[논문리뷰] Out of Sight but Not Out of Mind: Hybrid Memory for Dynamic Video World Models
링크: 논문 PDF로 바로 열기
저자: Kaijin Chen, Dingkang Liang, Xin Zhou, Yikang Ding, Xiaoqiang Liu, Pengfei Wan, Xiang Bai
1. Key Terms & Definitions (핵심 용어 및 정의)
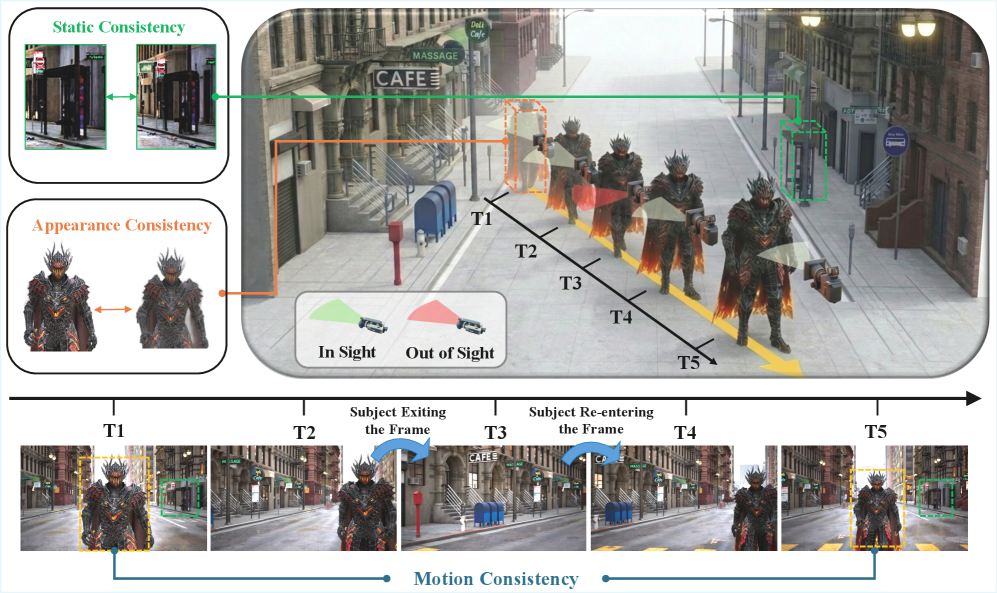
- Hybrid Memory : 비디오 월드 모델에서 정적인 배경의 일관성을 유지하면서, 동시에 화면 밖으로 사라졌다가 다시 나타나는 동적인 Subject(피사체)의 움직임 및 외형 일관성을 예측하고 유지하는 능력.
- HM-World : Hybrid Memory 연구를 위해 특별히 구축된 대규모 비디오 데이터셋으로, 59K개의 고화질 클립과 분리된 카메라 및 Subject 궤적, 그리고 Subject의 Exit-Entry 이벤트가 특징이다.
- HyDRA (Hybrid Dynamic Retrieval Attention) : 숨겨진 Subject를 찾고 Dynamic Consistency를 보존하기 위해 제안된 Specialized Memory Architecture. Memory Latent를 Memory Token으로 압축하고 Spatiotemporal Relevance-Driven Retrieval Mechanism을 활용한다.
- Memory Tokenizer : Memory Latent를 Spatiotemporal 정보를 포함하는 Compact Memory Token으로 변환하는 3D Convolution-based 모듈.
- Dynamic Subject Consistency (DSC) : 동적인 Subject의 움직임 및 외형 일관성을 정량적으로 평가하기 위해 제안된 새로운 Metric. 예측된 비디오, GT 비디오, Context 비디오에서 Subject 영역을 Crop한 후 CLIP Feature 유사도를 계산하여
DSC_GT와DSC_ctx두 가지 Score를 산출한다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Video World Models는 물리적인 세계를 시뮬레이션하는 데 막대한 잠재력을 보여주지만, 기존 Memory Mechanism들은 환경을 주로 Static Canvas로 간주하는 한계를 가지고 있다. 이로 인해 동적인 Subject가 화면 밖으로 사라졌다가 다시 나타날 때, 기존 방법들은 Subject가 Frozen되거나 Distorted되거나 혹은 완전히 Vanishing되는 문제에 직면한다. 기존 연구들은 Memory Capacity를 Retrieval 및 Compression 기술을 통해 향상시켰지만, 대부분 정적인 환경이나 비교적 단순한 동적 환경에 최적화되어 있어 복잡한 동적 장면에서의 Hybrid Memory 능력은 부족하다. 특히 카메라 뷰포인트가 바뀌거나 장기적인 Extrapolation 상황에서 모델이 이전 Context를 잃어버려 일관성 없는 결과를 생성하는 문제가 두드러진다. 저자들은 이러한 한계를 극복하기 위해 Hybrid Memory라는 새로운 Paradigm을 제안하며, 이는 모델이 정적 배경의 일관성과 동적 Subject의 움직임 연속성을 동시에 유지하도록 요구한다. 이 새로운 Paradigm을 연구하고 검증하기 위해서는 이를 위한 특화된 데이터셋과 Memory Mechanism 설계가 필수적이다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 Hybrid Memory Paradigm을 해결하기 위해 HM-World 데이터셋과 HyDRA (Hybrid Dynamic Retrieval Attention) 아키텍처를 제안한다. HM-World 는 59K개의 고화질 비디오 클립으로 구성된 최초의 대규모 Hybrid Memory 전용 데이터셋이다. 이 데이터셋은 17개의 다양한 Scene, 49개의 Distinct Subject, 10가지 Subject Motion Path, 그리고 28가지 카메라 궤적을 포함하며, Subject의 Exit-Entry 이벤트를 유도하는 카메라 모션을 통해 Hybrid Coherence를 엄격하게 평가한다 [Figure 2, 3]. 특히, 카메라 궤적과 Subject 움직임을 Decouple하여 Subject가 화면 밖으로 나갔다가 다시 나타나는 자연스러운 인스턴스를 다수 포함한다.
제안하는 HyDRA 는 전체 시퀀스 비디오 Diffusion Model을 기반으로 하며, Causal 3D VAE와 Diffusion Transformer (DiT)로 구성된다
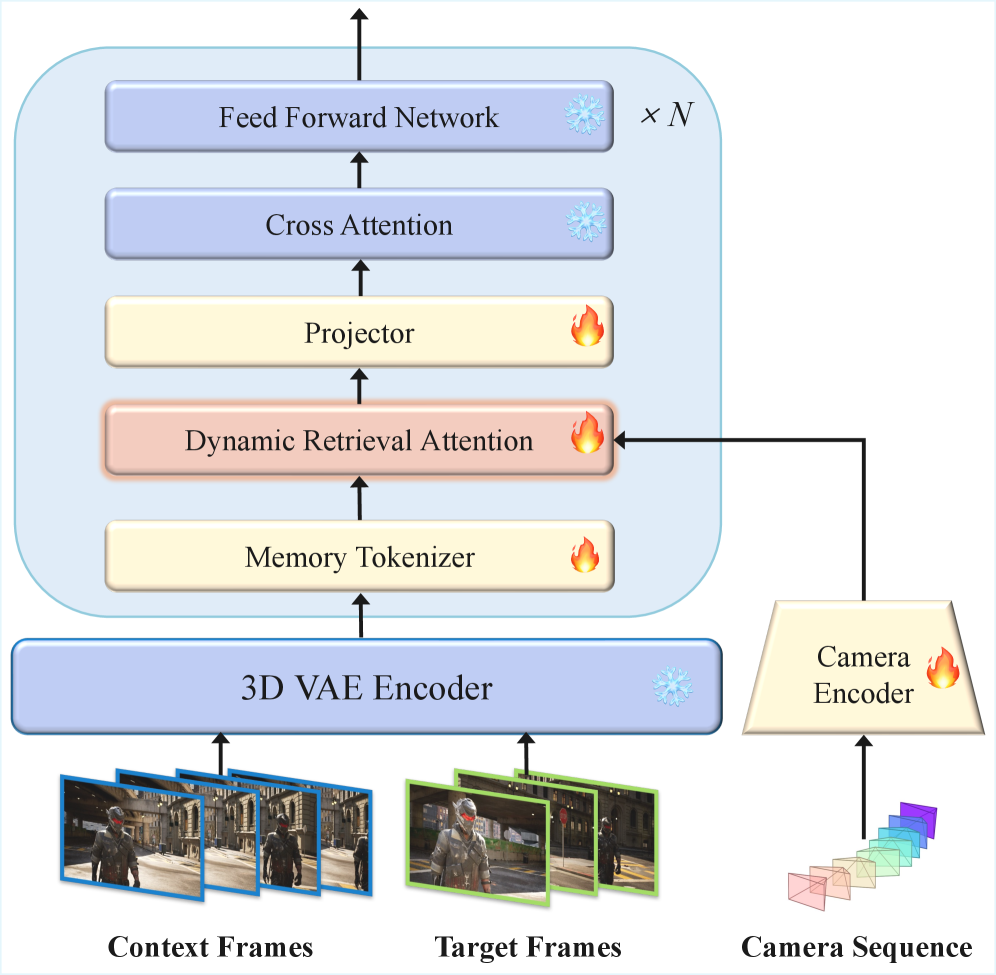
HyDRA 의 핵심은 Memory Tokenization 과 Dynamic Retrieval Attention 이다. Memory Tokenizer 는 3D Convolution을 사용하여 Memory Latent인 Z_mem을 M이라는 Compact Memory Token으로 변환한다 [Figure 5 (a)]. 이 과정을 통해 Spatiotemporal Receptive Field를 확장하여 장기적인 Motion Information을 캡처하고, Raw Latent에서 불필요한 노이즈를 필터링하면서 필수적인 Motion 및 Appearance Cues를 보존한다. Dynamic Retrieval Attention 은 Query와 Memory Token 간의 Spatiotemporal Affinity를 계산하여 가장 관련성 높은 Top-K개의 Memory Token을 선택적으로 검색한다 [Figure 5 (b)]. 특히, Query와 Memory Key의 Spatial Resolution 차이를 해결하기 위해 Query를 Downsample하고, Spatiotemporal Affinity S_i,j는 Element-wise Product를 통해 계산된다. 또한, Local Denoising Stability를 유지하기 위해 Query 자체의 Local Temporal Window를 Attention 계산에 포함시킨다.
HyDRA 는 HM-World 데이터셋에 대한 광범위한 실험에서 Baseline 및 State-of-the-Art 방법론들을 크게 능가하는 성능을 보였다 [Table 2]. 예를 들어, HyDRA 는 Baseline 대비 PSNR 을 18.696 에서 20.357 로, SSIM 을 0.517 에서 0.606 으로 향상시켰다. 또한, Dynamic Subject Consistency (DSC) Metric에서 DSC_ctx 0.827 , DSC_GT 0.849 를 달성하여 Subject Tracking 및 Appearance/Motion Consistency 유지 능력에서 탁월함을 입증했다. 이는 WorldPlay와 같은 최첨단 Commercial Model (PSNR 14.855 , DSC_GT 0.832 )과 비교했을 때도 모든 Metric에서 우수한 결과를 보여주었다 [Table 3]. Ablation Study를 통해 Memory Tokenizer 의 Temporal Interaction (PSNR에서 1.281 감소) 및 Dynamic Affinity Retrieval (Subject Consistency에서 0.908 에서 0.926 으로 향상)의 중요성도 확인되었다 [Table 4, 6].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Hybrid Memory라는 새로운 Paradigm을 제시하며, 비디오 월드 모델이 정적인 배경 일관성과 동적인 Subject 일관성을 Exit-Entry 이벤트 중에도 동시에 유지해야 하는 과제를 제기한다. 이러한 연구를 체계적으로 지원하기 위해 저자들은 최초의 대규모 Hybrid Memory 전용 비디오 데이터셋인 HM-World 를 구축했다. 또한, 이 도전적인 과제를 해결하기 위해 Motion 및 Appearance Cues를 효과적으로 추출하고 검색하여 일관성 있는 생성을 가능하게 하는 고급 Memory Architecture인 HyDRA 를 제안한다. 광범위한 실험을 통해 HyDRA 가 기존 방법론들을 크게 능가하는 성능을 보임을 입증했다. 저자들은 Hybrid Memory Paradigm과 HM-World 데이터셋, 그리고 HyDRA 프레임워크가 비디오 월드 모델 분야의 새로운 연구를 촉발하고 발전을 위한 견고한 기반을 제공할 것으로 기대한다. 향후 연구에서는 3개 이상의 Subject나 심한 Occlusion이 있는 복잡한 장면에서의 HyDRA 성능 저하를 개선하고, Unconstrained Real-world 환경으로 확장하는 방안을 모색할 예정이다.

⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] MemLearner: Learning to Query Context memory for Video World Models
- [논문리뷰] MBench: A Comprehensive Benchmark on Memory Capability for Video World Models
- [논문리뷰] Latent Spatial Memory for Video World Models
- [논문리뷰] StressDream: Steering Video World Models for Robust Policy Evaluation and Improvement
- [논문리뷰] minWM: A Full-Stack Open-Source Framework for Real-Time Interactive Video World Models
Review 의 다른글
- 이전글 [논문리뷰] Natural-Language Agent Harnesses
- 현재글 : [논문리뷰] Out of Sight but Not Out of Mind: Hybrid Memory for Dynamic Video World Models
- 다음글 [논문리뷰] PackForcing: Short Video Training Suffices for Long Video Sampling and Long Context Inference
댓글