[논문리뷰] ArtifactNet: Detecting AI-Generated Music via Forensic Residual Physics
링크: 논문 PDF로 바로 열기
저자: Heewon Oh
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- RVQ (Residual Vector Quantization): AI 오디오 코덱이 연속적인 오디오 신호를 이산적인 코드북 벡터로 변환하는 핵심 기술로, 이 과정에서 발생하는 불가역적인 정보 손실이 고유한 포렌식 흔적을 생성함.
- Forensic Residuals: 원본 오디오에서 신경망 기반 오디오 코덱의 처리 과정을 거친 후 남는 재구성 오차 신호로, 모델의 물리적 특성을 반영하는 핵심 지표.
- ArtifactUNet: 입력된 스펙트로그램으로부터 포렌식 잔차를 추출하기 위해 Bounded-mask를 사용하는 U-Net 기반의 경량화 네트워크.
- HPSS (Harmonic-Percussive Source Separation): 오디오 신호를 조화로운(Harmonic) 요소와 타악기적인(Percussive) 요소로 분리하는 기술로, 본 논문에서는 잔차의 이상 패턴을 탐지하기 위해 사용됨.
- ArtifactBench: 총 22개의 생성 모델과 6개의 실제 데이터 소스로 구성된 다중 생성기 대상 벤치마크로, fair zero-shot 평가를 위한 엄격한 기준을 제공함.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 연구는 기존 AI 음악 탐지 모델들이 일반적인 학습 데이터의 표면적인 특징에 의존하여 새로운 생성 모델에 대해 낮은 일반화 성능을 보이는 문제를 해결하고자 한다. 기존의 Representation Learning 및 Autoencoder fingerprinting 기반 기법들은 학습된 분포 내에서는 높은 정확도를 보이나, 미학습 생성기를 만날 경우 구조적인 일반화 실패를 겪는다. 특히, 서로 다른 오디오 압축 코덱이나 장르 분포의 차이가 탐지 모델에 혼선을 주는 교란 요소로 작용하며, 이를 극복하기 위해 물리적 기반의 근본적인 탐지 기법이 필요하다.
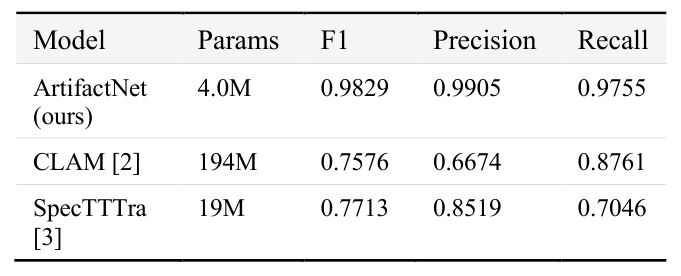
에 나타난 기존 연구들의 낮은 성과와 높은 FPR은 이러한 도메인 일반화 문제를 명확히 보여준다.
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 본 논문은 AI 생성 음악을 탐지하는 문제를 물리적 포렌식 잔차를 분석하는 과정으로 재정의하는 ArtifactNet 프레임워크를 제안한다. 시스템은 크게 3단계로 구성되는데, ArtifactUNet을 통한 포렌식 잔차 추출, HPSS를 활용한 7채널 특징 생성, 그리고 최종 판단을 위한 경량 CNN 분류로 이어진다. Codec-aware training을 통해 다양한 압축 코덱 환경에서도 강건한 성능을 보장하며, 전체 모델은 오직 4.0M 파라미터로 동작한다. 실험 결과, ArtifactNet은 ArtifactBench에서 F1 = 0.9829와 FPR = 1.49%를 기록하여, 비교 대상인 CLAM이나 SpecTTTra보다 훨씬 높은 정밀도와 재현율을 확보하였다. [Table 3]의 성능 지표는 제안 방법이 기존 기법 대비 훨씬 적은 파라미터로도 압도적인 성능 우위를 점함을 입증한다.
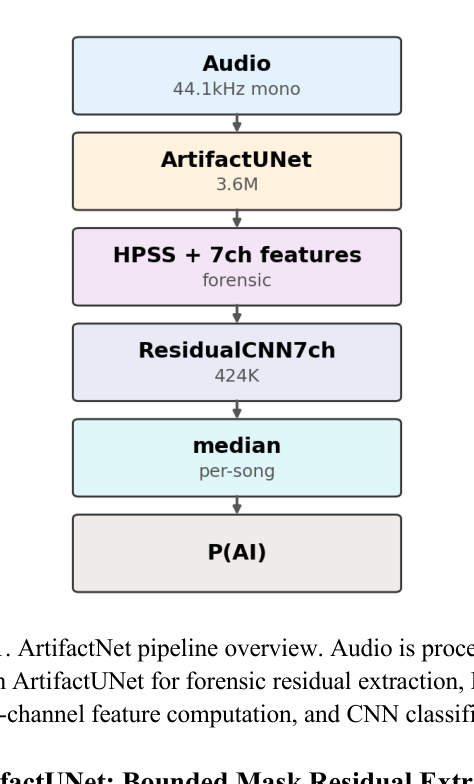
은 제안된 전체 파이프라인의 구조를 나타낸다.
## 4. Conclusion & Impact (결론 및 시사점) 본 연구는 AI 음악 생성의 근본적 제약인 RVQ 병목 현상을 포렌식 신호로 활용함으로써 모델 의존성을 제거한 범용 탐지 프레임워크를 정립하였다. 제안된 물리 기반 포렌식 기법은 향후 새로운 생성 모델이 등장하더라도 정보 이론적 제약에 의해 발생하는 잔차를 포착할 수 있어 강력한 장기적 대응력을 제공한다. 본 결과물은 AI 생성 콘텐츠의 투명성 확보 및 저작권 보호를 위한 산업계 표준 탐지 솔루션 개발에 기여하며, 향후 오디오 위변조 탐지 기술의 새로운 기준점을 제시할 것으로 평가된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Hierarchical Codec Diffusion for Video-to-Speech Generation
- [논문리뷰] MOSS-Audio-Tokenizer: Scaling Audio Tokenizers for Future Audio Foundation Models
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] Where, What, Why, and Importance: Structured Defect Grounding for Text-to-Image Feedback
- [논문리뷰] WeaveBench: A Long-Horizon, Real-World Benchmark for Computer-Use Agents with Hybrid Interfaces
Review 의 다른글
- 이전글 [논문리뷰] AccelOpt: A Self-Improving LLM Agentic System for AI Accelerator Kernel Optimization
- 현재글 : [논문리뷰] ArtifactNet: Detecting AI-Generated Music via Forensic Residual Physics
- 다음글 [논문리뷰] Can Large Language Models Reinvent Foundational Algorithms?
댓글