[논문리뷰] π-Bench: Evaluating Proactive Personal Assistant Agents in Long-Horizon Workflows
링크: 논문 PDF로 바로 열기
저자: Haoran Zhang, Luxin Xu, Zhilin Wang, Runquan Gui, Shunkai Zhang, Haodi Lei, Zihao He, Bingsu He, Chicheng Qin, Tong Zhu, Xiaoye Qu, Yang Yang, Yu Cheng, Yafu Li
1. Key Terms & Definitions (핵심 용어 및 정의)
- Proactivity: 사용자의 명시적인 지시가 없더라도, 에이전트가 목표, 컨텍스트, 이전 상호작용을 기반으로 잠재적 요구사항(Hidden Intents)을 미리 예측하여 능동적으로 과업을 완수하거나 적절한 질문을 통해 명확히 하는 능력.
- Hidden Intents: 사용자가 초기 요청에서 명시하지 않았지만, 작업의 진행이나 성공적인 완수를 위해 해결되어야 할 내재된 제약 조건, 개인적 선호도 또는 환경적 요구사항.
- Completeness: 작업의 최종 결과물이 명시된 요구사항과 제약 조건을 얼마나 충족하는지를 측정하는 지표로, 체크리스트(Checklist) 항목의 달성 여부로 평가됨.
- Persistent Workspaces: 여러 세션에 걸쳐 유지되는 파일 시스템, 도구(Tools), 작업 이력 등 에이전트가 정보를 공유하고 작업을 지속할 수 있는 환경.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 Personal Assistant Agent가 장기적인 프로젝트나 업무 환경에서 능동적으로 의도(Hidden Intents)를 파악하고 대응하지 못하는 한계를 해결하고자 한다. 기존 에이전트 벤치마크는 단기적인 지시사항 수행에 치중하거나, 단순히 단기 기억(Memory) 활용 여부만을 평가할 뿐, 작업 진행 과정에서 점진적으로 드러나는 사용자의 숨겨진 요구를 선제적으로 식별하고 해결하는 능력은 간과하고 있다 [Figure 1]. 따라서 본 연구는 이러한 능동적 지원 능력을 객관적으로 평가할 수 있는 새로운 벤치마크 프레임워크의 필요성을 제기한다.
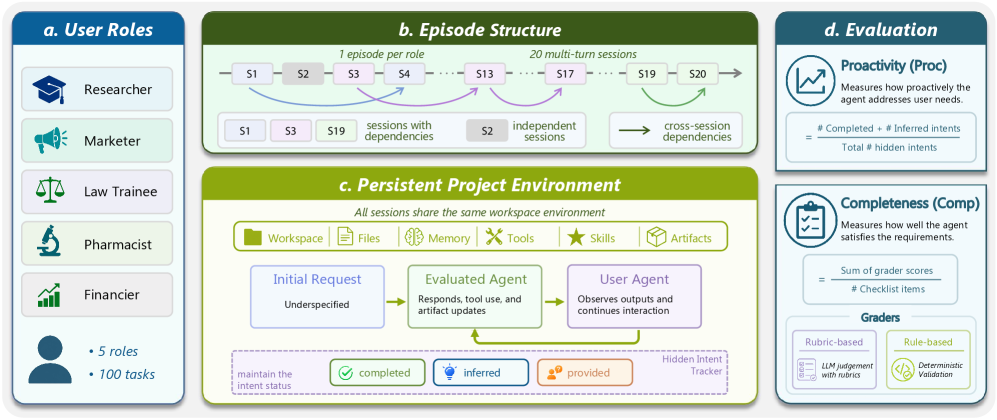
Figure 1 — π-Bench 전체 구조
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 5개의 도메인(연구자, 마케터, 법률 수습생, 약사, 금융인)에 걸쳐 100개의 다중 턴(Multi-turn) 작업을 포함하는 π-Bench를 제안한다 [Figure 1]. 본 벤치마크는 작업 수행 중 에이전트의 행동을 Proactivity와 Completeness라는 두 가지 독립적인 지표로 평가하며, 세션 내 상호작용은 에이전트가 Hidden Intent를 직접 해결(Completed)하거나, 질문을 통해 유도(Inferred)하거나, 사용자로부터 제공받는(Provided) 과정으로 구분하여 측정한다 [Figure 2]. 주요 실험 결과, GPT-5.4가 Proactivity 67.0%, Claude Opus 4.6이 Completeness 67.6%로 가장 높은 성능을 보였으나, 여전히 전체적인 정량 수치는 낮은 수준에 머물러 있어 능동적 지원이 어려운 도전 과제임을 확인하였다 [Table 1]. 특히, 사전 세션 이력이 있는 경우 Hidden Intent 해결율이 대폭 상승함을 통해 과거 데이터가 장기적인 업무의 능동적 대응에 핵심적임을 증명하였다 [Figure 5].
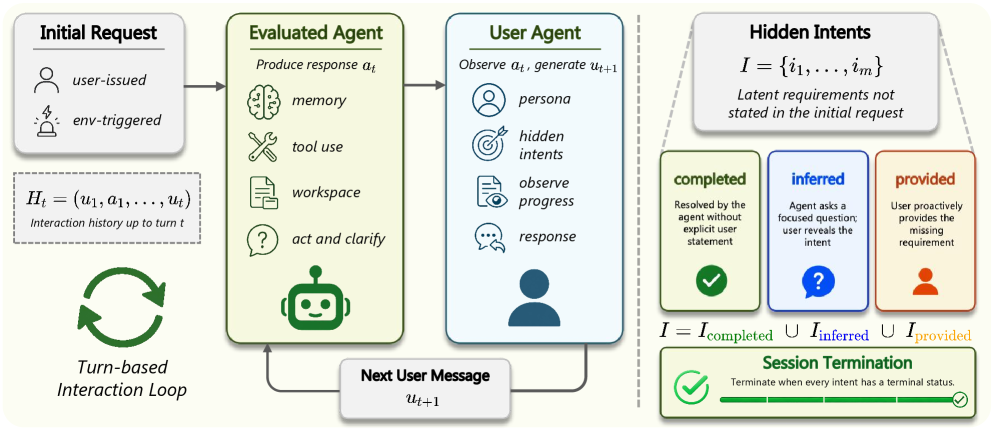
Figure 2 — 단일 벤치마크 세션 개요
4. Conclusion & Impact (결론 및 시사점)
본 논문은 에이전트가 단순히 명령을 수행하는 것을 넘어, 점진적으로 드러나는 사용자 의도를 선제적으로 파악하는 Proactivity를 공식화하고 이를 위한 평가 체계인 π-Bench를 제시하였다. 실험을 통해 에이전트의 작업 완료 능력과 능동적 의도 파악 능력이 독립적으로 작동할 수 있음을 입증하였으며, 이는 향후 장기적인 생산성 도구로 기능할 에이전트의 설계 방향성에 중요한 시사점을 제공한다. 이 연구는 개발자들이 에이전트의 능동적 지능을 측정하고 실패 요인을 진단하는 데 기여하며, 향후 안전하고 신뢰할 수 있는 능동적 에이전트 개발을 위한 가이드라인이 될 것으로 기대된다.
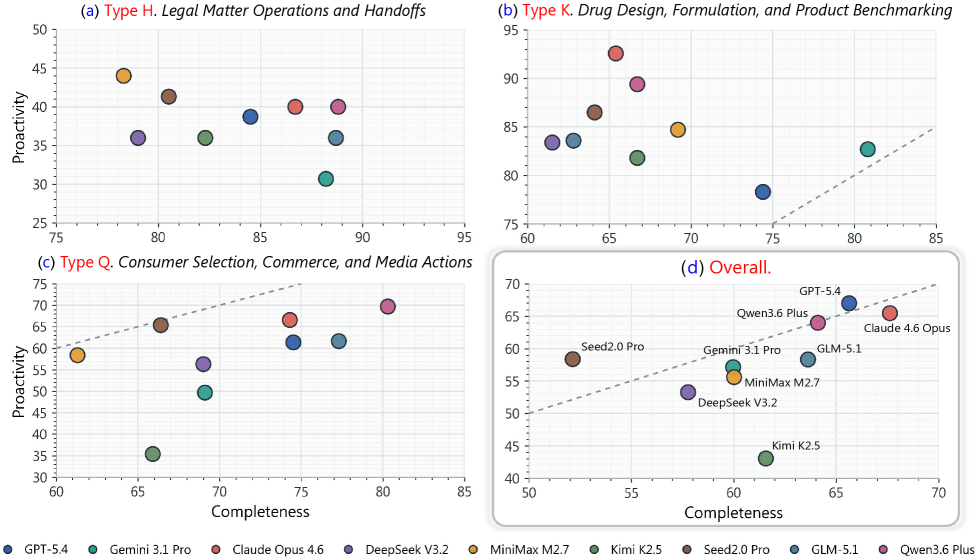
Figure 3 — 작업 유형별 성과 지표 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] 3DCodeBench: Benchmarking Agentic Procedural 3D Modeling Via Code
- [논문리뷰] Chat2Workflow: A Benchmark for Generating Executable Visual Workflows with Natural Language
- [논문리뷰] Recursive Harness Self-Improvement
- [논문리뷰] Cura 1T: Specialized Model for Agentic Healthcare
- [논문리뷰] MultiRef-Compass: Towards Comprehensive Evaluation of Multi-Reference-to-Audio-Video Generation
Review 의 다른글
- 이전글 [논문리뷰] WorldKV: Efficient World Memory with World Retrieval and Compression
- 현재글 : [논문리뷰] π-Bench: Evaluating Proactive Personal Assistant Agents in Long-Horizon Workflows
- 다음글 [논문리뷰] ETCHR: Editing To Clarify and Harness Reasoning
댓글