[논문리뷰] SWE-Explore: Benchmarking How Coding Agents Explore Repositories
링크: 논문 PDF로 바로 열기
메타데이터
저자: Shaoqiu Zhang, Yuhang Wang, Jialiang Liang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- SWE-Explore: 리포지토리 내에서 문제 해결에 필요한 코드 영역을 탐색하는 능력을 평가하기 위해 제안된 새로운 벤치마크 프레임워크입니다.
- Ranked Region List: 탐색기(Explorer)가 이슈 해결을 위해 중요하다고 판단하여 반환하는 파일 경로와 라인 범위를 포함한 순위가 매겨진 리스트입니다.
- Trajectory-grounded Supervision: 실제 문제를 성공적으로 해결한 에이전트의 수행 경로에서 추출한 데이터를 바탕으로 구축된 라인 단위의 Ground Truth입니다.
- Restricted-context Validation: 탐색기가 선택한 코드 영역만을 에이전트에게 제공하여, 해당 정보가 실제 문제 해결(수정)에 유효한지 검증하는 사후 평가 프로토콜입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 SWE-bench와 같은 벤치마크가 이슈 해결 여부를 이분법적(성공/실패)으로만 판단하여, 에이전트의 내부적인 탐색, 위치 파악, 맥락 추출 능력을 측정하지 못하는 문제를 해결하고자 합니다 [Figure 1]. 기존 연구들은 방대한 리포지토리에서 버그의 원인이 되는 정확한 코드 라인을 찾아내는 능력을 제대로 평가하지 못하며, 이는 에이전트가 탐색에 실패했는지 혹은 패치 생성 단계에서 실패했는지 구분하기 어렵게 만듭니다. 저자들은 이러한 Repository Exploration 과정을 독립적인 평가 타겟으로 설정하고, 라인 단위의 상세한 분석이 가능한 환경을 구축하고자 합니다.
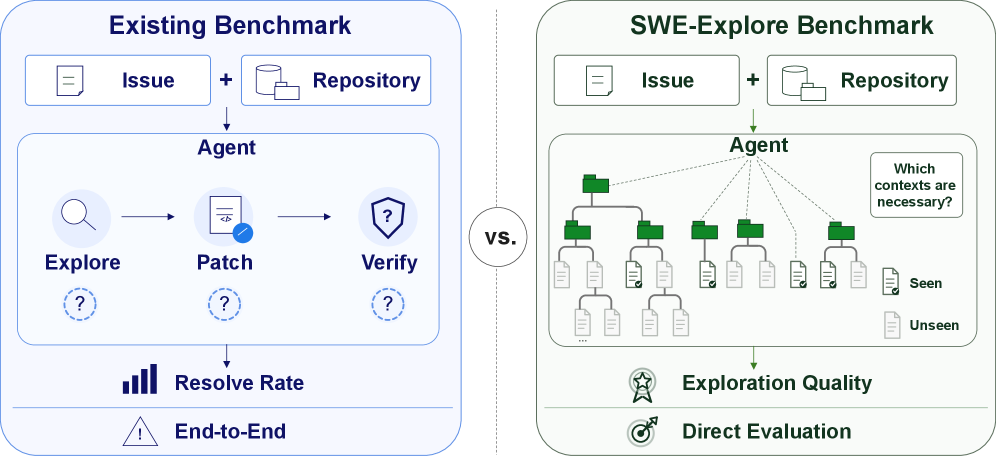
Figure 1 — SWE-Explore의 연구 동기
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 성공적인 에이전트 수행 경로를 통해 자동으로 라인 단위의 Ground Truth를 추출하고, 이를 기반으로 탐색기의 품질을 측정하는 SWE-Explore를 제안합니다 [Figure 2]. 탐색기는 정해진 라인 예산 내에서 가장 관련성이 높은 코드 영역 리스트를 순위별로 생성하며, 시스템은 이를 정밀도(Precision), 재현율(Recall), nDCG@500, 그리고 탐색 효율성 지표인 Context Efficiency 등으로 평가합니다 [Table 6]. 실험 결과, Agentic Explorers는 고전적인 검색 방식(TF-IDF, BM25 등) 대비 훨씬 우수한 성능을 보였으며, 특히 Context Efficiency와 FUH (First Useful Hit)가 실제 다운스트림 패치 성공률과 가장 높은 상관관계를 보임을 확인했습니다 [Table 4]. 또한, LLM의 모델 성능이 향상됨에 따라 탐색 품질도 전반적으로 개선되나, 여전히 라인 단위의 정밀한 탐색은 최신 에이전트들에게도 주요한 병목 구간으로 남아있음을 정량적으로 증명했습니다 [Table 5].
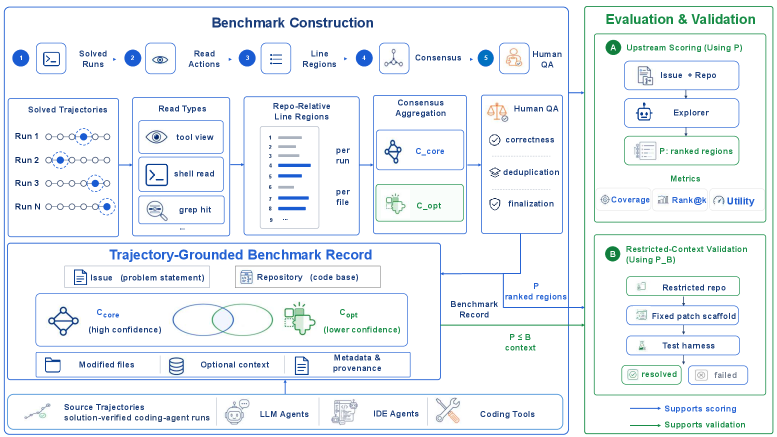
Figure 2 — SWE-Explore 전체 아키텍처
4. Conclusion & Impact (결론 및 시사점)
본 연구는 코드 생성 에이전트의 핵심 능력인 리포지토리 탐색을 라인 수준에서 정밀하게 측정하는 새로운 기준을 마련했습니다. SWE-Explore는 단순히 패치의 성공 여부만을 보는 것에서 벗어나, 에이전트가 어떤 코드 영역을, 얼마나 효율적으로 탐색했는지를 평가함으로써 탐색기 개발의 방향성을 제시합니다. 향후 본 벤치마크는 더욱 효율적인 컨텍스트 관리 기법과 고도화된 코드 탐색 전략을 개발하는 데 중요한 도구로 활용될 것으로 기대됩니다.

Figure 4 — 데이터 예시 및 탐색 타겟
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] SWE-chat: Coding Agent Interactions From Real Users in the Wild
- [논문리뷰] Qwen3-Coder-Next Technical Report
- [논문리뷰] SWE-EVO: Benchmarking Coding Agents in Long-Horizon Software Evolution Scenarios
- [논문리뷰] NL2Repo-Bench: Towards Long-Horizon Repository Generation Evaluation of Coding Agents
- [논문리뷰] A Survey of Vibe Coding with Large Language Models
Review 의 다른글
- 이전글 [논문리뷰] Reasoning over Grammar: Can Synthetic Linguistic Reasoning Traces Enhance Low-Resource Machine Translation?
- 현재글 : [논문리뷰] SWE-Explore: Benchmarking How Coding Agents Explore Repositories
- 다음글 [논문리뷰] Self-Evaluation Is Already There: Eliciting Latent Judge Calibration in Base LLMs with Minimal Data
댓글