[논문리뷰] CopT: Contrastive On-Policy Thinking with Continuous Spaces for General and Agentic Reasoning
링크: 논문 PDF로 바로 열기
메타데이터
저자: Dachuan Shi, Hanlin Zhu, Xiangchi Yuan, Wanjia Zhao, Kejing Xia, Wen Xiao, Wenke Lee
1. Key Terms & Definitions (핵심 용어 및 정의)
- CopT: 기존의 '생각 후 답변' 방식 대신 '답변 우선 도출 후 필요한 경우에만 생각'하는 역방향 추론 패러다임.
- Continuous Embeddings: 확률 분포의 가중 평균으로 계산된 임베딩으로, 이 논문에서는 추론 시점의 불확실성을 포착하는 Contrastive Verifier로 활용됨.
- Reverse KL Estimator: discrete-token 기반 모델의 지원과 continuous-embedding 기반 모델의 지원을 비교하여, 답변의 신뢰도를 측정하는 수치.
- Performative Reasoning: 모델이 이미 내부적으로 답변을 알고 있음에도 불구하고, 관습적인 CoT 절차를 따르기 위해 불필요하게 생각을 지속하는 현상.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 표준 CoT 패러다임이 가진 비효율적인 '생각 후 답변' 순서와, 이미 답변을 도출한 후에도 불필요하게 추론을 지속하는 Performative Reasoning 문제를 해결하고자 한다 [Figure 1]. 기존의 Latent CoT 기법들은 continuous space에서의 생성을 통해 추론 효율을 높이려 했으나, 이 과정에서 모델의 가독성이 떨어지거나 학습이 필요한 경우가 많았다. 저자들은 이러한 한계를 극복하기 위해, 모델의 생성 순서를 역전시켜 토큰 효율성을 극대화하고 추론 비용을 절감하는 새로운 파이프라인을 제안한다.
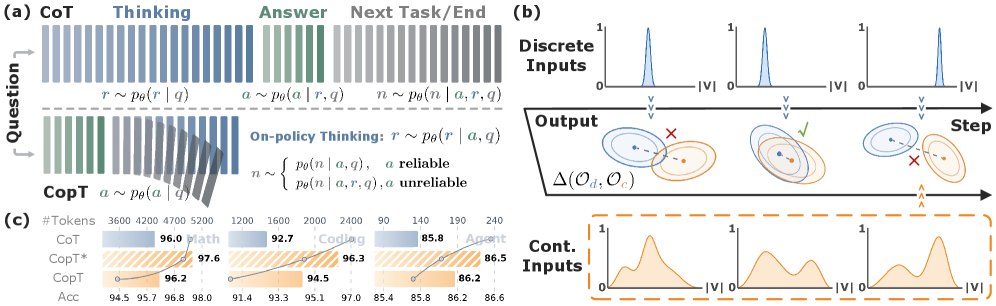
Figure 1 — CoT와 CopT의 개념적 차이 및 효율성 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
CopT는 먼저 Draft Answer를 빠르게 생성한 뒤, 제안된 Reverse KL Estimator를 통해 해당 답변의 신뢰도를 평가한다 [Figure 2]. 신뢰도가 낮다고 판단될 경우에만 On-Policy Thinking 단계를 트리거하여 교정을 수행하며, 이 과정에서 Visibility Control을 통해 불필요한 정보 노출로 인한 오류를 방지한다 [Figure 2]. 주요 실험 결과, Qwen3-8B 모델을 사용한 수학 및 코딩 벤치마크에서 기존 CoT 대비 피크 정확도(Peak Accuracy)를 최대 23% 개선하였으며, 동일하거나 더 높은 정확도 수준에서 토큰 사용량을 최대 57% 절감하였다 [Figure 1]. 또한, 제안 방법론은 추가적인 모델 학습(Training-free) 없이도 기존의 latent 생성 기반 기법들보다 우수한 성능과 높은 가독성을 입증하였다 [Table 2].
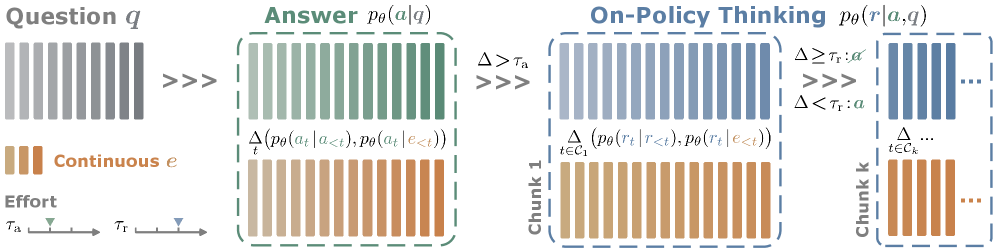
Figure 2 — CopT의 전체 추론 파이프라인
4. Conclusion & Impact (결론 및 시사점)
본 연구는 LLM의 추론 패러다임을 '답변 우선'으로 재설계함으로써 추론 효율과 정확도라는 두 가지 목표를 동시에 달성하였다. CopT가 제안한 contrastive verifier 기법은 복잡한 학습 과정 없이 기존 LLM의 추론 성능을 향상시킬 수 있는 실용적인 경로를 제시한다. 본 연구는 향후 수학, 코딩뿐만 아니라 에이전트 환경(Agentic Reasoning)에서의 비용 효율적인 모델 배포 및 운영에 중요한 시사점을 제공한다.
Figure 3 — 추론 노력 및 지연 시간 감소 효과
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Implicit Reasoning for Large Language Model-based Generative Recommendation
- [논문리뷰] AdaSR: Adaptive Streaming Reasoning with Hierarchical Relative Policy Optimization
- [논문리뷰] Reasoning over Grammar: Can Synthetic Linguistic Reasoning Traces Enhance Low-Resource Machine Translation?
- [논문리뷰] Compress-Distill: Reasoning Trace Compression for Efficient Knowledge Distillation
- [논문리뷰] Latent Reasoning with Normalizing Flows
Review 의 다른글
- 이전글 [논문리뷰] Context Memorization for Efficient Long Context Generation
- 현재글 : [논문리뷰] CopT: Contrastive On-Policy Thinking with Continuous Spaces for General and Agentic Reasoning
- 다음글 [논문리뷰] Delta Attention Residuals
댓글