[논문리뷰] PiD: Fast and High-Resolution Latent Decoding with Pixel Diffusion
링크: 논문 PDF로 바로 열기
저자: Yifan Lu, Qi Wu, Jay Zhangjie Wu, Zian Wang, Huan Ling, Sanja Fidler, Xuanchi Ren
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- PiD (Pixel diffusion Decoder): 기존의 reconstruction-oriented VAE 디코더를 대체하여, Latent space에서 Pixel space로의 디코딩과 고해상도 업샘플링을 하나의 conditional pixel diffusion 과정으로 통합한 생성형 디코딩 프레임워크입니다.
- Sigma-aware gating: Latent condition의 노이즈 레벨에 따라 injection 강도를 동적으로 조절하여, 모델이 디코딩 과정에서 안정적인 성능을 유지하도록 돕는 메커니즘입니다.
- DMD2 (Distribution Matching Distillation): 복잡한 확산 모델의 추론 과정을 효율적으로 가속화하기 위해 사용하는 기법으로, 본 논문에서는 디코딩 단계를 단 4 step으로 단축하는 데 활용되었습니다.
- RAE (Representation Autoencoder): 픽셀 수준의 복원보다는 의미론적 구조(semantic structure)를 보존하는 데 최적화된 인코더로, 이를 디코딩하기 위한 고도의 생성 능력이 요구됩니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 연구는 기존 Latent Diffusion Models(LDMs)에서 사용되는 재구성 기반(reconstruction-oriented) 디코더가 고해상도 생성 시 발생하는 정보 손실과 연산 효율성 저하 문제를 해결하고자 합니다. 기존 디코더는 단순히 잠재 표현을 픽셀로 변환하는 데 최적화되어 있어, 세밀한 텍스처 합성에 한계가 있으며, 고해상도 출력을 위해 별도의 추가적인 업샘플링 단계가 필수적이라는 단점이 있습니다. 이러한 파이프라인은 전체적인 생성 품질을 저하시키고 연산 비용을 증가시키므로, 더 표현력이 높고 효율적인 디코딩 패러다임이 절실합니다. 본 논문은 [Figure 3]에 제시된 바와 같이, 잠재 공간에서의 디코딩과 고해상도 생성을 하나의 통합된 모듈로 처리함으로써 이러한 문제를 근본적으로 극복합니다.
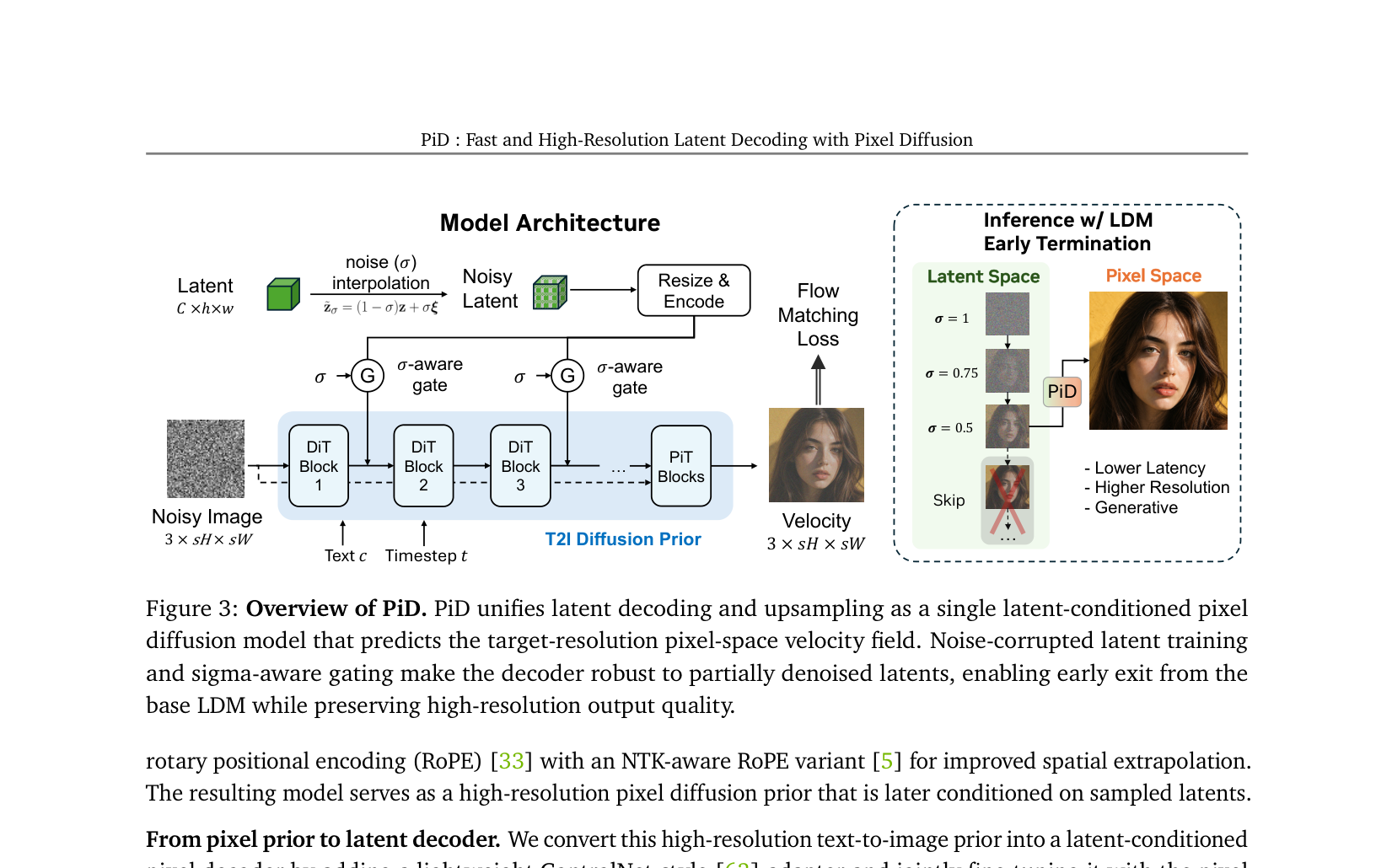
Figure 3 — PiD의 전체 모델 아키텍처 및 early termination을 포함한 추론 과정을 보여주는 핵심 다이어그램
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 본 연구는 잠재 표현을 고해상도 이미지로 직접 매핑하는 Latent-conditioned pixel diffusion 디코더인 PiD를 제안합니다. PiD는 텍스트 조건과 잠재 조건을 동시에 입력받아 노이즈가 섞인 타겟 해상도 이미지로부터 속도 필드(velocity field)를 예측하며, sigma-aware gating을 통해 잠재 정보와 디코더의 생성적 prior 사이의 균형을 맞춥니다. 또한, DMD2를 활용한 증류(distillation)를 통해 inference 단계에서 단 4 step만으로 2048x2048 해상도의 이미지를 생성할 수 있습니다. 실험 결과, PiD는 다양한 VAE 및 RAE 잠재 표현에 대해 기존 cascaded 파이프라인 대비 현저히 낮은 Latency를 보이면서도 더 높은 시각적 품질을 달성하였습니다. [Table 1]을 보면 PiD가 FLUX.1 및 SigLIP 등 다양한 설정에서 NIQE, Unipercept-IAA, VisualQuality-R1 등 주요 지표에서 최상위권의 성능을 기록했음을 확인할 수 있습니다. 특히 210ms라는 빠른 Latency는 기존 diffusion 기반 SR 방식들과 비교하여 3-6배 높은 효율성을 입증합니다.
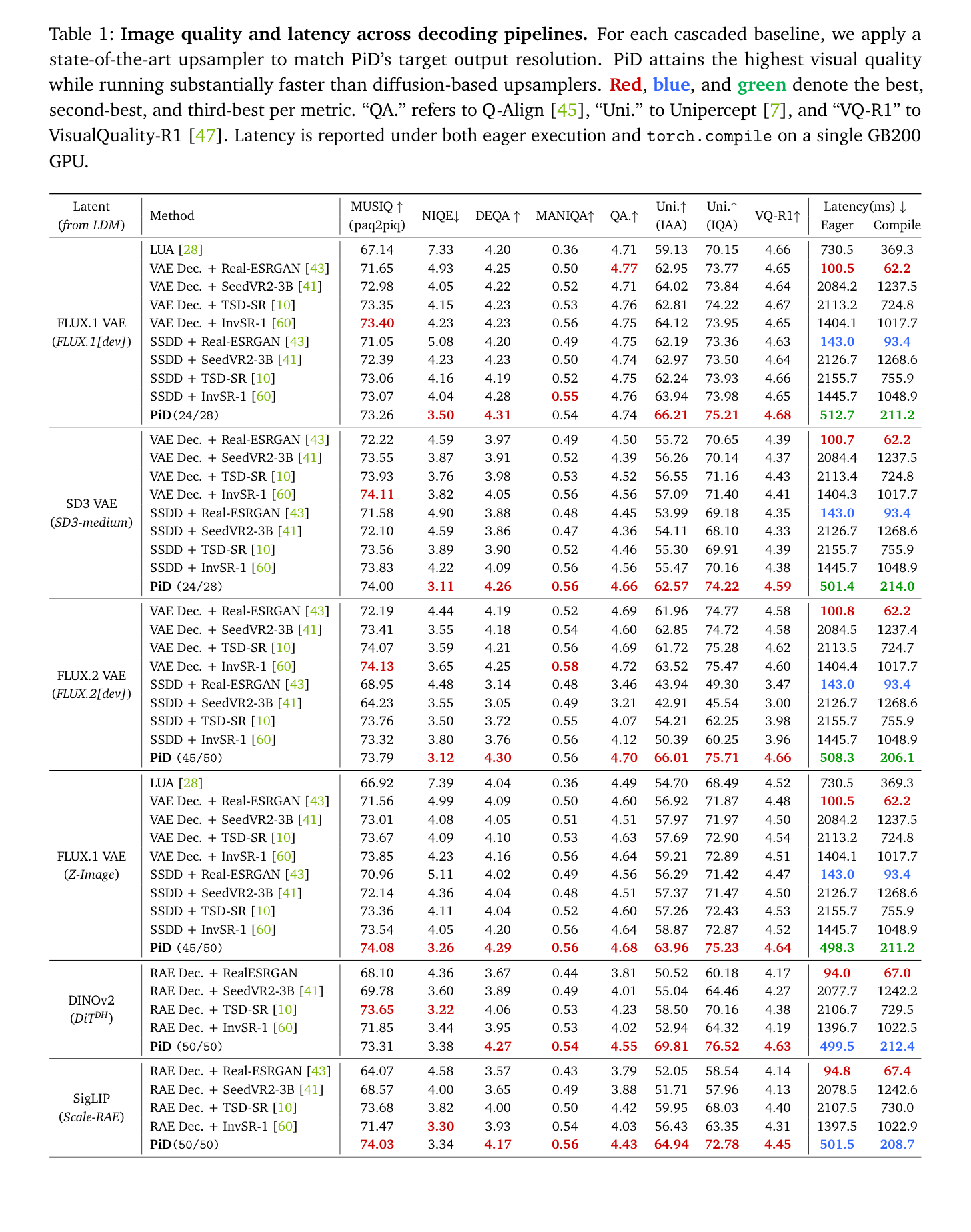
Table 1 — PiD와 다양한 베이스라인 모델 간의 품질 및 성능 벤치마크 결과 비교 테이블
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 디코딩 과정을 단일 생성형 모듈로 재정의함으로써 고해상도 이미지 생성의 효율성과 품질을 획기적으로 개선하였습니다. PiD는 기존의 재구성 기반 디코딩 파이프라인이 가진 구조적 한계를 성공적으로 극복하였으며, 특히 4K 해상도까지 손쉽게 확장 가능한 유연성을 보여줍니다. 이 연구는 생성형 AI 모델의 배포 환경에서 연산 비용을 획기적으로 절감하고, 다양한 비전 인코더의 잠재 표현을 활용할 수 있는 실용적인 디코딩 솔루션을 제공한다는 점에서 큰 학술적, 산업적 가치를 지닙니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] One Small Step in Latent, One Giant Leap for Pixels: Fast Latent Upscale Adapter for Your Diffusion Models
- [논문리뷰] RESOURCE2SKILL: Distilling Executable Agent Skills from Human-Created Multimodal Resources
- [논문리뷰] TREK: Distill to Explore, Reinforce to Refine
- [논문리뷰] Multi-Resolution Flow Matching: Training-Free Diffusion Acceleration via Staged Sampling
- [논문리뷰] LiveEdit: Towards Real-Time Diffusion-Based Streaming Video Editing
Review 의 다른글
- 이전글 [논문리뷰] PhotoFlow: Agentic 3D Virtual Photography Missions
- 현재글 : [논문리뷰] PiD: Fast and High-Resolution Latent Decoding with Pixel Diffusion
- 다음글 [논문리뷰] RankE: End-to-End Post-Training for Discrete Text-to-Image Generation with Decoder Co-Evolution
댓글