[논문리뷰] IndusAgent: Reinforcing Open-Vocabulary Industrial Anomaly Detection with Agentic Tools
링크: 논문 PDF로 바로 열기
저자: Rongbin Tan, Fangfang Lin, Zhenlong Yuan, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- IndusAgent: 산업 현장의 이상 탐지(Industrial Anomaly Detection, IAD)를 위해 제안된 MLLM 기반 에이전트 프레임워크로, 도구 활용과 강화학습을 통해 진단 정확도를 향상시킵니다.
- Indus-CoT: 글로벌 시각 정보, 고해상도 로컬 패치, 전문가 normalcy prior를 통합하여 학습에 활용하는 구조화된 추론 데이터셋입니다.
- Accuracy-Gated Reward: RL 학습 시 최종 진단이 정확할 때만 도구 사용 보상을 부여하여 도구 오남용(tool abuse)을 방지하는 핵심 보상 메커니즘입니다.
- GRPO (Group Relative Policy Optimization): 가치 네트워크 없이 그룹 단위의 상대적 비교를 통해 정책을 업데이트하는 강화학습 알고리즘으로, 계산 효율성을 최적화합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 MLLM의 강력한 제로샷 성능에도 불구하고, 고도의 정밀함이 요구되는 산업 환경에서 도메인 불일치 및 구조적 환각(structural hallucination)으로 인해 발생하는 이상 탐지 성능 저하 문제를 해결합니다 [Figure 1]. 기존 연구(Baseline)들은 대부분 닫힌 집합(closed-set) 가정에 갇혀 있거나, 수동적인 추론에 의존하여 미세한 결함을 탐지하지 못하는 한계가 있습니다. 새로운 접근 방식은 모델이 능동적으로 도구를 사용하여 시각적 모호함을 해결하고, 구조화된 진단 과정을 통해 논리적 일관성을 유지하는 에이전트 프레임워크가 필요함을 시사합니다 [Figure 1].
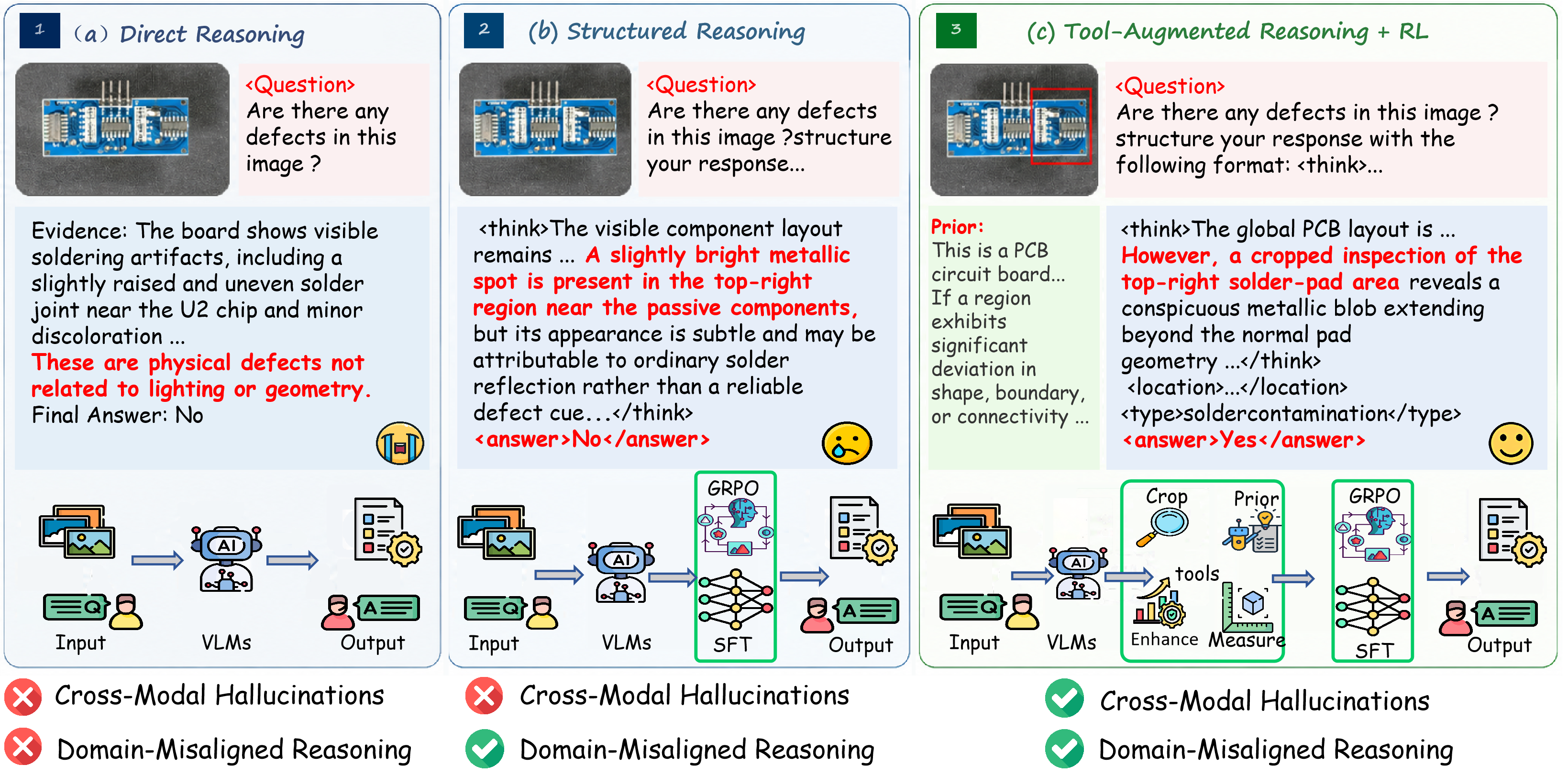
Figure 1 — 기존 모델과 제안 모델 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 산업용 이상 탐지를 능동적 추론 과정으로 재정의하고, IndusAgent 프레임워크를 제안합니다 [Figure 2]. 첫째, Indus-CoT 데이터셋을 구축하여 모델이 다단계 추론과 도구 호출을 수행하도록 Supervised Fine-Tuning(SFT)을 진행합니다. 둘째, Accuracy-Gated Reward를 포함한 GRPO를 통해 에이전트의 도구 사용 정책을 최적화합니다. 도구 라이브러리는 T_crop, T_prior, T_enhance, T_measure로 구성되어 시각적 명확성을 보완합니다 [Figure 2]. 실험 결과, IndusAgent는 MVTec, VisA 등 5개 벤치마크에서 기존 최고 수준 모델들을 크게 상회하며, 특히 MVTec 데이터셋에서 SOTA 대비 9.3%의 성능 향상을 기록했습니다 [Table 1]. 또한, Accuracy-Gated Reward 설계를 통해 도구 호출을 통한 진단 정확도 개선과 정보 획득 비용 간의 최적 균형을 입증하였습니다 [Table 4].
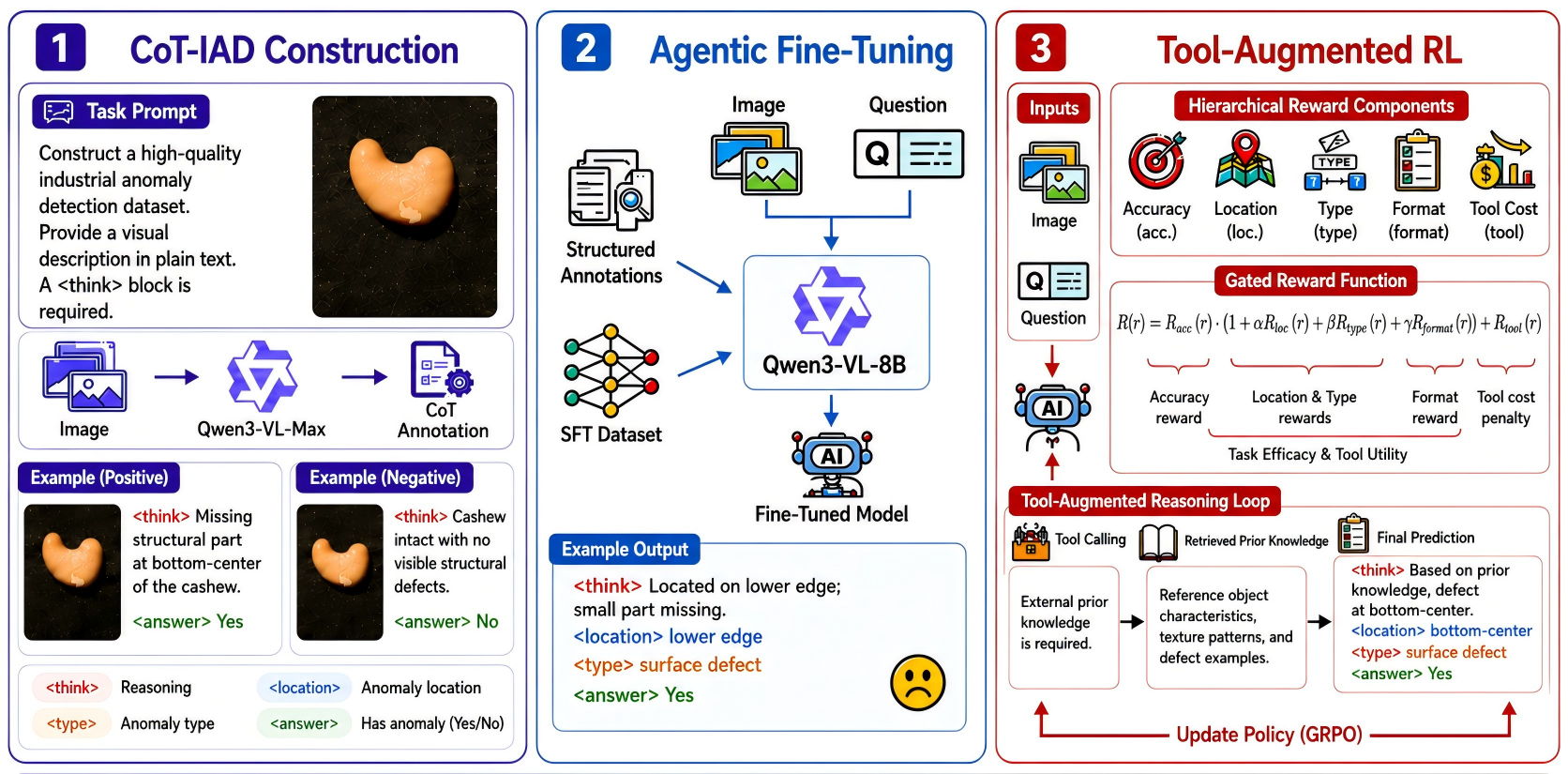
Figure 2 — IndusAgent의 전체 아키텍처
4. Conclusion & Impact (결론 및 시사점)
본 연구는 도메인 특화 진단 프로토콜과 강화학습을 결합하여 산업 현장에 특화된 제로샷 이상 탐지 에이전트의 새로운 패러다임을 제시하였습니다. 특히, 무분별한 도구 호출을 제어하는 정확도 기반 보상 메커니즘은 신뢰성 있는 산업용 자동화 시스템을 위한 중요한 기술적 진보로 평가받습니다. 이 연구는 향후 컴퓨팅 자원이 제한된 엣지 환경이나 다중 모달 temporal 스트림으로 에이전트의 활동 범위를 확장할 수 있는 토대를 마련했다는 점에서 학술적 및 산업적 가치가 큽니다.
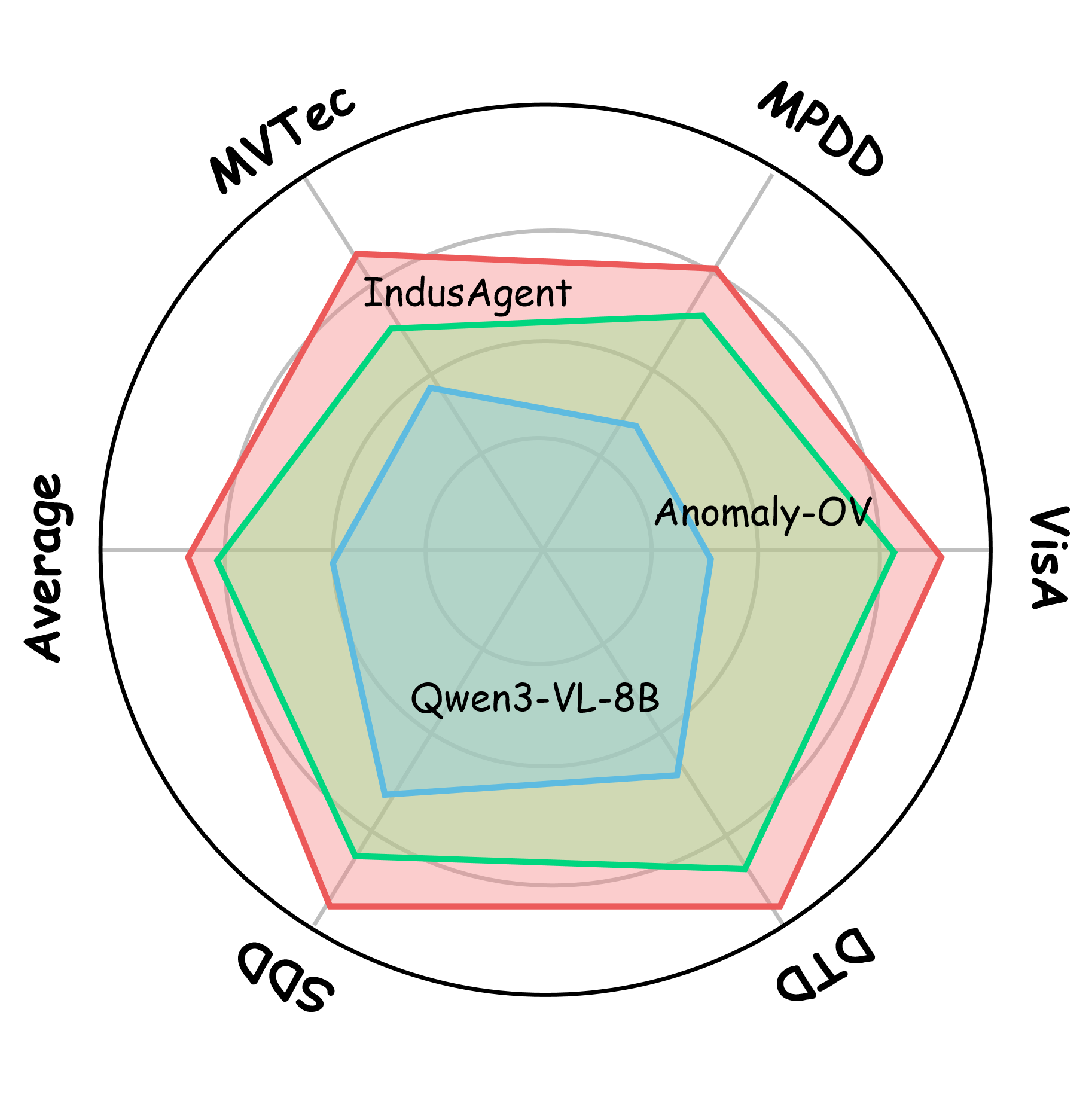
Figure 3 — 제로샷 성능 비교 결과
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Detect Anything via Next Point Prediction
- [논문리뷰] Breaking Failure Cascades: Step-Aware Reinforcement Learning for Medical Multimodal Reasoning
- [논문리뷰] MechVQA: Benchmarking and Enhancing Multimodal LLMs on Comprehensive Mechanical Drawing Understanding
- [논문리뷰] Imagine Before You Predict: Interleaved Latent Visual Reasoning for Video Event Prediction
- [논문리뷰] Eliciting Complex Spatial Reasoning in MLLMs through Wide-Baseline Matching
Review 의 다른글
- 이전글 [논문리뷰] HRM-Text: Efficient Pretraining Beyond Scaling
- 현재글 : [논문리뷰] IndusAgent: Reinforcing Open-Vocabulary Industrial Anomaly Detection with Agentic Tools
- 다음글 [논문리뷰] It Takes Two: Complementary Self-Distillation for Contextual Integrity in LLMs
댓글