[논문리뷰] Sommelier: Scalable Open Multi-turn Audio Pre-processing for Full-duplex Speech Language Models
링크: 논문 PDF로 바로 열기
저자: Kyudan Jung, Jihwan Kim, Soyoon Kim, Jeonghoon Kim, Jaegul Choo, Cheonbok Park
1. Key Terms & Definitions (핵심 용어 및 정의)
- SLMs (Speech Language Models) : Text-based LLMs에서 확장된 개념으로, 실시간으로 자연스러운 Human-Computer Interaction을 가능하게 하는 모델입니다.
- Full-duplex system : 시스템이 동시에 듣고 말할 수 있어, 보다 유동적이고 인간과 유사한 상호작용을 지원하는 시스템입니다. Cascaded ASR 및 TTS 파이프라인과 대비됩니다.
- Overlapping Speech : 두 명 이상의 화자가 동시에 발화하는 현상으로, 자연스러운 대화의 특징이나 Speech Processing에서 해결하기 어려운 과제입니다.
- Diarization : 오디오 스트림에서 '누가 언제 말했는지'를 식별하는 기술로, Multi-speaker conversational data 처리의 핵심 구성 요소입니다.
- ASR (Automatic Speech Recognition) Hallucinations : ASR 모델이 Silence 또는 Noisy segment에서 반복적이거나 무의미한 텍스트를 생성하는 오류 현상입니다.
- Sommelier : Full-duplex SLMs를 위한 고품질 학습 데이터를 큐레이션하기 위해 제안된 Scalable하고 Robust한 Open-source Data Processing Pipeline입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
AI 패러다임이 Text-based LLMs에서 Speech Language Models (SLMs)로 전환됨에 따라, 실시간의 자연스러운 Human-Computer Interaction을 지원하는 Full-duplex system 에 대한 수요가 증가하고 있습니다. 그러나 이러한 모델의 개발은 고품질의 Multi-speaker Conversational Data의 부족으로 제약을 받고 있습니다. 기존의 Large-scale 리소스는 주로 Single-speaker이거나 볼륨이 제한적입니다. Overlapping Speech 및 Back-channeling과 같은 자연스러운 대화의 복잡한 Dynamic을 처리하는 것이 큰 과제이며, 표준 Processing Pipeline은 Diarization Error 와 ASR Hallucinations 로 인해 어려움을 겪습니다. 이러한 문제점을 해결하고, Full-duplex 모델을 위한 Robust하고 Scalable한 데이터 Processing Pipeline이 절실히 필요한 상황입니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 Raw, In-the-wild Conversational Audio를 Full-duplex SLMs 학습에 적합한 고품질 데이터로 변환하는 Robust하고 Scalable한 Sommelier Pipeline을 제안합니다. 이 Pipeline은 Audio Standardization , VAD & Speaker Diarization , Handling Overlapping Speech , Background Music Removal , Ensemble-based ASR 의 모듈식 구성으로 이루어져 있습니다
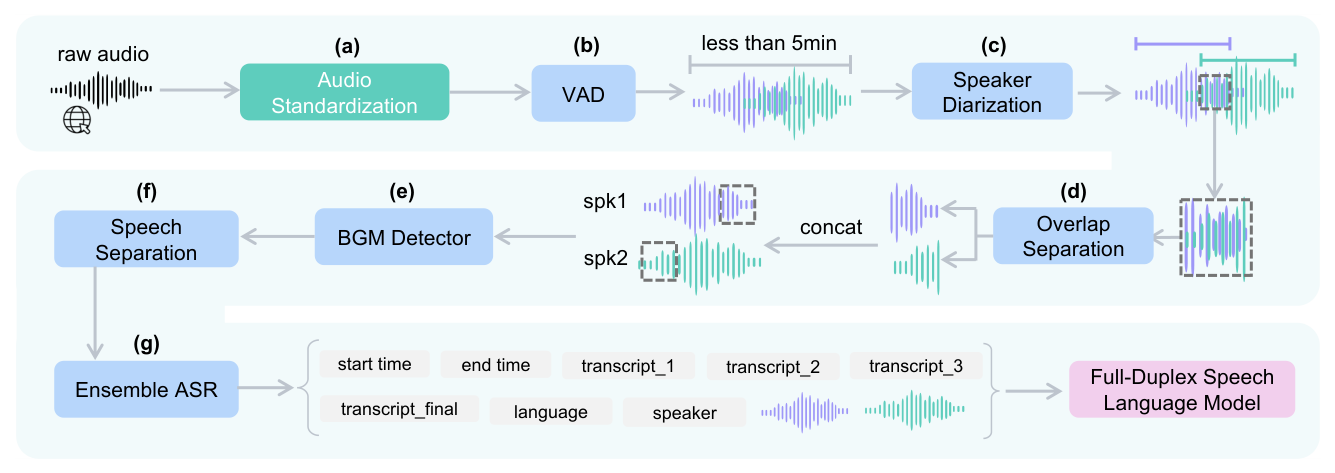
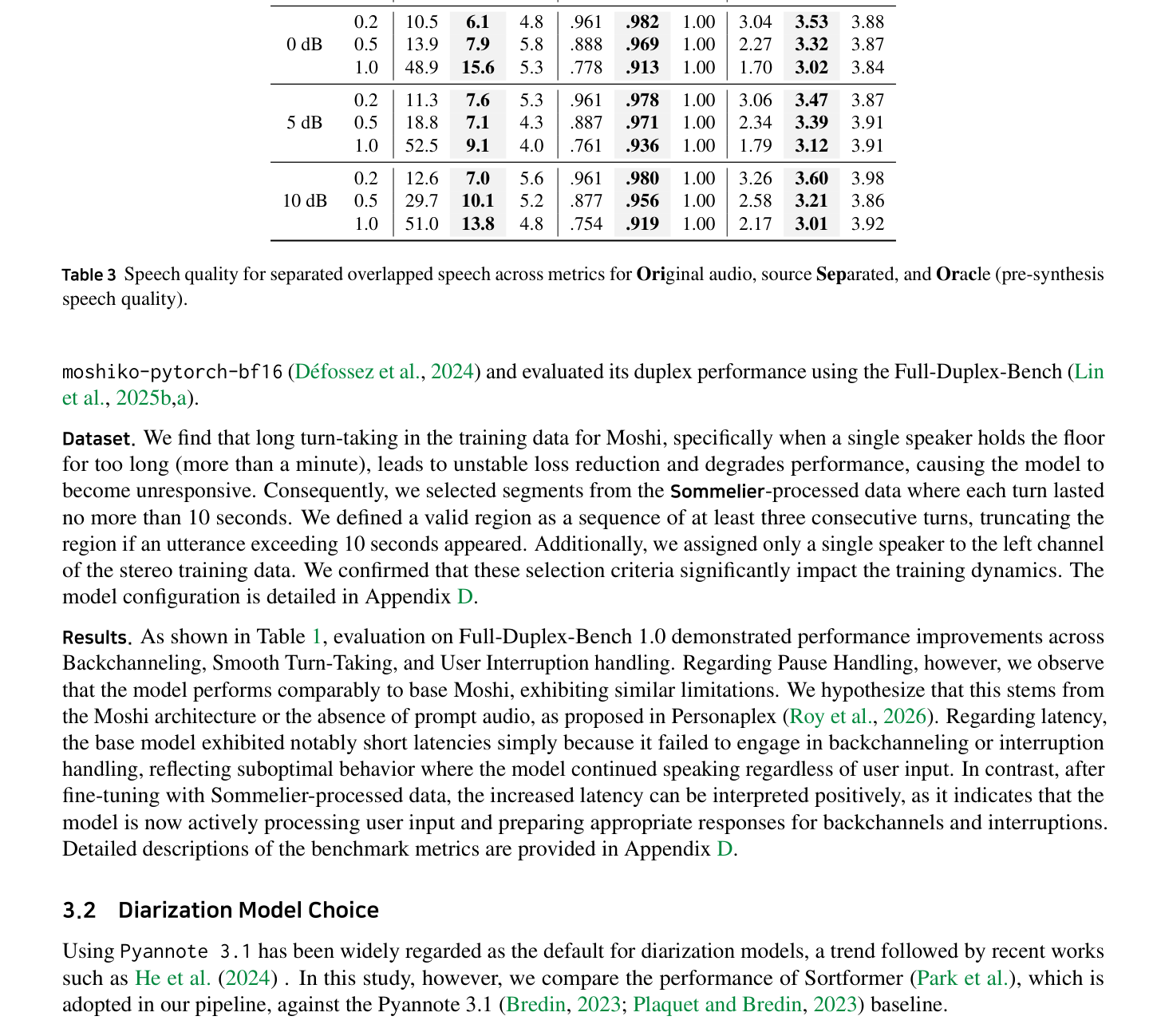
Diarization 에서는 Pyannote 3.1 대신 Sortformer 를 채택하여 Back-channeling과 같은 Very Short Utterance를 Robust하게 포착합니다. VoxConverse 벤치마크에서 Sortformer 는 Pyannote 3.1 대비 DER 에서 8.40% 에서 7.16% 로, JER 에서 17.68% 에서 14.69% 로 우수한 성능을 보였습니다 [Table 2]. Overlapping Speech 처리를 위해 SepReformer 기반의 Two-speaker Separation 모델을 사용하며, WER 측면에서 Sep 방식은 0 dB SIR 및 1.0 Overlap 조건에서 Speaker 2 의 WER 를 기존 0.444 에서 0.138 로 크게 개선했습니다. UTMOS 점수 또한 높은 Overlap Ratio 에서도 Oracle 수준에 근접하여 Intelligibility와 Naturalness를 유지함을 입증했습니다 [Table 3, Figure 3]. ASR Hallucinations 를 줄이기 위해 세 가지 SOTA 모델의 출력을 결합하는 Recognizer Output Voting Error Reduction (ROVER) Ensemble Strategy 를 사용하며, RepetitionFilter 를 통해 불필요한 N-gram 반복을 제거합니다. MoE (Ours) 모델은 LibriSpeech Test Clean 에서 Whisper 대비 WER 3.63% 에서 2.04% 로 향상된 성능을 보여주었습니다 [Table 4].
제안된 Pipeline으로 처리된 83시간 의 데이터를 사용하여 Moshi 모델을 Fine-tuning 한 결과, Full-Duplex-Bench 1.0 에서 Backchanneling , Smooth Turn-Taking , User Interruption Handling 성능이 크게 향상되었습니다

예를 들어, Backchanneling 의 TOR 는 Base Moshi 의 1.000 에서 Moshi+Sommelier 의 0.291 로 개선되었고, User Interruption 의 GPT-40 relevance score 는 0.765 에서 3.684 로 크게 증가했습니다. Pipeline의 총 Latency 는 120초 오디오 샘플에 대해 20.95초 이며, RTF 는 0.1746 으로 Scalability를 입증했습니다 [Table 5].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Full-duplex SLMs 를 위한 Robust하고 Scalable한 Open-source Data Processing Pipeline인 Sommelier 를 제안합니다. 이 Pipeline은 Multi-speaker Conversational Data의 부족과 복잡한 대화 Dynamics (Overlapping Speech, Back-channeling) 처리, Diarization Error , ASR Hallucinations 등의 핵심 과제를 해결합니다. Sommelier 를 통해 처리된 데이터로 Moshi 모델을 Fine-tuning 한 결과, Overlap Handling, Back-channeling, User Interruption 처리 능력이 크게 향상됨을 확인했습니다. 본 연구는 고품질 Full-duplex SLMs 훈련 데이터의 부족 문제를 해소하고, Open-source 생태계에 기여함으로써 Human-computer Interaction 분야의 발전에 중요한 영향을 미칠 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Interleaved Speech Language Models Latently Work In Text
- [논문리뷰] Do What I Say: A Spoken Prompt Dataset for Instruction-Following
- [논문리뷰] VIBEVOICE-ASR Technical Report
- [논문리뷰] End-to-End Joint ASR and Speaker Role Diarization with Child-Adult Interactions
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
Review 의 다른글
- 이전글 [논문리뷰] ShotStream: Streaming Multi-Shot Video Generation for Interactive Storytelling
- 현재글 : [논문리뷰] Sommelier: Scalable Open Multi-turn Audio Pre-processing for Full-duplex Speech Language Models
- 다음글 [논문리뷰] Trace2Skill: Distill Trajectory-Local Lessons into Transferable Agent Skills
댓글