[논문리뷰] Memory-Augmented Vision-Language Agents for Persistent and Semantically Consistent Object Captioning
링크: 논문 PDF로 바로 열기
저자: Tommaso Galliena, Stefano Rosa, Tommaso Apicella, Pietro Morerio, Alessio Del Bue, Lorenzo Natale
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- EPOS-VLM : 본 논문에서 제안하는 End-to-End 방식의 메모리 증강 Vision-Language-Action 모델로, 데이터 연관, 객체 캡셔닝, 탐색 정책을 통합 수행합니다.
- Episodic Object Memory : 객체의 캡션 이력(Caption History)과 3D 위치 정보를 구조화하여 토큰화된 형태로 VLM에 주입, 장기적 객체 식별과 의미론적 일관성을 유지하게 하는 메모리 메커니즘입니다.
- 3D-CPS (3D-Aware Consistent Pseudo-Captioner) : 다중 시점의 관측 결과를 통합하여 객체 고유의 속성을 추출하고 뷰포인트에 독립적인 캡션을 생성하는 자가 학습(Self-supervised)용 Pseudo-captioning 방식입니다.
- [MATCH] Token : 현재 RGB 관측 내의 객체와 기존 메모리 내 객체 식별자(Persistent Object ID) 사이의 연관성을 명시적으로 학습하기 위해 도입된 특수 토큰입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 연구는 embodied 환경에서 시점 변화, 거리, 폐색(Occlusion)으로 인해 발생하는 객체 묘사의 의미론적 불일치(Semantic Inconsistency) 문제를 해결하는 것을 목적으로 합니다. 기존의 Vision-Language Models(VLMs)은 정적 데이터셋 위주로 학습되어 물리적 환경의 동적 특성을 반영하지 못하며, 이전 연구들은 탐색, 데이터 연관, 캡셔닝 단계를 독립적으로 분리하여 장기적인 객체 일관성 확보에 한계가 있었습니다. 특히
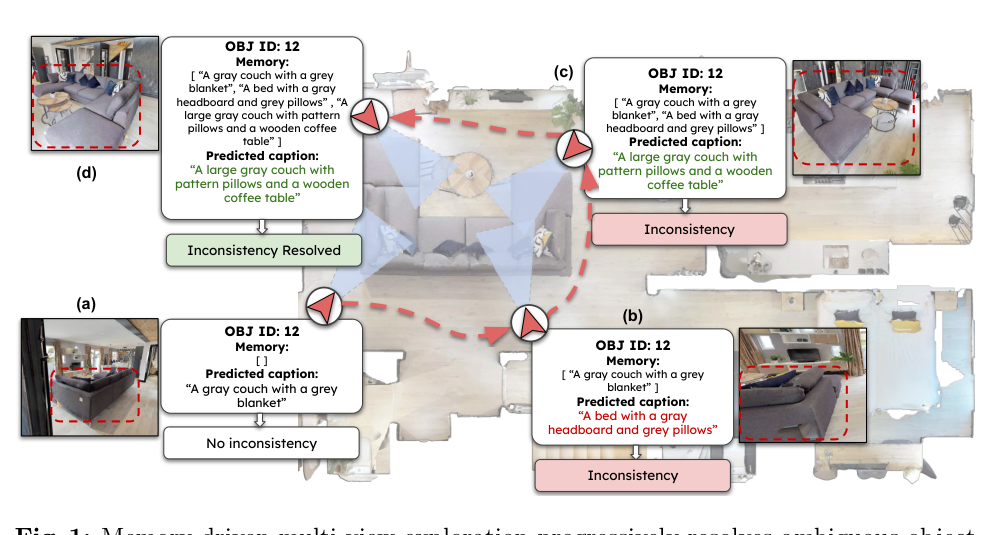
에서 제시하듯, 동일한 물리적 객체가 시점에 따라 서로 다르게 묘사되는 문제는 embodied 에이전트의 persistent한 scene 이해를 저해합니다. 따라서 에이전트가 탐색 과정에서 능동적으로 정보를 획득하고, 이전 관측 결과를 메모리에 통합하여 이를 보정하는 unified 프레임워크가 필요합니다.
## 3. Method & Key Results (제안 방법론 및 핵심 결과) EPOS-VLM은
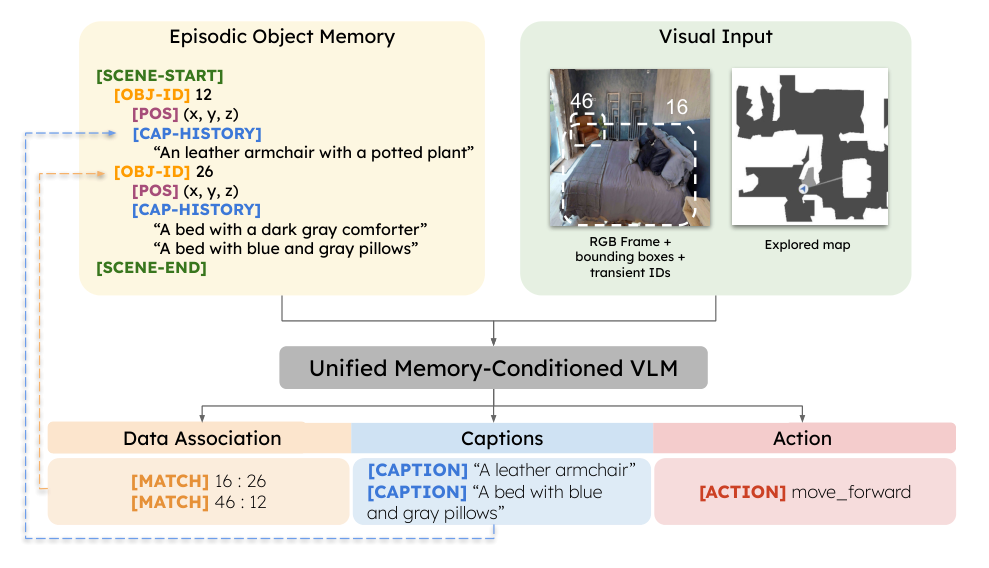
와 같이 구조화된 Episodic Memory를 VLM의 입력을 직관적으로 결합하여, data association, 캡셔닝, navigation action을 하나의 autoregressive 프로세스로 최적화합니다. 에이전트는 [MATCH] 토큰을 활용해 새로운 관측 객체를 기존 ID에 매칭하거나 새로운 ID를 생성하며, 이를 통해 장기적인 객체 ID 일관성을 유지합니다. 실험 결과, EPOS-VLM은 HM3D test set에서 기존 최고 모델 대비 SPICE에서 +9.76 p.p. 향상된 성능을 보였으며,
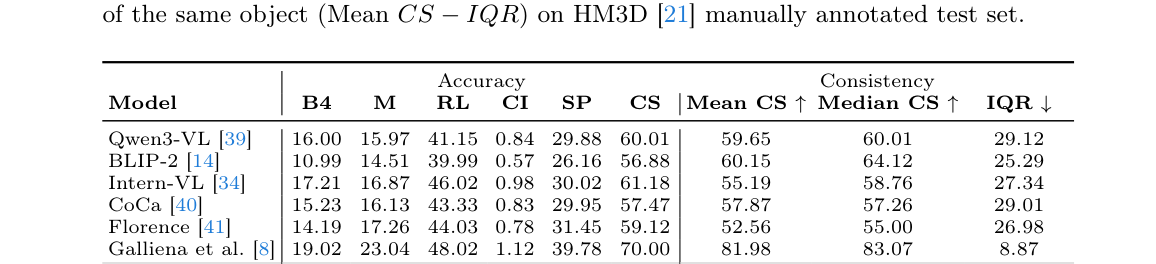
에서 확인되듯 의미론적 일관성을 측정하는 Mean CS 수치에서도 압도적인 우위를 확보했습니다. 또한, [Table 4]를 통해 본 모델의 데이터 연관 성능이 기존 point-cloud 기반 기법과 대등하거나 더 우수하면서도, [Figure 3]과 같이 추론 시간과 메모리 사용량 측면에서 훨씬 가벼운 효율성을 보여주었습니다.
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 episodic memory를 VLM의 입력으로 통합하는 구조를 통해 embodied 환경에서 높은 수준의 의미론적 일관성을 가진 객체 캡셔닝을 가능하게 했습니다. 이 연구는 복잡한 3D 환경에서 에이전트가 단기적인 시각적 정보에 의존하지 않고, 축적된 기억을 바탕으로 객체의 본질적인 속성을 추론할 수 있음을 입증했습니다. 특히, 제안된 메모리 기반 데이터 연관 방식은 대규모 dense 3D 포인트 클라우드 없이도 효율적인 탐색과 인식 성능을 보장하므로, 향후 실제 환경에서 작동하는 embodied AI 에이전트의 효율적인 배포에 크게 기여할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] RoboStressBench: Benchmarking VLM Robustness to Physical Visual Stress in Embodied Scenes
- [논문리뷰] Seeing Isn't Knowing: Do VLMs Know When Not to Answer Spatial Questions (and Why)?
- [논문리뷰] PokeGym: A Visually-Driven Long-Horizon Benchmark for Vision-Language Models
- [논문리뷰] From Perception to Action: An Interactive Benchmark for Vision Reasoning
- [논문리뷰] QuantiPhy: A Quantitative Benchmark Evaluating Physical Reasoning Abilities of Vision-Language Models
Review 의 다른글
- 이전글 [논문리뷰] MDPBench: A Benchmark for Multilingual Document Parsing in Real-World Scenarios
- 현재글 : [논문리뷰] Memory-Augmented Vision-Language Agents for Persistent and Semantically Consistent Object Captioning
- 다음글 [논문리뷰] Omni-SimpleMem: Autoresearch-Guided Discovery of Lifelong Multimodal Agent Memory
댓글