[논문리뷰] Seeing Fast and Slow: Learning the Flow of Time in Videos
링크: 논문 PDF로 바로 열기
저자: Yen-Siang Wu, Rundong Luo, Jingsen Zhu, Tao Tu, Ali Farhadi, Matthew Wallingford, Yu-Chiang Frank Wang, Steve Marschner, Wei-Chiu Ma
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- SloMo-44K: 본 연구에서 구축한 대규모 slow-motion 비디오 데이터셋으로, 44,632개의 클립과 18M 프레임을 포함함.
- Time–frequency Scaling: 비디오 재생 속도 변화에 따라 오디오의 pitch가 변하는 원리를 이용해 속도 변화를 감지하는 self-supervised 기법.
- Equivariance in Speed Estimation: 비디오를 $k$배 가속했을 때 모델의 예측 속도값 역시 $k$배 스케일링되어야 한다는 기하학적 제약 조건.
- Iterative Prediction (IP): 속도 예측의 정확도를 높이기 위해 모델의 초기 예측을 기반으로 비디오를 재조정하여 반복적으로 추론하는 기법.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 연구는 기존 비디오 모델들이 물리적 세계의 시간 흐름을 이해하고 제어하지 못하는 근본적인 한계를 해결하고자 한다. 현재의 비디오 모델들은 주로 표준 frame rate(24-60 fps) 비디오로 학습되어, 시간적 속도(temporal speed) 개념을 학습할 기회가 부족하며, 이로 인해 속도 예측이나 생성 작업 시 심각한 정확도 저하가 발생한다. 특히 기존 데이터셋은 규모가 작거나 특정 분야에 한정되어 있으며, 생성 모델이 prompt 기반의 텍스트 제어만으로는 물리적으로 정교한 속도 조절을 수행하지 못한다는 문제점이 있다. 본 연구는 이러한 시간적 인지 능력의 부재를 해결하기 위해 self-supervised 학습을 통한 시간 인지 모델을 제안한다.
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 제안하는 프레임워크는 멀티모달 신호와 시간적 구조를 활용하여 비디오의 playback speed를 추정하고 이를 기반으로 고품질 slow-motion 비디오를 생성 및 보간한다. 구체적으로, audio의 pitch 변화를 이용해 속도 변화 지점을 탐지하고, Equivariance 기반의 학습 objective를 설계하여 ground-truth 라벨 없이도 속도 예측 모델 $f_{\theta}$를 훈련시킨다. 또한, 획득한 데이터셋을 기반으로 Wan2.1-I2V 모델을 수정하여 특정 속도 조건에 따른 생성(speed-conditioned generation)을 가능하게 하였다. 실험 결과, 제안 모델은 speed-change detection에서 92.4%의 높은 정확도를 기록하였으며, playback-speed estimation task에서 휴먼 전문가에 근접하는 성능을 달성하였다. 또한, temporal super-resolution 부문에서 FILM 등 기존 기법 대비 FID와 FVD 지표에서 우위를 점하며 시각적 품질과 시간적 일관성을 동시에 개선하였다 [Table 3], [Table 4].
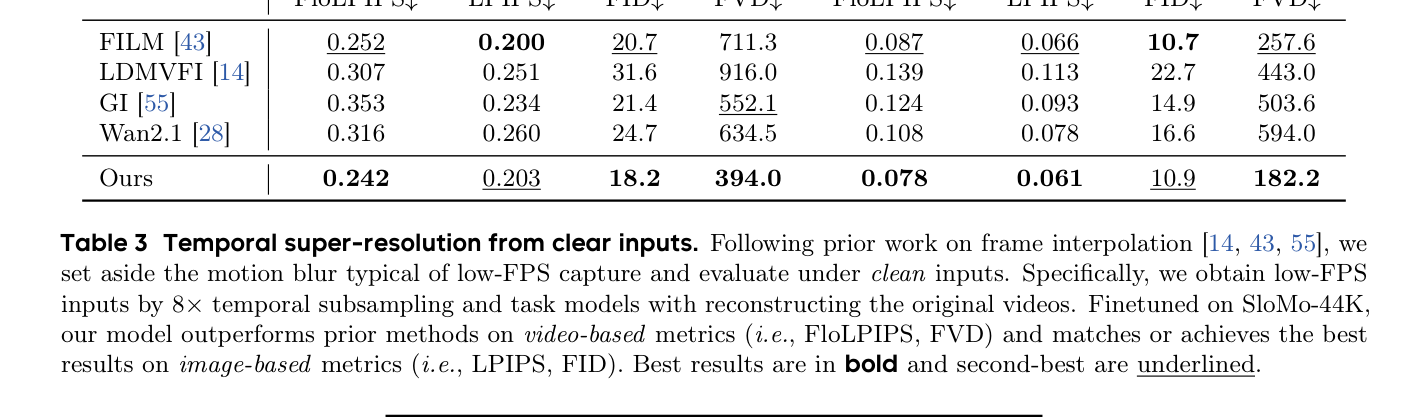
Table 3 — Clear input 조건에서의 SOTA 모델들과의 정량적 성능 비교표
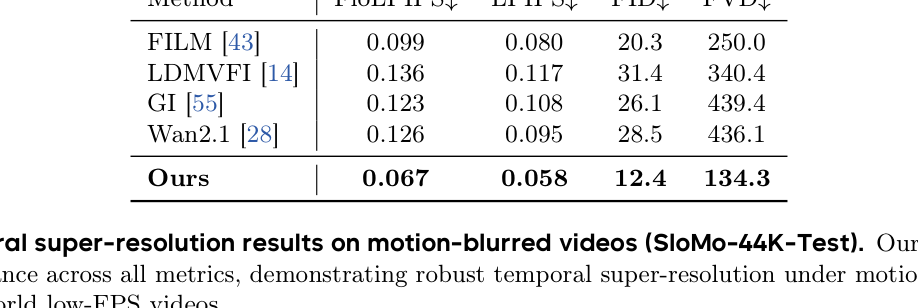
Table 4 — 실제 환경과 유사한 motion-blurred 조건에서의 성능 비교표
## 4. Conclusion & Impact (결론 및 시사점) 본 연구는 시간을 단순히 순차적인 데이터의 흐름이 아니라, 모델이 학습하고 조작할 수 있는 하나의 'perceptual dimension'으로 재정의하였다. 대규모 slow-motion 데이터셋인 SloMo-44K 구축과 이를 활용한 제어 가능한 생성 프레임워크는 비디오 분석 및 생성 분야의 새로운 가능성을 제시한다. 이러한 연구 결과는 미래의 영상 분석 시스템이 실제 물리적 사건의 시간적 흐름을 보다 정확하게 이해하고, 비디오 포렌식이나 고정밀 영상 편집 분야에서 실용적인 도구로 활용될 것으로 기대된다.

Figure 1 — 시간 인지 및 제어 모델의 핵심 태스크(속도 변화 감지, 추정, 보간, 생성)를 한눈에 보여주는 다이어그램
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] MilliVid: Hierarchical Latents for Long-Range Consistency in Video Generation
- [논문리뷰] Latent Spatial Memory for Video World Models
- [논문리뷰] Physics in 2-Steps: Locking Motion Priors Before Visual Refinement Erases Them
- [논문리뷰] AnchorWorld: Embodied Egocentric World Simulation with View-based Evolution Customization
- [논문리뷰] LoomVideo: Unifying Multimodal Inputs into Video Generation and Editing
Review 의 다른글
- 이전글 [논문리뷰] PersonalAI: A Systematic Comparison of Knowledge Graph Storage and Retrieval Approaches for Personalized LLM agents
- 현재글 : [논문리뷰] Seeing Fast and Slow: Learning the Flow of Time in Videos
- 다음글 [논문리뷰] StyleID: A Perception-Aware Dataset and Metric for Stylization-Agnostic Facial Identity Recognition
댓글