cache 전략을 기반으로 한다.
- Three-partition KV-cache : 생성 이력을 Sink tokens , Compressed Mid tokens , Recent tokens 의 세 가지 distinct한 유형으로 분류하여 효율적인 메모리 관리와 일관성 유지를 목표로 하는 전략이다.
- Sink tokens : 초기에 생성된 anchor frames 를 full resolution 으로 유지하여 global semantics 를 보존하고 semantic drift 를 방지하는 역할을 하는 토큰이다.
- Compressed Mid tokens : Sink tokens 와 Recent tokens 사이에 존재하는 대다수의 비디오 이력을 나타내며, dual-branch network 를 통해 약 32x 의 spatiotemporal compression 을 달성하여 메모리 사용량을 대폭 줄인다.
- Recent tokens : 가장 최근에 생성된 프레임들을 full resolution 으로 유지하여 local temporal coherence 와 높은 fidelity 를 보장하는 토큰이다.
- Dual-branch HR Compression : Mid tokens 의 massive token reduction 을 위해 제안된 모듈로, progressive 3D convolutions 를 사용하는 HR branch 와 low-resolution VAE re-encoding 을 사용하는 LR branch 를 융합하여 구조적 및 의미적 정보를 효율적으로 보존한다.
- Temporal RoPE Adjustment : KV cache 에서 토큰이 드롭될 때 발생하는 positional discontinuities 를 multiplicative RoPE properties 를 활용하여 negligible overhead 로 seamlessly 재정렬하는 메커니즘이다.
- Dynamic Context Selection : Query-key affinity 를 기반으로 가장 정보 가치가 높은 Compressed Mid tokens 를 non-destructive 방식으로 동적으로 선택하여 subject consistency 를 향상시키는 전략이다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
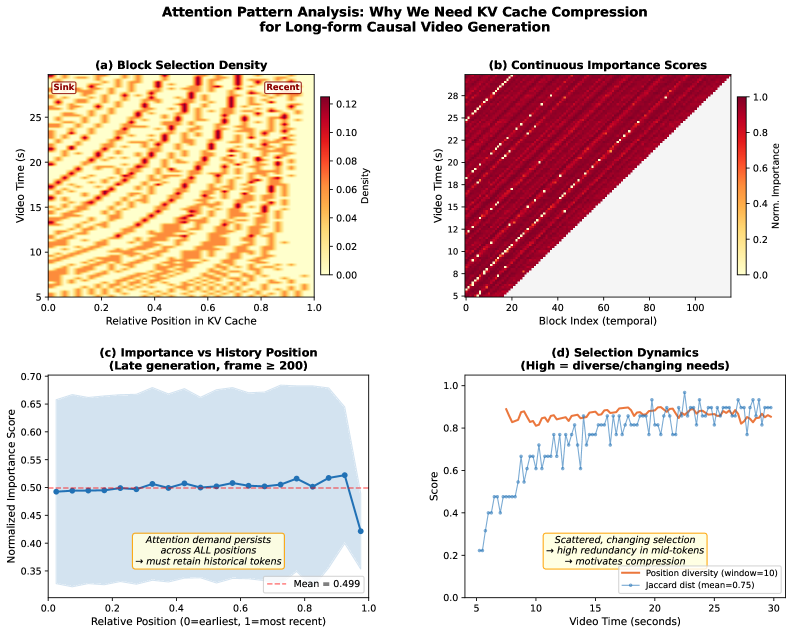
최근 autoregressive video diffusion models 는 상당한 발전을 이루었지만, 장시간 비디오 생성 시 발생하는 몇 가지 주요 제약 사항들에 직면해 있다. 첫째, KV-cache 의 선형적인 메모리 증가는 2분 길이의 832x480 비디오 생성 시 약 138 GB 에 달하는 KV storage 를 요구하며, 이는 단일 GPU 의 메모리 용량을 초과한다. 둘째, autoregressive denoising process 중 발생하는 작은 예측 오류들이 누적되어 progressive quality degradation 및 semantic drift 를 유발한다. 기존 연구들, 예를 들어 Self-Forcing 은 self-generated historical frames 를 통해 이를 완화하려 시도했지만, training horizon 을 넘어서는 경우 심각한 error accumulation 문제를 겪는다. 이는 60초 내에 CLIP score 가 33.89 에서 27.12 로 하락하는 것으로 나타났다.
DeepForcing 과 같은 최신 baseline 들도 attention sinks 와 participative compression 을 도입하여 중요한 토큰을 유지하지만, 결국 aggressive buffer truncation 에 의존하여 중간 이력 정보를 비가역적으로 손실한다. 이러한 기존 방법들은 long-range coherence 를 심각하게 손상시키는 한계를 가진다. 따라서 autoregressive video generation 에서는 error accumulation 을 완화하기 위해 광범위한 contextual history 를 유지해야 하지만, unbounded KV cache growth 로 인해 하드웨어 제약 하에서 중요한 메모리를 폐기해야 하는 근본적인 딜레마가 발생한다. Strictly bound 된 KV cache size 를 유지하면서도 large effective context window 를 확보하는 것이 중요한 미해결 문제로 남아있다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 error accumulation 과 unbounded memory growth 라는 두 가지 문제를 해결하기 위해 PackForcing 이라는 통합 프레임워크를 제안한다. PackForcing 의 핵심은 혁신적인 three-partition KV-cache 전략으로, 생성 이력을 Sink tokens , Compressed Mid tokens , Recent tokens 세 가지 기능적 파티션으로 분리한다
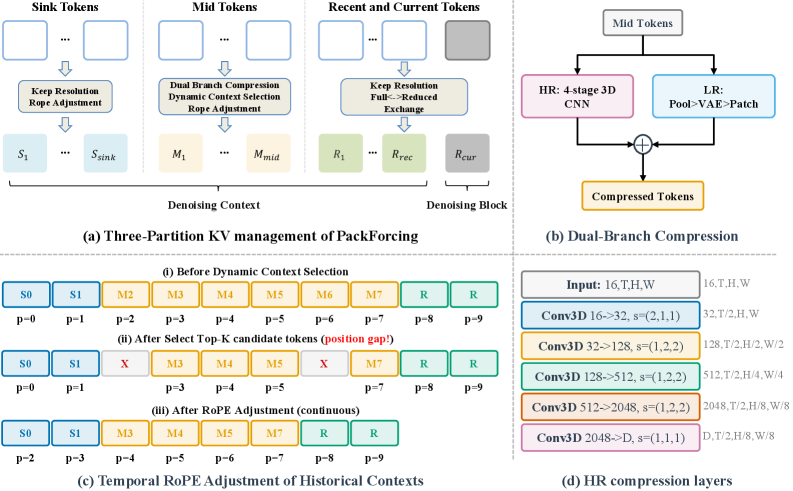
- Sink tokens : 초기 8 frames (
Nsink=8)를 full resolution 으로 유지하여 global semantics 를 앵커링하고 semantic drift 를 방지한다. 이 토큰들은 압축되거나 제거되지 않는다. - Compressed Mid tokens : 대부분의 비디오 이력을 담당하며, dual-branch HR compression 모듈을 통해 massive spatiotemporal compression (
~32xtoken reduction )을 수행한다 [Figure 2]. 이 모듈은 progressive 3D convolutions 를 사용하는 HR branch 와 low-resolution VAE re-encoding 을 사용하는 LR branch 의 출력을 element-wise addition 으로 융합하여, 6,240 개의 오리지널 토큰을 182 개의 압축된 토큰으로 줄인다. - Recent tokens : 현재 생성 중인 블록과 가장 최근 4 frames (
Nrecent=4)를 full resolution 으로 유지하여 local temporal coherence 를 보장한다. 이는 dual-resolution shifting pipeline 을 통해 compression overhead 없이 mid-buffer 로의 원활한 전환을 숨긴다.
메모리 footprint를 엄격하게 제한하면서도 품질 저하를 막기 위해, PackForcing 은 Dynamic Context Selection 과 Incremental RoPE Adjustment 를 도입한다. Dynamic Context Selection 은 query-key affinity 를 기반으로 가장 정보 가치가 높은 top-K (Ntop=16) mid-blocks 를 선택하여 subject consistency 를 +0.8 , overall CLIP score 를 +0.12 향상시킨다. 이는 FIFO eviction 방식보다 우수한 성능을 보인다. Incremental RoPE Adjustment 는 토큰 삭제로 인한 positional discontinuities 를 negligible overhead (0.1% 미만의 추론 시간)로 해결하며, CLIP score 하락을 2.53 에서 0.95 로 62% 감소시킨다.
실험 결과, PackForcing 은 5초 클립으로만 훈련되었음에도 불구하고 24x temporal extrapolation (5s → 120s)을 달성하며 coherent 2-minute , 832x480 비디오를 16 FPS 로 단일 H200 GPU에서 생성할 수 있다. KV cache 는 비디오 길이에 관계없이 약 4 GB 로 bound 된다. VBench 평가에서 PackForcing 은 Dynamic Degree 에서 56.25 (60초) 및 54.12 (120초)로 다른 모든 baseline 들을 능가하며, CausVid 대비 각각 +7.82 , +4.12 의 우위를 보인다 [Table 1]. Long-range consistency 측면에서는 60초 생성 동안 CLIP score 가 34.04 에서 32.90 으로 단 1.14 점 하락하여 가장 높은 alignment 를 유지한다 [Table 2]. 이는 Self-Forcing 의 6.77 점 하락에 비해 훨씬 안정적이다 [Table 2]. 이러한 정량적 결과는 PackForcing 이 short-video supervision 만으로 high-quality , long-video synthesis 에 충분함을 입증한다.
4. Conclusion & Impact (결론 및 시사점)
본 논문에서 저자들은 autoregressive video generation 에서 error accumulation 및 unbounded memory growth 라는 이중 병목 현상을 근본적으로 해결하는 통합 프레임워크인 PackForcing 을 소개한다. PackForcing 은 KV cache 를 sink , compressed mid , 그리고 recent tokens 로 전략적으로 분할함으로써, 메모리 footprint 를 약 4 GB 로 엄격하게 bound 하고 essential historical context 를 폐기하지 않으면서 constant-time attention complexity 를 보장한다.
128x 의 dual-branch compression module (약 32x token reduction ), incremental RoPE adjustments , 그리고 dynamic context selection 기술들을 통해, PackForcing 은 5초 훈련 클립에서 120초 비디오 생성으로의 놀라운 24x temporal extrapolation 을 달성한다. 이는 short-video supervision 이 high-quality , long-video synthesis 에 충분하다는 것을 명확히 입증한다. 궁극적으로 PackForcing 은 매우 coherent 2-minute videos 를 생성하며, 기존 baseline 들 사이에서 state-of-the-art VBench scores 와 가장 강력한 text-video alignment 를 확립한다

이 연구는 표준 하드웨어에서 효율적이고 unbounded video generation 의 길을 열어, 비디오 생성 연구 및 실제 응용 분야에 지대한 영향을 미칠 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] FadeMem: Distance-Aware Memory Consolidation for Autoregressive Video Diffusion
- [논문리뷰] RealMaster: Lifting Rendered Scenes into Photorealistic Video
- [논문리뷰] VideoSSM: Autoregressive Long Video Generation with Hybrid State-Space Memory
- [논문리뷰] Infinity-RoPE: Action-Controllable Infinite Video Generation Emerges From Autoregressive Self-Rollout
- [논문리뷰] Flex-Forcing: Towards a Unified Autoregressive and Bidirectional Video Diffusion Model
Review 의 다른글
- 이전글 [논문리뷰] Out of Sight but Not Out of Mind: Hybrid Memory for Dynamic Video World Models
- 현재글 : [논문리뷰] PackForcing: Short Video Training Suffices for Long Video Sampling and Long Context Inference
- 다음글 [논문리뷰] RealChart2Code: Advancing Chart-to-Code Generation with Real Data and Multi-Task Evaluation
댓글