[논문리뷰] OpenComputer: Verifiable Software Worlds for Computer-Use Agents
링크: 논문 PDF로 바로 열기
메타데이터
저자: Jinbiao Wei, Qianran Ma, Yilun Zhao, Xiao Zhou, Kangqi Ni, Guo Gan, Arman Cohan
1. Key Terms & Definitions (핵심 용어 및 정의)
- Computer-Use Agents: 인간처럼 데스크톱 GUI 환경에서 브라우저, 문서 도구, 개발 환경 등 다양한 애플리케이션을 직접 조작하여 태스크를 수행하는 AI 모델.
- Verifier-Grounded Framework: 스크린샷이나 LLM의 시각적 판단에 의존하지 않고, 애플리케이션의 내부 상태(파일, 데이터베이스, 메타데이터 등)를 프로그램 방식으로 검증하는 체계.
- Self-Evolving Verification Layer: 실행 과정에서 발생하는 피드백을 통해 검증 로직(Verifier)의 오류를 진단하고, 자동화된 루프를 통해 검증기를 정교화하는 프로세스.
- Task-Generation Pipeline: 현실적인 사용자 목표를 기반으로 데스크톱 환경을 구축하고, machine-checkable한 성공 기준을 프로그램적으로 합성하는 체계.
- Evaluation Harness: 에이전트의 수행 과정을 기록하고, 최종 상태를 검증 명령어를 통해 평가하여 partial-credit 보상을 계산하는 평가 환경.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 컴퓨터 사용 에이전트의 훈련과 평가를 저해하는 환경 구축의 어려움과 평가 신뢰성 부족 문제를 해결하기 위해 OpenComputer를 제안한다. 기존 연구들은 환경 구축이 수작업에 의존하여 규모 확장이 어렵고, 최종 성공 여부를 평가할 때 신뢰할 수 없는 LLM-as-a-judge 방식이나 피상적인 스크린샷 확인에 의존한다는 한계가 있다 [1]. 이러한 방식은 복잡한 애플리케이션 상태를 정확하게 판별하지 못하여 평가의 객관성과 재현성을 저해한다. 따라서 본 논문은 검증을 단순히 사후 평가 단계가 아닌, 환경 구축의 핵심 원칙으로 삼는 Verifier-Grounded 접근 방식을 제시한다 [Figure 1].
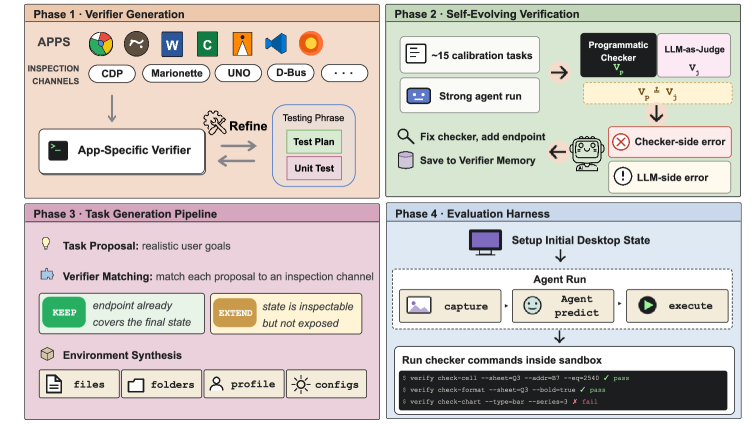
Figure 1 — OpenComputer 파이프라인 전체 구조
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문이 제안하는 OpenComputer는 애플리케이션별 상태 검증기 생성, 실행 기반의 자기 진화 검증 계층, Verifier 기반 태스크 합성, 그리고 구조화된 보상 계산이라는 4단계 프레임워크로 구성된다 [Figure 1]. 저자들은 검증기 개발 시 D-Bus, SQLite, 디버깅 프로토콜 등 안정적인 인터페이스를 활용하며, debug-fix-retry 루프를 통해 검증기의 신뢰성을 보장한다 [Figure 2]. 주요 실험 결과, GPT-5.4가 68.3%의 성공률로 가장 우수한 성능을 보였으나, 여전히 전체 태스크의 약 1/3을 해결하지 못해 데스크톱 워크플로우 자동화가 도전적인 과제임을 입증했다 [Table 2]. 특히, 저자들은 hard-coded verifier가 LLM-as-judge 방식보다 인간의 판단과 훨씬 높은 일치도(97.3% vs 92.2%)를 보임을 입증하였으며, Self-Evolving Verification 계층이 검증기 오류를 89.4%의 수리로 해결하고 human-checker와의 일치도를 크게 향상시킴을 확인하였다 [Figure 3, Table 4].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 33개의 데스크톱 애플리케이션과 1,000개의 태스크로 구성된 OpenComputer 벤치마크를 통해 컴퓨터 사용 에이전트 연구를 위한 신뢰성 있는 인프라를 구축하였다. 이 연구는 성공 기준을 프로그램적으로 검증 가능한 상태에 고정함으로써, 에이전트 실패 모드를 명확히 식별하고 보다 정교한 학습 및 평가 모델을 제시한다. 결과적으로 본 연구는 향후 에이전트가 현실 세계의 복잡한 소프트웨어 환경에서 더욱 견고하고 측정 가능한 방식으로 동작하도록 이끄는 중요한 기반이 될 것이다.

Figure 3 — 인간 판단과 평가 방식 간의 일치도 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] OpenCUA: Open Foundations for Computer-Use Agents
- [논문리뷰] OSWorld2.0: Benchmarking Computer Use Agents on Long-Horizon Real-World Tasks
- [논문리뷰] MyPCBench: A Benchmark for Personally Intelligent Computer-Use Agents
- [논문리뷰] AgentHazard: A Benchmark for Evaluating Harmful Behavior in Computer-Use Agents
- [논문리뷰] CUA-Suite: Massive Human-annotated Video Demonstrations for Computer-Use Agents
Review 의 다른글
- 이전글 [논문리뷰] OmniGUI: Benchmarking GUI Agents in Omni-Modal Smartphone Environments
- 현재글 : [논문리뷰] OpenComputer: Verifiable Software Worlds for Computer-Use Agents
- 다음글 [논문리뷰] Overcoming Catastrophic Forgetting in Visual Continual Learning with Reinforcement Fine-Tuning
댓글