[논문리뷰] Self-Evaluation Is Already There: Eliciting Latent Judge Calibration in Base LLMs with Minimal Data
링크: 논문 PDF로 바로 열기
메타데이터
저자: XiuYu Zhang, Yi Shan, Junfeng Fang, Zhenkai Liang
1. Key Terms & Definitions (핵심 용어 및 정의)
- SEE (Self-Evaluation Elicitation): 본 논문에서 제안하는 방법론으로, Base LLM이 이미 잠재적으로 보유하고 있는 평가 능력을 최소한의 데이터로 표출(Elicit)하는 순환적 학습 과정입니다.
- Calibration-Coupled RL: 답변의 품질을 높이는 동시에 LLM이 생성한
[SELF_EVAL]블록의 점수와 외부 Judge의 점수 간의 일치도를 보상하는 RL 기반 학습 단계입니다. - Masked Judge Distillation: 답변 자체는 유지하면서
[SELF_EVAL]토큰에만 Judge의 실제 점수를 학습시켜 예측 정확도를 최적화하는 감독 학습(Supervised Fine-tuning) 단계입니다. - HelpSteer2: 본 연구에서 다루는 helpfulness, correctness, coherence, complexity, verbosity 5가지 속성을 정의하고 점수화하는 데 사용된 다중 속성 데이터셋입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM이 외부 Judge의 평가를 사전에 예측하여 스스로 자신의 답변을 재평가하거나 선별할 수 있는지에 대한 근본적인 의문을 탐구합니다. 기존 연구들은 주로 수학이나 코딩과 같은 검증 가능한(Verifiable) 영역에서의 정답 예측에 집중해 왔으며, 오픈 도메인 환경에서 다중 속성(Multi-attribute) 점수를 예측하는 능력의 발현 여부는 불분명했습니다. 저자들은 이러한 능력이 타겟 학습(Targeted training) 전에도 Base 모델 내부에 이미 잠재되어 있음을 발견하였습니다 [Figure 1]. 따라서 본 연구는 고비용의 학습 대신, 모델의 잠재적 평가 능력을 표출(Elicitation)하는 것에 초점을 맞춥니다.
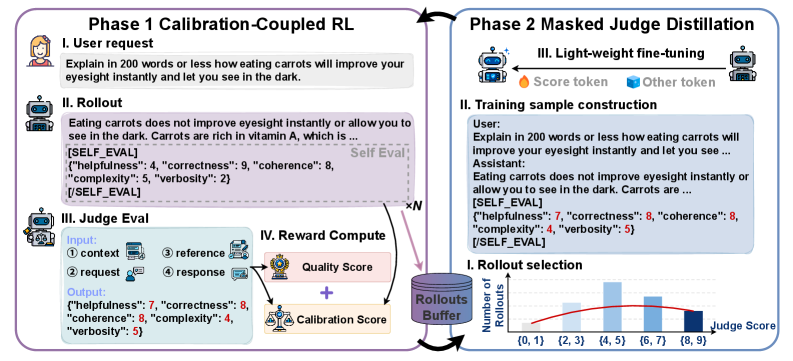
Figure 1 — SEE cycle의 전체 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Calibration-Coupled RL과 Masked Judge Distillation을 교차 반복하는 SEE cycle을 제안합니다 [Figure 1]. 이 방법론은 RL을 통해 답변 품질과 평가 일치도를 개선한 뒤, distillation을 통해 예측 오차를 정밀하게 교정하여 답변의 왜곡 없이도 자기 평가 기능을 강화합니다. 실험 결과, 제안된 SEE는 Adapted RLCR baseline 대비 약 31배 적은 데이터(160개의 고유 샘플)만으로도 우수한 성능을 보였습니다 [Table 2]. 특히 WildBench v2에서 calibration 성능을 기존 0.504에서 0.608로 크게 향상시켰으며, 답변 품질 또한 유지하거나 미세하게 개선하는 효과를 확인했습니다 [Table 1]. 또한, 학습에 사용하지 않은 타 Judge(Claude Sonnet, Gemini 등)를 대상으로도 일관된 품질 개선 효과를 입증하며 강건한 일반화 능력을 보였습니다 [Table 3].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 LLM의 자기 평가 능력이 모델 학습 과정에서 새롭게 주입되는 것이 아니라, 사전 학습(Pretraining)을 통해 이미 형성된 능력을 표출(Elicitation)하는 과정임을 증명하였습니다. 이러한 관점의 전환은 고비용의 사후 학습(Post-training) 과정을 저비용의 효율적 학습으로 대체할 수 있는 가능성을 제시합니다. 이 연구는 모델이 스스로 자신의 품질을 인지하고 예측할 수 있게 함으로써, 추론 단계에서 Judge 호출을 최소화하고 독립적으로 품질을 관리할 수 있는 자율적인 LLM 개발에 중요한 시사점을 제공합니다.
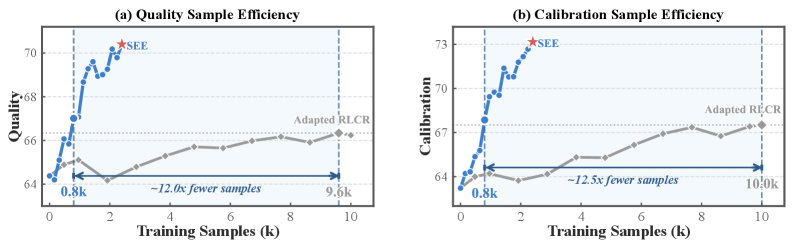
Figure 2 — 샘플 효율성 비교 분석
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Reproducing, Analyzing, and Detecting Reward Hacking in Rubric-Based Reinforcement Learning
- [논문리뷰] Judging with Confidence: Calibrating Autoraters to Preference Distributions
- [논문리뷰] N-GRPO: Embedding-Level Neighbor Mixing for Enhanced Policy Optimization
- [논문리뷰] Retrospective Harness Optimization: Improving LLM Agents via Self-Preference over Trajectory Rollouts
- [논문리뷰] How Does Reasoning Flow? Tracing Attention-Induced Information Flow for Targeted RL in LLMs
Review 의 다른글
- 이전글 [논문리뷰] SWE-Explore: Benchmarking How Coding Agents Explore Repositories
- 현재글 : [논문리뷰] Self-Evaluation Is Already There: Eliciting Latent Judge Calibration in Base LLMs with Minimal Data
- 다음글 [논문리뷰] SigmaScale: LLM Compression with SVD-based Low-Rank Decomposition and Learned Scaling Matrices
댓글