[논문리뷰] LLMEval-Logic: A Solver-Verified Chinese Benchmark for Logical Reasoning of LLMs with Adversarial Hardening
링크: 논문 PDF로 바로 열기
저자: Ming Zhang, Qiyuan Peng, et al.
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- Forward Authoring: 기존 템플릿 기반의 문제 생성 방식에서 벗어나, 논리적 구조를 자연어 시나리오에 직접 설계하고 전문가가 검수하는 방식.
- Z3: 문제의 premises와 query를 논리적으로 검증하기 위해 사용하는 SMT solver로, 본 논문에서는 NL-to-FL 변환의 정합성과 정답의 논리적 타당성을 인증하는 데 사용됨.
- Adversarial Hardening: 모델이 단순한 패턴 매칭이나 표면적 단서(surface cues)에 의존하는 것을 방지하기 위해, 폐쇄 루프 에이전트 워크플로우를 통해 문제를 재구성하여 난이도를 높이는 기법.
- NL-to-FL (Natural Language to Formal Logic): 자연어 논리 문제를 정형화된 논리식으로 변환하는 과정으로, 모델의 추론 능력을 평가하는 핵심 지표임.
- Expert-Developed Rubrics: NL-to-FL 변환의 충실도를 평가하기 위해 논리 관계(Logical Relation), 명시적 제약(Stated Constraint), 질의 정렬(Query Alignment) 단위로 구성된 전문가 평가 지표.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 LLM의 자연어 논리 추론 능력을 평가하는 기존 벤치마크들이 겪고 있는 한계를 극복하기 위해 LLMEval-Logic을 제안한다 [Figure 2]. 기존 연구들은 주로 템플릿 기반으로 문제를 생성하여 분포적 인위성(distributional artifacts)이 발생하며, frontier LLM들이 표면적 단서를 통해 논리적 추론 없이 정답을 맞히는 'Shortcut' 문제를 해결하지 못하고 있다. 또한, 최종 정답만을 평가하는 방식으로는 모델이 생성한 formalization의 논리적 충실도를 검증할 수 없다는 문제가 존재한다. 이에 따라, 보다 정교하고 난이도가 높은 논리적 reasoning 능력을 변별할 수 있는 새로운 평가 프레임워크가 요구된다.
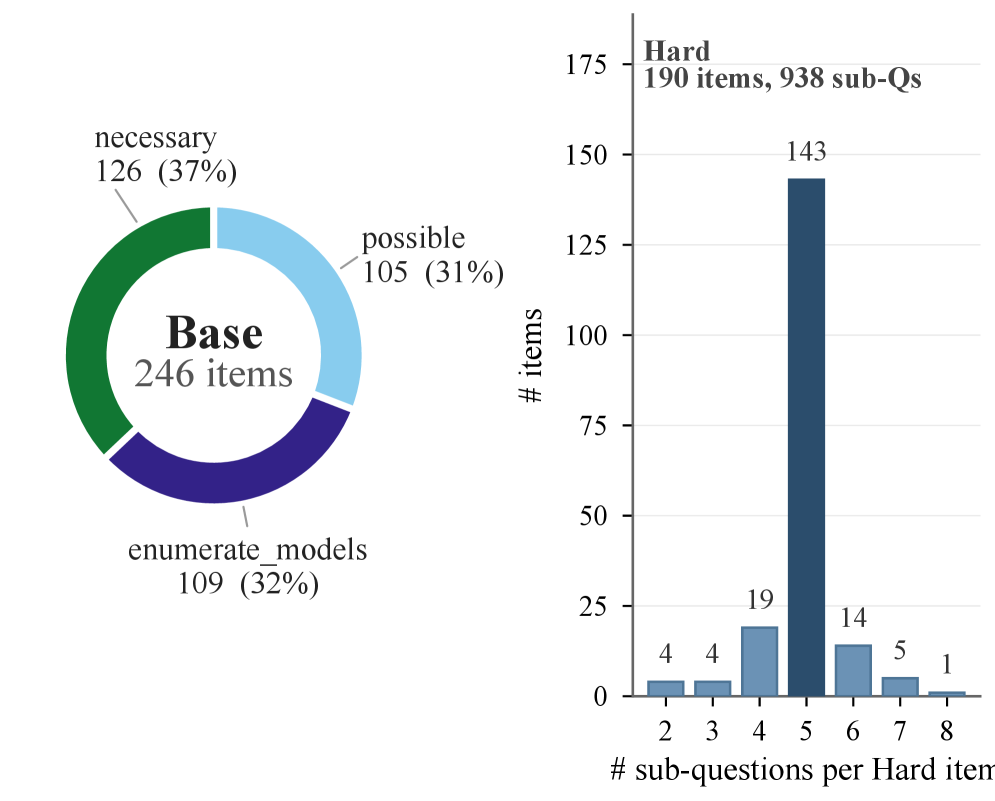
Figure 2 — LLMEval-Logic 파이프라인 개요
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 저자들은 세 단계의 검증된 파이프라인을 통해 LLMEval-Logic을 구축하였다. 첫째, 전문가들이 논리적 구조가 내재된 현실적 시나리오를 설계하고 Z3 solver를 사용하여 정답을 인증하였다. 둘째, 모델이 생성한 formalization을 평가하기 위해 논리적 원자 단위의 Expert-Developed Rubrics를 도입하였다. 셋째, 모델이 쉽게 해결하는 문제를 선별하여 5가지 에이전트 역할과 6가지 hardening 전략으로 구성된 폐쇄 루프 워크플로우를 통해 난이도를 극한으로 높인 Hard subset을 구축하였다 [Figure 3].
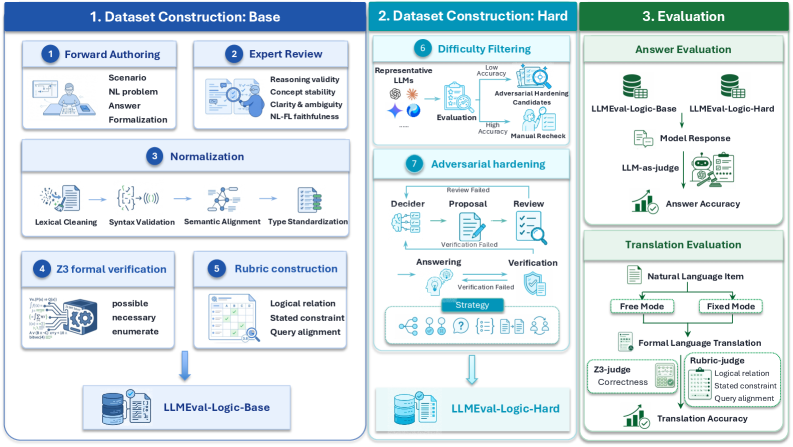
Figure 3 — LLMEval-Logic 데이터셋 구성
실험 결과, 14개의 frontier LLM을 평가한 결과 최고 성능 모델조차 Hard Item Accuracy에서 37.5%에 불과한 낮은 성능을 보였다 [Table 1]. 또한, Z3 실행 결과와 Rubric 점수를 결합한 지표를 통해 평가했을 때, 고정된 기호(fixed symbols)를 제공함에도 불구하고 모델들의 최고 점수는 60.16%에 그쳤다. 이는 모델들이 정답을 맞히더라도 논리적 formalization 과정에서 의미론적 오류를 범하고 있음을 시사한다. 이러한 결과는 Base와 Hard subset 간의 성능 격차가 큼을 보여주며, 현재의 frontier LLM들이 여전히 다단계 논리 추론 및 폐쇄적 후보 공간 유지(closed candidate space maintenance)에 취약함을 정량적으로 입증한다 [Table 1].
## 4. Conclusion & Impact (결론 및 시사점) 본 연구는 고품질의 Z3 검증 문제와 적대적 강화(adversarial hardening) 기법을 결합하여, LLM의 논리적 추론 능력을 다각도로 평가할 수 있는 LLMEval-Logic 벤치마크를 제시하였다. 연구 결과는 기존의 단순 정답 맞히기 위주의 평가가 모델의 추론 한계를 은폐하고 있음을 드러내며, NL-to-FL 변환의 정밀한 평가가 모델의 신뢰성을 확보하는 데 필수적임을 시사한다. 이 벤치마크는 학계와 산업계가 LLM의 진정한 reasoning 성능을 구분하고 더 안전하고 신뢰할 수 있는 모델을 개발하는 데 중요한 이정표가 될 것이다.
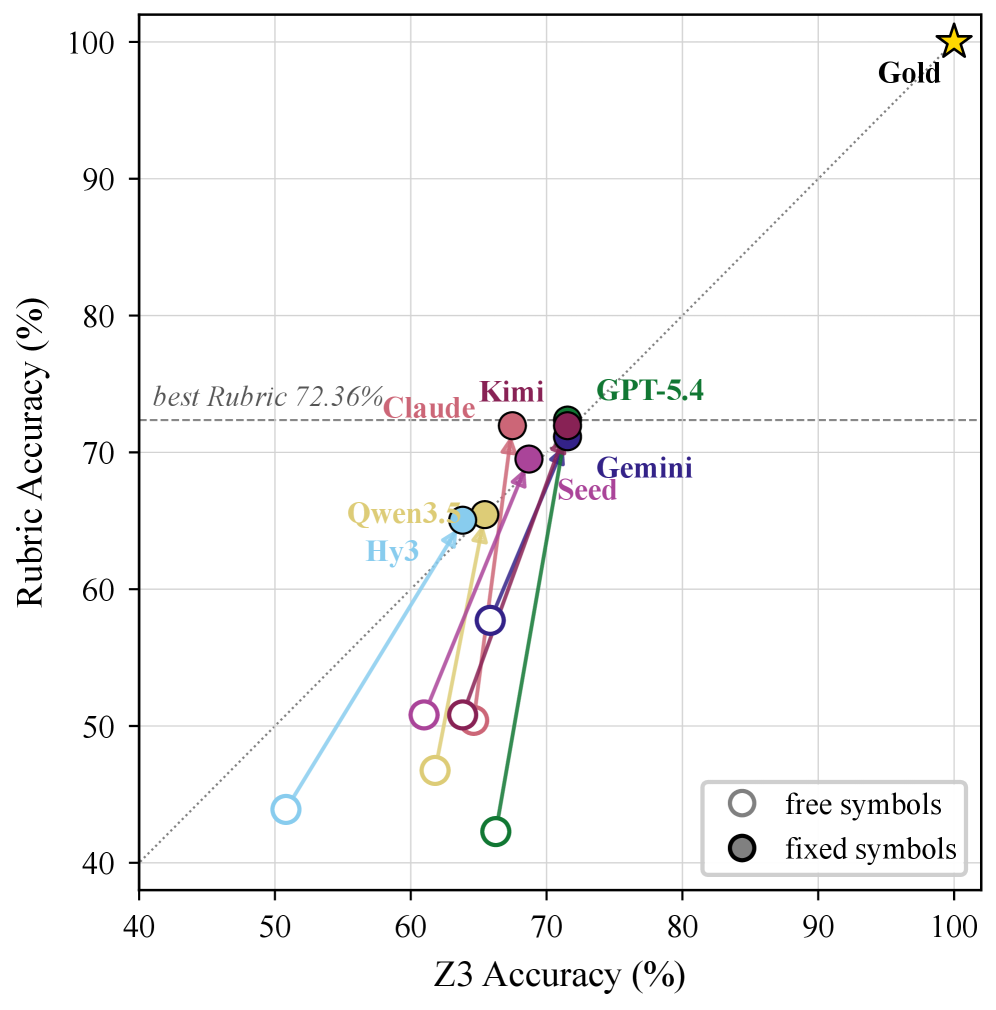
Figure 5 — Base 데이터셋 Z3 vs Rubric 정확도
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] AgenticDataBench: A Comprehensive Benchmark for Data Agents
- [논문리뷰] ChLogic: Evaluating Robustness of Logical Reasoning in Chinese Expressions
- [논문리뷰] WorldBench: A Challenging and Visually Diverse Multimodal Reasoning Benchmark
- [논문리뷰] Ψ-Bench: Evaluating Persona-Sensitive Influencing in Persuasive Dialogues
- [논문리뷰] AutoMedBench: Towards Medical AutoResearch with Agentic AI Models
Review 의 다른글
- 이전글 [논문리뷰] It Takes Two: Complementary Self-Distillation for Contextual Integrity in LLMs
- 현재글 : [논문리뷰] LLMEval-Logic: A Solver-Verified Chinese Benchmark for Logical Reasoning of LLMs with Adversarial Hardening
- 다음글 [논문리뷰] Learn-by-Wire Training Control Governance: Bounded Autonomous Training Under Stress for Stability and Efficiency
댓글