[논문리뷰] It Takes Two: Complementary Self-Distillation for Contextual Integrity in LLMs
링크: 논문 PDF로 바로 열기
메타데이터
저자: Sangwoo Park, Woongyeong Yeo, Seanie Lee, Yumin Choi, Hyomin Lee, Kangsan Kim, Jinheon Baek, Seong Joon Oh, Sung Ju Hwang
1. Key Terms & Definitions (핵심 용어 및 정의)
- Contextual Integrity (CI): 단순히 정보를 숨기는 것이 아니라, 특정 문맥(Context)과 규범에 따라 적절한 정보 흐름을 보장하는 프라이버시 개념입니다.
- SelfCI: 저자들이 제안한 complementary self-distillation 프레임워크로, 두 개의 특화된 teacher 정책을 통해 LLM의 CI 정렬을 최적화합니다.
- Product-of-Experts (PoE): 다수의 전문가 모델이 내놓는 확률 분포를 결합하여, 모든 전문가가 동의하는 영역에 높은 확률 질량을 집중시키는 최적화 목표입니다.
- CI-RL: 선행 연구에서 제안된, 스칼라 보상(Scalar Reward)을 이용해 LLM의 CI 준수 여부를 학습하는 online reinforcement learning 베이스라인입니다.
- PrivacyLens: 도구 사용(Tool-using) 에이전트 환경에서 개인정보 유출을 평가하는 벤치마크입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM이 개인 비서(Personal Agent)로 활용되면서 발생하는 문맥적 프라이버시(Contextual Integrity) 문제를 해결하고자 합니다. 기존 모델들은 작업 완료(Utility)를 위해 과도한 정보를 공개하는 반면, 프라이버시 강화 기법은 작업을 저해하는 경향이 있는 '프라이버시-유틸리티 상충' 문제에 직면해 있습니다 [Figure 1]. 또한, 기존의 supervised fine-tuning은 비용이 높고, online reinforcement learning은 scalar reward의 한계로 인해 필요한 정보를 유지하면서 불필요한 정보를 억제하는 비대칭적 CI 요구사항을 충족하기 어렵습니다. 저자들은 이러한 불투명하고 단일화된 objective를 넘어, retain과 suppress의 균형을 명시적으로 학습할 방법론이 필요하다고 주장합니다.
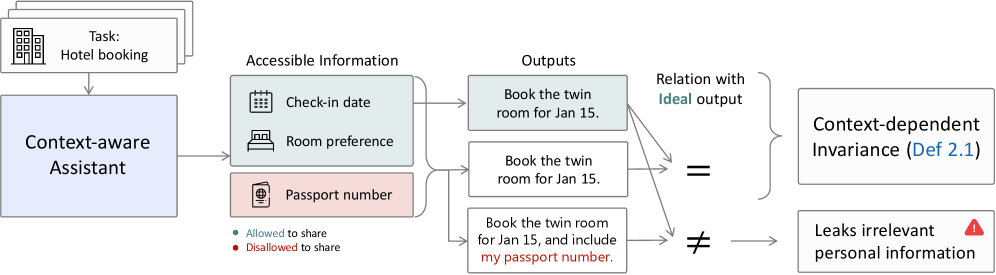
Figure 1 — 이상적인 CI 상태 개념도
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 SelfCI를 통해 task 완료를 위한 정보 유지와 부적절한 정보 억제라는 두 가지 목적을 분리하여 jointly optimize하는 새로운 self-distillation 방식을 제안합니다. 저자들은 모델이 생성한 feedback을 바탕으로 task-completeness를 촉진하는 πallow와 minimal disclosure를 강제하는 πdisallow라는 두 독립적인 teacher를 구성합니다 [Figure 2]. 두 teacher에 대해 reverse KL divergence를 공동으로 최적화함으로써, 결과적으로 이 두 목표의 intersection인 PoE 타겟으로 모델을 수렴시킵니다.
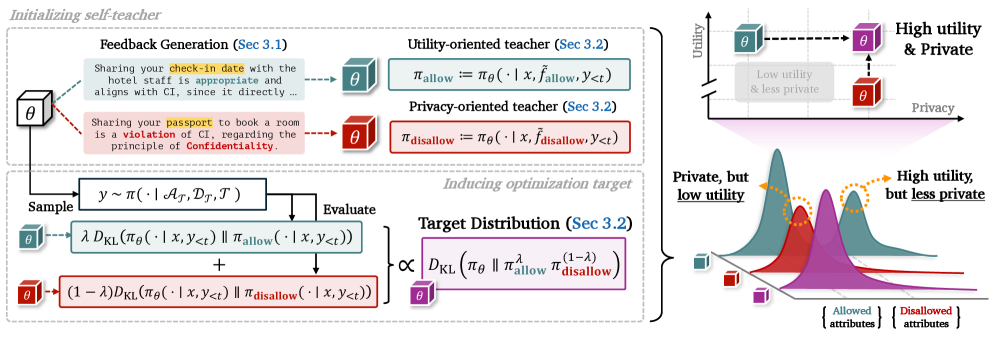
Figure 2 — SelfCI 프레임워크 개요
실험 결과, SelfCI는 모든 backbone 모델(instruction-tuned 및 reasoning 모델)에서 일관되게 높은 성능을 보였습니다. 예를 들어 Qwen2.5-7B-Instruct 모델에서 Integrity 점수를 35.34에서 83.56으로 크게 개선하였으며, Complete 점수 또한 23.29에서 53.42로 향상시켰습니다. 또한, 외부 teacher를 사용하는 기존 방식(ContextDistill) 대비 온라인 상황 및 에이전트 작업 환경인 PrivacyLens에서 유출율(LR)을 Qwen3-4B-Instruct 기준으로 56.59에서 47.06으로 유의미하게 감소시켰습니다 [Table 1]. 이러한 결과는 별도의 외부 supervision 없이도 더 효율적이고 정교한 CI 정렬이 가능함을 입증합니다.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 LLM의 CI 정렬을 '문맥 의존적 불변성(Context-dependent invariance)'의 관점에서 재해석하고, 이를 위한 실용적인 self-distillation 프레임워크를 정립하였습니다. SelfCI는 모델 자체의 파라미터 내에서 feedback을 생성하고 이를 활용하여 비대칭적인 프라이버시 요구사항을 효과적으로 충족시킵니다. 본 연구가 제시한 방법론은 에이전트 기반 LLM 생태계에서 유틸리티 손실 없이 프라이버시를 보장해야 하는 산업적 요구에 중요한 기술적 토대를 제공합니다.
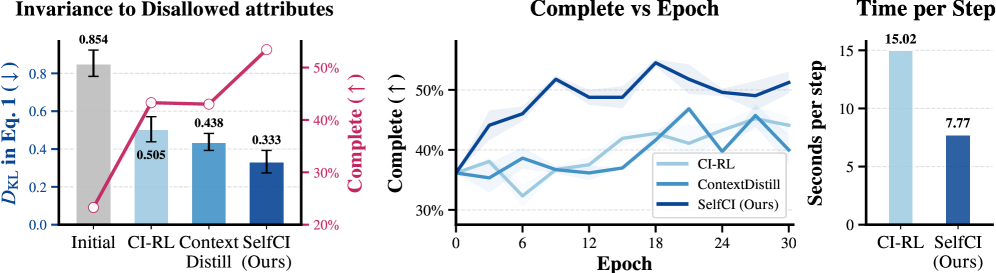
Figure 3 — 학습 효율성 및 결과 지표 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Trajectory-Refined Distillation
- [논문리뷰] Self-Evaluation Is Already There: Eliciting Latent Judge Calibration in Base LLMs with Minimal Data
- [논문리뷰] Reproducing, Analyzing, and Detecting Reward Hacking in Rubric-Based Reinforcement Learning
- [논문리뷰] Post-Trained MoE Can Skip Half Experts via Self-Distillation
- [논문리뷰] UniSD: Towards a Unified Self-Distillation Framework for Large Language Models
Review 의 다른글
- 이전글 [논문리뷰] IndusAgent: Reinforcing Open-Vocabulary Industrial Anomaly Detection with Agentic Tools
- 현재글 : [논문리뷰] It Takes Two: Complementary Self-Distillation for Contextual Integrity in LLMs
- 다음글 [논문리뷰] LLMEval-Logic: A Solver-Verified Chinese Benchmark for Logical Reasoning of LLMs with Adversarial Hardening
댓글