[논문리뷰] When Vision Speaks for Sound
링크: 논문 PDF로 바로 열기
메타데이터
저자: Xiaofei Wen, Wenjie Jacky Mo, Xingyu Fu, Rui Cai, Tinghui Zhu, Wendi Li, Yanan Xie, Muhao Chen, Peng Qi
1. Key Terms & Definitions (핵심 용어 및 정의)
- Clever Hans Effect: 모델이 실제 오디오-비주얼 정보를 교차 검증하지 않고, 시각적 단서(Visual Cues)와 언어적 Prior를 이용해 정답인 것처럼 연기하는 현상을 지칭합니다.
- Thud (Temporal and Hallucination Unmasking Diagnostics): 오디오-비주얼 데이터의 자연스러운 상관관계를 강제로 제거(Shift, Mute, Swap)하여 모델의 실질적인 오디오 이해 능력을 검증하는 진단 프레임워크입니다.
- Shift/Mute/Swap Interventions: 모델의 오디오-비주얼 grounding을 측정하기 위한 세 가지 핵심 개입 방식입니다. Shift는 시간적 동기화(Temporal Synchronization), Mute는 사운드 존재 여부(Audio Existence), Swap은 물리적 일관성(Sound Consistency)을 검증합니다.
- Alignment Tax: 특정 과업(예: 시간적 동기화)을 위해 모델을 학습시킬 때, 기존의 일반적인 비디오 이해 능력(General Video Understanding)이 저하되는 부작용을 의미합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 최신 Video-LLMs가 오디오 이해 능력을 갖춘 것처럼 보이지만, 실제로는 오디오를 검증하지 않고 시각적 단서에서 사운드를 추론하거나 할루시네이션(Hallucination)을 일으키는 Clever Hans effect에 빠져 있음을 지적합니다 [Figure 1]. 기존의 비디오 이해 벤치마크는 데이터셋 자체에 강력한 오디오-비주얼 상관관계(예: 깨지는 유리잔 영상에는 반드시 깨지는 소리가 포함됨)가 존재하여, 모델이 사운드 스트림을 확인하지 않고도 높은 성능을 기록하는 한계가 있습니다. 따라서 단순히 naturally correlated 데이터를 학습하는 것이 아니라, 오디오-비주얼 대응 관계를 인위적으로 파괴하는 intervention-driven 방식의 새로운 진단 프레임워크가 필요합니다 [Figure 2].
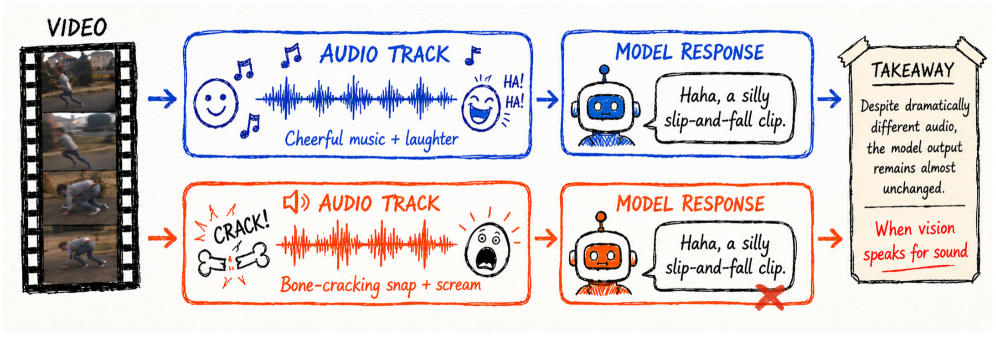
Figure 1 — Clever Hans 효과 예시
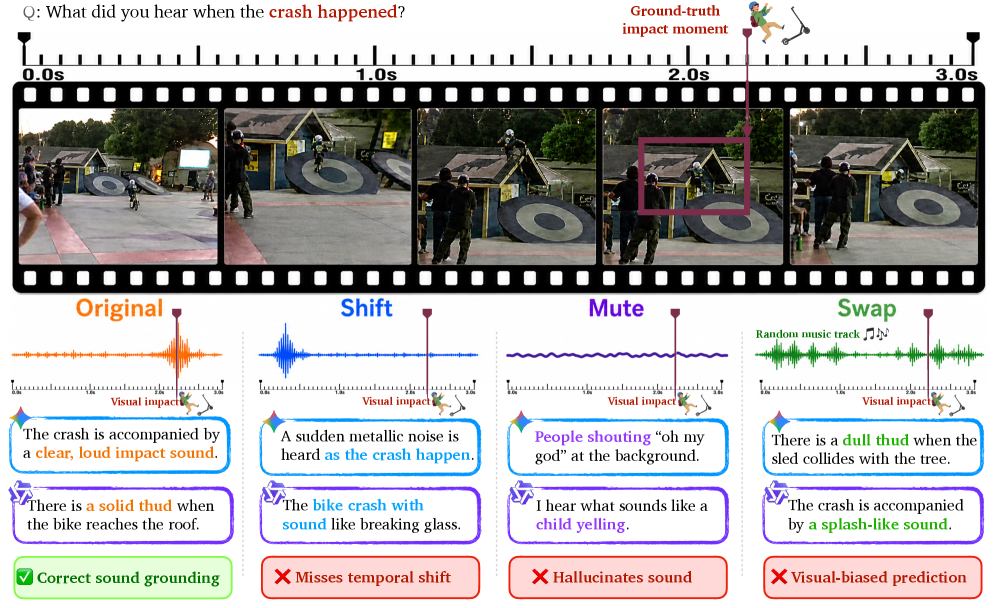
Figure 2 — 3가지 개입 실패 사례
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 Thud 프레임워크를 통해 모델의 오디오-비주얼 grounding 실패를 정량화하고, Direct Preference Optimization (DPO) 기반의 2단계 정렬(Alignment) 기법을 제안합니다 [Figure 9]. 1단계에서는 intervention으로 파생된 preference pairs를 사용하여 SFT(Supervised Fine-Tuning) 웜업을 진행하고, 2단계에서는 이를 일반적인 비디오 instruction 데이터와 혼합하여 Alignment Tax를 최소화합니다 [Figure 10]. 실험 결과, 제안된 10K-sample 레시피를 적용한 모델은 Shift, Mute, Swap intervention 전반에서 vanilla 모델 대비 28% 포인트 향상된 성능을 기록하였습니다 [Table 2]. 특히 Sync 벤치마크에서는 기존 34.3%에서 83.1%로 비약적인 grounding 성능 향상을 보였으며, 일반적인 비디오 이해 벤치마크(V-MME, LVB 등) 성능 또한 유지하거나 개선되었습니다 [Figure 6].
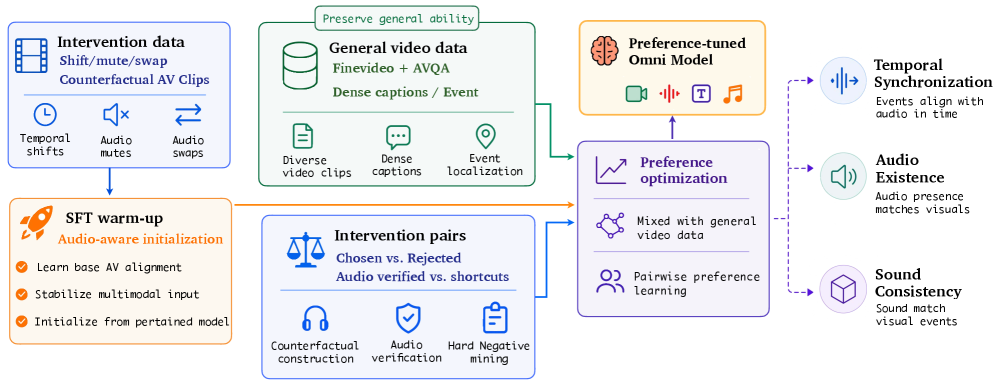
Figure 10 — 2단계 정렬 파이프라인
4. Conclusion & Impact (결론 및 시사점)
본 논문은 현대 Video-LLMs의 오디오-비주얼 이해 능력이 시각적 단서에 지나치게 의존하고 있음을 밝히고, 이를 해결하기 위한 구체적인 intervention-driven 학습 프레임워크를 제시합니다. 본 연구에서 제안한 Thud 프로토콜과 정렬 레시피는 향후 오디오-비주얼 grounding을 측정하고 강화하는 연구의 표준 지표가 될 것으로 기대됩니다. 이는 단순히 aggregate accuracy에 의존하던 기존 평가 방식을 넘어서, 모델이 실제 오디오 스트림을 얼마나 정확하게 동기화하고 검증하는지를 측정하는 새로운 연구 방향성을 제시한다는 점에서 학계와 산업계에 큰 시사점을 줍니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Aligning Quantum Operators with Large Language Models
- [논문리뷰] EarlyTom: Early Token Compression Completes Fast Video Understanding
- [논문리뷰] CoHyDE: Iterative Co-Training of LLM Rewriter & Dense Encoder for Tool Retrieval
- [논문리뷰] Advancing Creative Physical Intelligence in Large Multimodal Models
- [논문리뷰] Semantic Generative Tuning for Unified Multimodal Models
Review 의 다른글
- 이전글 [논문리뷰] Video Models Can Reason with Verifiable Rewards
- 현재글 : [논문리뷰] When Vision Speaks for Sound
- 다음글 [논문리뷰] Where Does Authorship Signal Emerge in Encoder-Based Language Models?
댓글