[논문리뷰] Anti-Self-Distillation for Reasoning RL via Pointwise Mutual Information
링크: 논문 PDF로 바로 열기
저자: Guobin Shen, Xiang Cheng, Chenxiao Zhao, Lei Huang, Jindong Li, Dongcheng Zhao, Xing Yu
1. Key Terms & Definitions (핵심 용어 및 정의)
- AntiSD (Anti-Self-Distillation): 기존 self-distillation의 기울기 방향을 반대로 뒤집어 학습하는 방법론으로, 연산 과정에서 shortcut bias를 억제하고 deliberation 토큰을 강화합니다.
- GRPO (Group Relative Policy Optimization): 다수의 rollout 그룹 내에서 sequence-level advantage를 산출하여 모델을 학습시키는 강화학습 프레임워크입니다.
- Conditional PMI (Pointwise Mutual Information): 다음 토큰과 privileged context 간의 정보적 연관성을 수치화한 지표로, 기본 self-distillation이 구조적으로 왜곡된 신호를 생성하는 원인을 분석하는 도구로 사용됩니다.
- Entropy-triggered Gate: 학습 후반부에 teacher 모델의 엔트로피가 급격히 낮아져 신호가 왜곡되는 것을 방지하기 위해, 엔트로피 수준에 따라 AntiSD 업데이트를 동적으로 제어하는 안정화 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM의 추론 능력을 강화하기 위한 on-policy self-distillation 기법이 수학적 추론 과제에서 일관된 성능 향상을 보이지 못하는 문제를 해결합니다. 기존 self-distillation은 verified solution과 같은 privileged context를 활용하지만, 이 과정에서 정답을 유추할 수 있는 'shortcut 토큰'에 대해서는 모델의 신뢰도를 과도하게 높이고, 복잡한 사고 과정인 'deliberation 토큰'은 오히려 억제하는 구조적 편향을 가집니다 [Figure 1]. 이러한 문제로 인해 모델은 스스로 깊게 사고하기보다 정답 패턴을 암기하는 경향을 보이게 되며, 이는 결과적으로 복잡한 추론 과제에서의 성능 저하로 이어집니다.

Figure 1 — AntiSD의 원리와 GRPO 대비 성능 우위
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구에서 제안하는 AntiSD는 학습의 기울기 방향을 descent에서 ascent로 역전시켜, shortcut 토큰의 보상을 낮추고 deliberation 토큰의 가치를 높이는 방식으로 작동합니다 [Figure 1]. 저자들은 Jensen-Shannon divergence의 ascent를 통해 자연스러운 경계(bounded advantage)를 설정하였으며, 학습 과정의 안정성을 위해 Entropy-triggered gate를 도입하여 teacher 모델의 엔트로피가 낮아질 경우 해당 업데이트를 비활성화하도록 설계하였습니다 [Figure 2].

Figure 2 — Deliberation 토큰과 Shortcut 토큰의 분포
실험 결과, AntiSD는 GRPO baseline 대비 2배에서 10배 더 적은 학습 단계로 동일한 정확도에 도달하였으며, 최종 정확도 또한 최대 11.5 포인트 향상되는 성과를 보였습니다 [Table 1]. 특히, pass@k 평가를 통해 모델이 단순히 다수결에 의존하는 것이 아니라 실제 추론 능력이 향상되었음을 확인하였습니다 [Figure 3]. 또한, 본 방법론은 Qwen3 및 Olmo-3 계열의 다양한 모델 사이즈(4B~30B)에서 일관된 성능 우위를 점하며 확장성을 입증하였습니다 [Table 1].
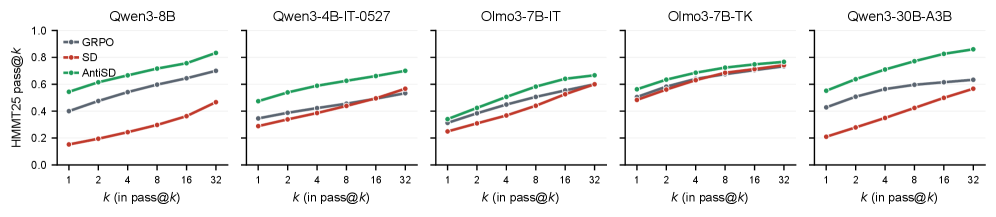
Figure 3 — AntiSD의 pass@k 성능 개선 효과
4. Conclusion & Impact (결론 및 시사점)
본 논문은 self-distillation의 내부 신호가 Conditional PMI라는 구조적 shortcut bias를 내포하고 있음을 밝혀내고, 이를 역전시키는 AntiSD를 통해 해결책을 제시합니다. 이 연구는 별도의 외부 teacher나 복잡한 과정 보상 모델 없이도 모델이 스스로의 추론 신호를 개선할 수 있는 효율적인 학습 경로를 열어주었습니다. 향후 LLM의 자기 주도적 학습 방식과 효율적인 강화학습 프레임워크 설계에 중요한 학술적, 실무적 기반을 제공할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Understanding Reasoning from Pretraining to Post-Training
- [논문리뷰] Agon: Competitive Cross-Model RL with Implicit Rival Grading of Reasoning
- [논문리뷰] TREK: Distill to Explore, Reinforce to Refine
- [논문리뷰] F-GRPO: Factorized Group-Relative Policy Optimization for Unified Candidate Generation and Ranking
- [논문리뷰] The Flexibility Trap: Why Arbitrary Order Limits Reasoning Potential in Diffusion Language Models
Review 의 다른글
- 이전글 [논문리뷰] Active Learners as Efficient PRP Rerankers
- 현재글 : [논문리뷰] Anti-Self-Distillation for Reasoning RL via Pointwise Mutual Information
- 다음글 [논문리뷰] Artifact-Bench: Evaluating MLLMs on Detecting and Assessing the Artifacts of AI-Generated Videos
댓글