[논문리뷰] Trace2Skill: Distill Trajectory-Local Lessons into Transferable Agent Skills
링크: 논문 PDF로 바로 열기
The paper "Trace2Skill: Distill Trajectory-Local Lessons into Transferable Agent Skills" by Mengyu Zhou, Yihao Liu, Yutao Sun, Xinpeng Liu, Jingwei Ni, et al. introduces a new framework, Trace2Skill, for enhancing the domain-specific skills of Large Language Model (LLM) agents. The core idea is to learn generalizable "Standard Operating Procedures (SoPs)" by analyzing agent trajectories. The authors argue that existing automated skill generation methods are either too shallow (parametric knowledge) or overfit to specific trajectories sequentially. Trace2Skill, in contrast, adopts a human-expert-like approach: it holistically analyzes a broad pool of execution experiences in parallel and then distills these lessons into a single, comprehensive, and conflict-free skill directory using inductive reasoning.
The framework supports two modes: "skill deepening" (refining existing human-written skills) and "skill creation from scratch" (building new skills from a basic LLM-generated draft). Experiments across challenging domains like spreadsheet manipulation, math reasoning, and visual question answering demonstrate that Trace2Skill significantly outperforms strong baselines, including Anthropic’s official xlsx skills. A key finding is that the evolved skills are highly transferable across different LLM scales and generalize well to Out-of-Distribution (OOD) settings without requiring parameter updates or external retrieval modules.
Part 1: 요약 본문
저자: Mengyu Zhou, Yihao Liu, Yutao Sun, Xinpeng Liu, Jingwei Ni, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Skill : LLM Agent가 복잡한 환경에서 태스크를 해결하는 데 필요한 절차적 지식, 도메인 지식, 운영 가이드라인을 인코딩하는 구조화되고 재사용 가능한 문서.
- Trajectory (τ) : LLM Agent가 특정 태스크를 실행하면서 생성하는 일련의 Reasoning trace, Tool call, Observation 및 최종 결과(성공/실패)를 포함하는 실행 기록.
- Skill Patch (p) : 단일 Trajectory 분석을 통해 제안되는 Skill 문서에 대한 수정 또는 추가 사항.
- Inductive Reasoning : 다수의 Trajectory-local Lesson들로부터 공통적이고 일반화 가능한 패턴을 추출하여 Skill에 반영하는 과정.
- Skill Deepening : 기존의 Human-written Skill을 Trajectory 분석을 통해 개선하고 강화하는 모드.
- Skill Creation from Scratch : LLM의 Parametric Knowledge만으로 생성된 초기(비효율적인) Skill 초안을 기반으로 Trajectory 분석을 통해 새로운 Skill을 구축하는 모드.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Large Language Model (LLM) 기반의 Agent는 복잡한 태스크를 해결하기 위해 Domain-specific Skill에 대한 의존도가 높아지고 있습니다. 그러나 이러한 Skill을 수동으로 작성하는 것은 확장성(Scalability) 병목 현상을 초래하며, 기존 Skill이 특정 Agent나 Task Distribution에서 항상 성능 향상을 보장하지 못합니다. 예를 들어, 122B Agent에 효과적인 Human-written Skill이 35B Agent에서는 오히려 성능을 저하시키는 경우가 있었습니다.
기존 자동화된 Skill 생성 방식은 주로 LLM의 Parametric Knowledge에 의존하거나, 개별 Trajectory로부터 얻은 Lesson을 순차적으로 Skill에 반영하는 Online Setting을 사용합니다. 이러한 접근 방식은 종종 깨지기 쉽거나(Fragile), 파편화된(Fragmented) Skill을 생성하며, 특정 Trajectory에 과적합(Overfit)되어 일반화되지 못하는 한계를 보입니다. 저자들은 기존 Online Paradigm이 Skill Fragmentation 및 Sequential Updates 문제를 겪는다고 지적하며, 이는 Human Expert가 Skill을 작성하는 방식(전반적인 경험을 분석 후 통합된 가이드 작성)과 다르다는 점에 주목했습니다. 이러한 문제를 해결하고 Human Expert의 접근 방식을 모방하기 위해, 저자들은 다수의 Trajectory-local Lesson을 병렬적으로 분석하고 이를 단일하고 포괄적인 Agent Skill로 증류하는 Trace2Skill 프레임워크를 제안합니다
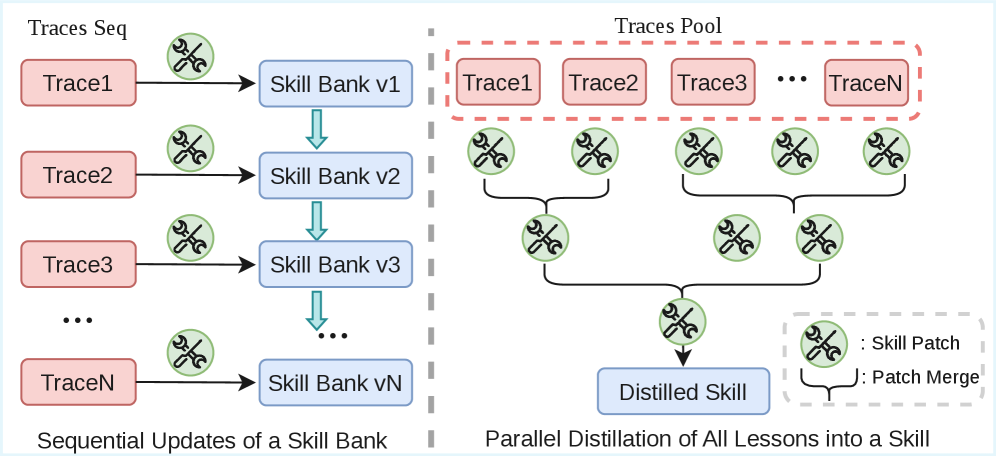
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들이 제안하는 Trace2Skill 프레임워크는 Human Expert의 Skill Authoring 방식을 모방한 세 단계의 Pipeline으로 구성됩니다
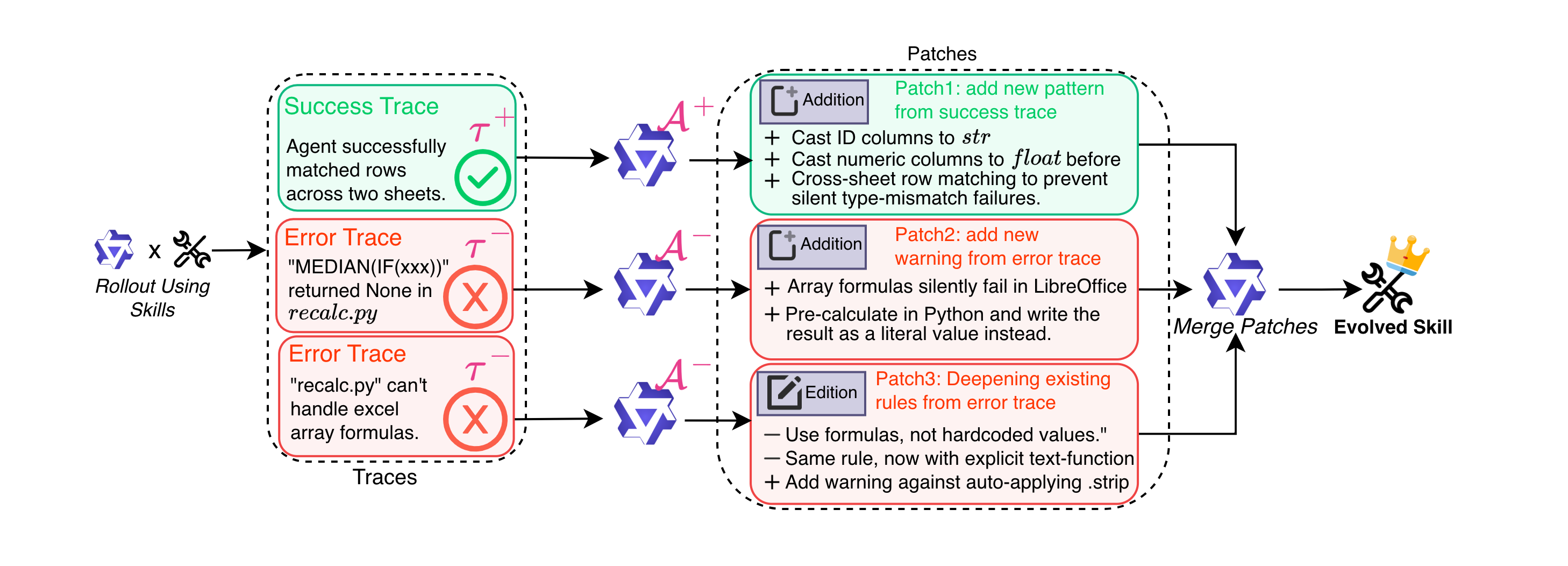
- Stage 1: Trajectory Generation : 초기 Skill (Human-written 또는 LLM-drafted)을 사용하는 Agent (πθ)가 다양한 태스크를 병렬적으로 실행하여 성공(𝒯+) 및 실패(𝒯−) Trajectory 풀(Pool)을 생성합니다. 이 과정은 ReAct Agent Harness를 사용하여 122B LLM으로도 200개의 Trajectory를 2 GPU-hours 미만으로 생성하는 등 효율적입니다.
- Stage 2: Parallel Multi-Agent Patch Proposal : 성공 및 에러 분석 Sub-agent들(𝒜+, 𝒜−)이 Trajectory 풀을 독립적으로 병렬 처리하여 Skill Patch (p)를 제안합니다. 에러 분석가(𝒜−)는 ReAct-style Multi-turn Agentic Loop를 통해 실패의 Root Cause를 반복적으로 진단하고 검증된 Patch를 제안하여 Patch의 품질을 보장합니다.
- Stage 3: Conflict-Free Patch Consolidation : Stage 2에서 제안된 모든 Patch들은 계층적 병합(Hierarchical Merging) 과정을 통해 단일하고 일관된 Skill 업데이트(p∗)로 통합됩니다. 이 과정에서 Programmatic Conflict Prevention과 Inductive Reasoning이 활용되어, 다수의 Trajectory-local Observation에서 반복적으로 나타나는 Prevalent Pattern을 일반화된 원칙으로 추출합니다. 이를 통해 Skill은 모델 간 Transferability를 가지게 됩니다.
실험 결과는 Trace2Skill이 강력한 성능 향상과 뛰어난 일반화 능력을 보임을 입증합니다.
- Skill Deepening : SpreadsheetBench-Verified (SprBench-Vrf) 태스크에서 Human-Written Skill을 Deepening한 결과, 122B Agent 에 대해 +Error 조건에서 +17.5 pp (절대 성능 65.83% ), +Combined 조건에서 +21.5 pp (절대 성능 69.83% )의 Vrf 성능 향상을 달성했습니다 [Table 1]. OOD WikiTableQuestions (WikiTQ)에서도 +Error 가 +1.6 pp , +Combined 가 +4.6 pp 성능을 개선했습니다 [Table 1].
- Skill Creation : Parametric Baseline에서 Skill을 From Scratch로 Creation한 경우, 122B Agent 에 대해 +Error 조건에서 SprBench-Vrf 성능을 +22.8 pp (절대 성능 49.00% ) 향상시켰습니다 [Table 1]. 특히 35B Agent 가 Authoring한 Creation +Error Skill은 122B Agent에 사용될 때 WikiTQ에서 Parametric Baseline 대비 +57.7 pp (절대 성능 81.38% )의 가장 큰 폭의 개선을 보이며 Human-Written Skill을 능가했습니다 [Table 1].
- Generalizability : Trace2Skill로 진화한 Skill은 Trajectory를 생성한 모델(e.g., Qwen3.5-35B)뿐만 아니라 더 큰 모델(e.g., Qwen3.5-122B)에게도 Skill Transferability를 보였으며, SpreadsheetBench 외의 OOD (Out-of-Distribution) 태스크인 Math Reasoning 및 Visual Question Answering (VQA)에서도 일관된 성능 향상을 보여 Skill의 Domain-agnostic 특성을 확인했습니다 [Table 2, Table 3].
- Efficiency : Parallel Consolidation은 Sequential Editing 방식(Seq-B=1 또는 Seq-B=4) 대비 훨씬 효율적이며, 122B 모델에서 Parallel Consolidation은 Sequential 방식보다 SpreadsheetBench-Vrf에서 최대 +6.8 pp 성능 우위를 보이면서도, 약 20배 빠른 처리 시간(3분 vs 60분)을 기록했습니다 [Table 4].
- Comparison with Retrieval-Memory : ReasoningBank와 같은 Retrieval-Memory Baseline 대비, Trace2Skill의 +Combined 방식이 122B 모델 에서 Vrf +13.8 pp , Soft +7.1 pp , Hard +8.2 pp 더 높은 성능을 달성하며 월등히 우수함을 보였습니다 [Table 5]. 이는 Skill 문서로의 Distillation이 Episodic Retrieval보다 효과적임을 시사합니다.
- Agentic Error Analysis : Multi-turn Agentic Loop를 사용하는 Error Analyst (Ours)는 Single-LLM-Call 기반의 Error Analysis 대비 모든 Author-Mode 조합에서 더 높은 Avg 성능을 달성했으며, 특히 122B Deepening 에서 +12.2 pp , 35B Creation 에서 +13.3 pp 더 높은 Avg 점수를 기록했습니다 [Table 6]. 이는 Agentic Analysis가 더 Transferable한 Patch를 생성함을 의미합니다.
4. Conclusion & Impact (결론 및 시사점)
Trace2Skill은 Human Expert의 Skill Authoring 방식을 모방하여, 광범위한 실행 경험으로부터 Trajectory-local Lesson을 Distill하여 Transferable한 Agent Skill을 자동 생성 및 적응시키는 프레임워크입니다. 병렬 Analyst Sub-agent를 통한 Patch Proposal과 Programmatic Conflict Prevention을 포함한 Inductive Reasoning 기반의 동시 Consolidation을 통해 단일하고 일관된 Skill Directory를 구축합니다.
이 연구의 핵심 시사점은 다음과 같습니다.
- 높은 Transferability 및 Generalizability : 특정 모델의 Trajectory로부터 Distill된 Skill이 다른 모델 Scale (e.g., 35B에서 122B) 및 OOD 태스크 (e.g., Spreadsheet에서 WikiTQ)에 걸쳐 놀라운 일반화 성능을 보여주며, 이는 경험이 본질적으로 모델 및 태스크에 종속적이라는 기존의 가정을 뒤집습니다.
- 효율성 및 성능 우위 : 다수의 Trajectory-local Lesson을 동시에 Consolidation하는 방식은 순차적 편집 방식 대비 계산 효율성을 크게 향상시키고, 더 나은 최종 성능을 제공합니다. 또한, Retrieval-based Episodic Memory 방식보다 단일하고 휴대 가능한 Skill 문서가 더 효과적임을 입증했습니다.
- 오픈 소스 LLM의 활용 : 35B와 같은 소규모 오픈 소스 LLM만으로도 강력한 Skill Evolution이 가능함을 보여, Proprietary 모델에 대한 의존성을 제거하고 Skill Evolution의 접근성을 높입니다.
- 계층적 지식 인코딩 :
SKILL.md파일에 일반화 가능한 원칙을 인코딩하고,references/하위 디렉토리에 Case-specific한 Pitfall을 정리하는 계층적 구조를 자동으로 학습함으로써, Skill 디자인의 Best Practice를 구현합니다.
궁극적으로 Trace2Skill은 복잡한 Agent 경험을 Highly Transferable하고 Declarative한 Skill로 패키징할 수 있음을 보여주며, 이는 향후 LLM Agent의 자율성과 효율성 향상에 중요한 기여를 할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] OpenSkill: Open-World Self-Evolution for LLM Agents
- [논문리뷰] SkillGrad: Optimizing Agent Skills Like Gradient Descent
- [논문리뷰] SkillEvolBench: Benchmarking the Evolution from Episodic Experience to Procedural Skills
- [논문리뷰] SkillsVote: Lifecycle Governance of Agent Skills from Collection, Recommendation to Evolution
- [논문리뷰] SkillClaw: Let Skills Evolve Collectively with Agentic Evolver
Review 의 다른글
- 이전글 [논문리뷰] Sommelier: Scalable Open Multi-turn Audio Pre-processing for Full-duplex Speech Language Models
- 현재글 : [논문리뷰] Trace2Skill: Distill Trajectory-Local Lessons into Transferable Agent Skills
- 다음글 [논문리뷰] Density-aware Soft Context Compression with Semi-Dynamic Compression Ratio
댓글