[논문리뷰] Hierarchical Abstract Tree for Cross-Document Retrieval-Augmented Generation
링크: 논문 PDF로 바로 열기
Part 1: 요약 본문
저자: Ziwen Zhao, Menglin Yang, et al.
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- Ψ-RAG: 본 논문에서 제안하는 트리 기반의 RAG 프레임워크로, Hierarchical Abstract Tree와 Multi-granular Agentic Retriever를 결합하여 구조적 고립 문제와 분포 적응성 한계를 극복함.
- Hierarchical Abstract Tree: 문서 컬렉션을 계층적으로 구조화하기 위해 AHC(Agglomerative Hierarchical Clustering) 원리를 적용한 인덱스로, 유사도 기반의 'merging and collapse' 과정을 통해 데이터 분포에 적응하는 트리 인덱스.
- Multi-granular Agentic Retriever: R&A Agent가 사용자 쿼리를 분석하고 필요 시 Sparse Retrieval(BM25)과 Dense Tree Retrieval을 하이브리드로 호출하여 다중 홉(multi-hop) 추론을 수행하는 검색 엔진.
- Uniform Effect: k-means 기반 클러스터링이 데이터의 실제 분포와 관계없이 클러스터 크기를 균일하게 맞추려 하여, 소수 테마를 가진 문서들이 주요 테마 클러스터에 흡수되어 정보 검색의 정확도를 낮추는 현상.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의)
- 본 연구는 기존 Tree-RAG 방법론들이 단일 문서 내 단일 홉 질문에만 최적화되어 있어, 복잡한 교차 문서 multi-hop 질문 대응 및 corpus-level 확장에 한계가 있다는 점을 지적한다.
- 기존 RAPTOR와 같은 k-means 기반 클러스터링은 구형(spherical) 분포 가정을 바탕으로 하기 때문에 데이터의 편향된 분포를 제대로 처리하지 못하는 Uniform Effect를 발생시킨다.
- 또한, 트리 구조의 리프 노드들이 명시적 연결 없이 구조적으로 고립되어 있어, 복잡한 인과 관계나 추론이 필요한 질문을 해결하는 데 정밀한 정보 추상화가 부족하다.
- [Figure 1]은 기존 Tree-RAG와 Graph-RAG가 가진 효율성 및 성능의 트레이드오프와 본 논문이 제안하는 Ψ-RAG의 우위성을 보여주는 애플리케이션 시나리오를 제시한다.
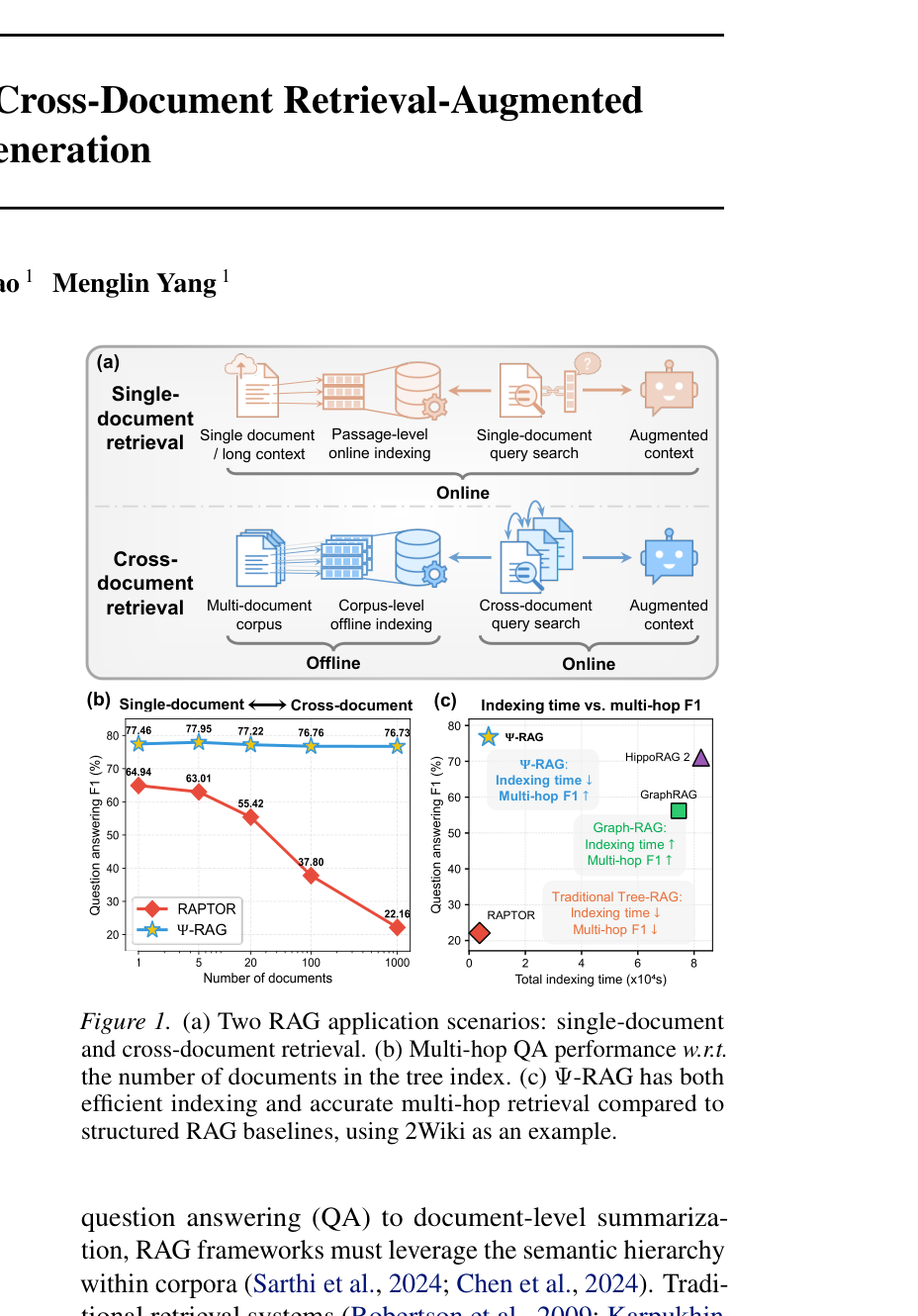
Figure 1 — 전체 RAG 워크플로우 및 기존 연구와의 성능 비교 결과
## 3. Method & Key Results (제안 방법론 및 핵심 결과)
- Ψ-RAG는 AHC 알고리즘을 변형한 'merging and collapse' 프로세스를 통해 문서 청크를 계층적으로 연결하며, 인위적인 분포 가정 없이도 실제 데이터 분포를 효과적으로 반영하는 인덱스를 구축한다.
- R&A Agent는 다중 턴 상호작용을 통해 Retrieve와 Answer 액션을 결정하며, 특히 Query Reorganization 기술을 통해 사용자 쿼리를 보강함으로써 검색 성능을 높인다.
- [Table 2]에 따르면, Ψ-RAG는 multi-hop QA 벤치마크(HotpotQA, 2Wiki 등)에서 RAPTOR 대비 평균 25.9% 높은 F1 score를 기록하였으며, 최신 Graph-RAG 모델인 HippoRAG 2보다도 7.4% 우수한 성능을 보였다.
- [Table 3]의 검색 정확도 평가에서는 Recall@5 지표에서 기존 모델 대비 높은 개선율을 보이며, 특히 Sparse Retriever와의 결합이 coarse abstraction으로 인한 한계를 성공적으로 보완함을 정량적으로 입증하였다.
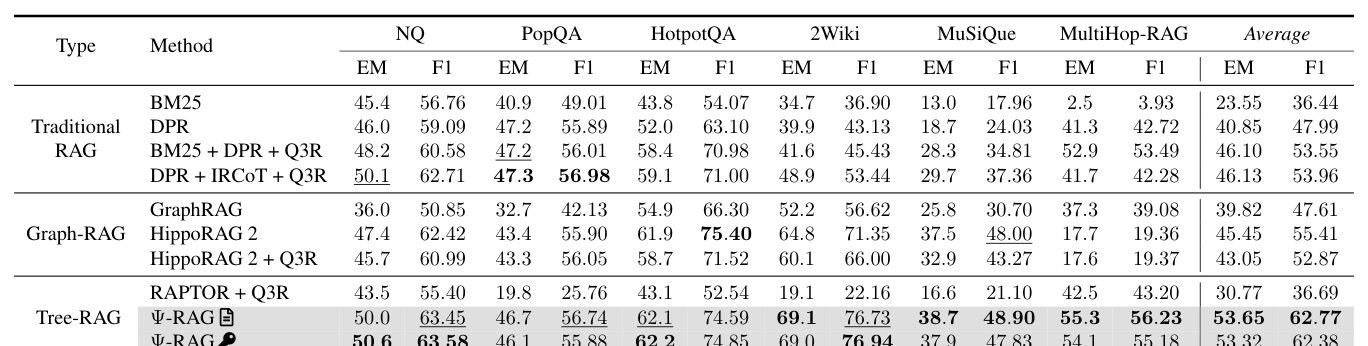
Table 2 — 주요 모델과의 정량적 성능 비교를 보여주는 핵심 테이블
## 4. Conclusion & Impact (결론 및 시사점)
- 본 연구는 Hierarchical Abstract Tree 기반의 새로운 RAG 프레임워크인 Ψ-RAG를 통해 대규모 문서 집합에서의 multi-hop 추론과 검색 성능을 획기적으로 개선하였다.
- 본 모델은 데이터 분포에 대한 비적응성, 트리 노드의 구조적 고립, 정보 손실 문제를 동시에 해결함으로써 트리 기반 RAG 연구의 한계점을 극복했다는 의의가 있다.
- 본 연구에서 증명된 Ψ-RAG의 높은 효율성과 일반화 능력은 향후 산업계의 대규모 지식베이스 기반 LLM 시스템 구축에 있어 실용적인 가이드라인을 제공할 것으로 기대된다.
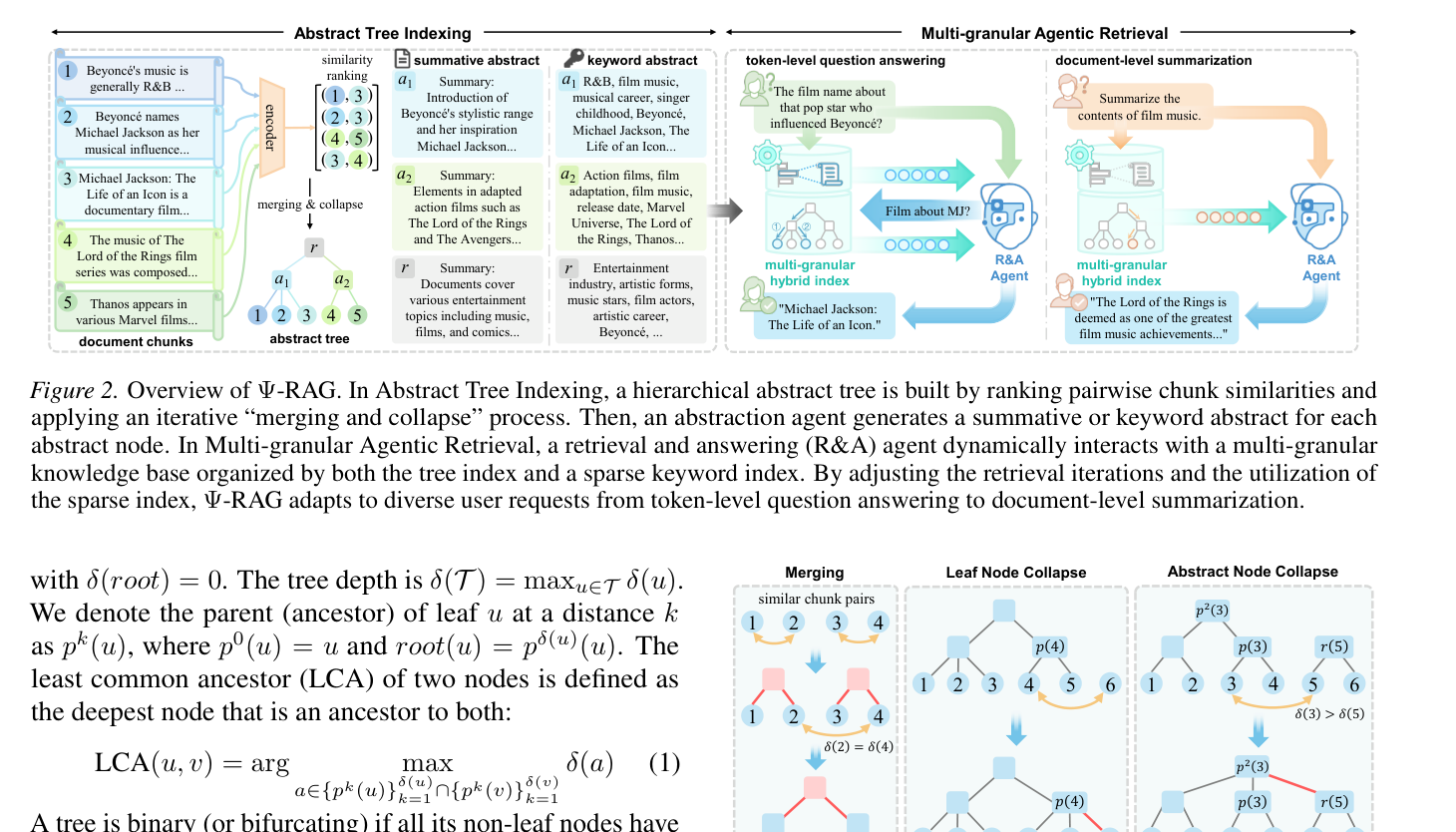
Figure 2 — Ψ-RAG의 인덱싱 및 에이전트 기반 검색 워크플로우를 보여주는 다이어그램
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLM-Enabled NWDAF: A Step Toward AI-Native 6G Network Intelligence
- [논문리뷰] KV Packet: Recomputation-Free Context-Independent KV Caching for LLMs
- [논문리뷰] Strategic Navigation or Stochastic Search? How Agents and Humans Reason Over Document Collections
- [논문리뷰] Semantic Search over 9 Million Mathematical Theorems
- [논문리뷰] SAGE: Benchmarking and Improving Retrieval for Deep Research Agents
Review 의 다른글
- 이전글 [논문리뷰] Generative Modeling with Orbit-Space Particle Flow Matching
- 현재글 : [논문리뷰] Hierarchical Abstract Tree for Cross-Document Retrieval-Augmented Generation
- 다음글 [논문리뷰] MolmoAct2: Action Reasoning Models for Real-world Deployment
댓글