[논문리뷰] StepAudio 2.5 Technical Report
링크: 논문 PDF로 바로 열기
메타데이터
저자: Bin Lin, Bo Zhao, Boyong Wu, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Shared Backbone: 오디오 인코더(Audio Encoder), 어댑터(Adapter), LLM 디코더(Decoder)로 구성된 통합 아키텍처로, ASR, TTS, Realtime 인터랙션을 모두 지원하는 공통 기반입니다.
- MTP (Multi-token Prediction): ASR에서 추론 효율성을 극대화하기 위해 한 단계의 디코딩 과정에서 여러 미래 토큰을 예측하고 검증(Verification)하는 기법입니다.
- RLHF (Reinforcement Learning from Human Feedback): 단순히 SFT에 의존하는 대신, 인간의 선호도와 파라언어적(Paralinguistic) 행동을 학습하여 최적화 목표를 정교하게 정의하는 핵심 정렬 메커니즘입니다.
- Progressive SFT (Supervised Fine-tuning): 모델이 대화 맥락 유지, 페르소나 일관성, 파라언어적 민감성을 점진적으로 습득하도록 돕는 단계적 미세 조정 학습 커리큘럼입니다.
- RTF (Real-Time Factor): 시스템의 실시간 처리 능력을 평가하는 지표로, 처리 속도와 지연 시간의 효율성을 측정합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 ASR, TTS, 실시간 음성 대화와 같은 서로 다른 음성 작업이 공통적인 표현 공간(Representational Space)을 공유함에도 불구하고, 기존 통합 모델들이 개별 특화 시스템 대비 성능 차이를 보이는 문제를 해결하고자 합니다. 저자들은 이러한 작업 간 성능 격차가 아키텍처의 차이가 아닌 데이터, 최적화 목표, 디코딩 제약과 같은 '운영 체제(Operational Regimes)'의 차이에서 기인한다고 가정합니다 [Figure 1]. 따라서 본 연구는 복잡한 하위 작업을 통합적인 기초 모델로 내재화하고, 이를 특정 배포 목표에 맞게 특화시키는 새로운 패러다임을 제시합니다.
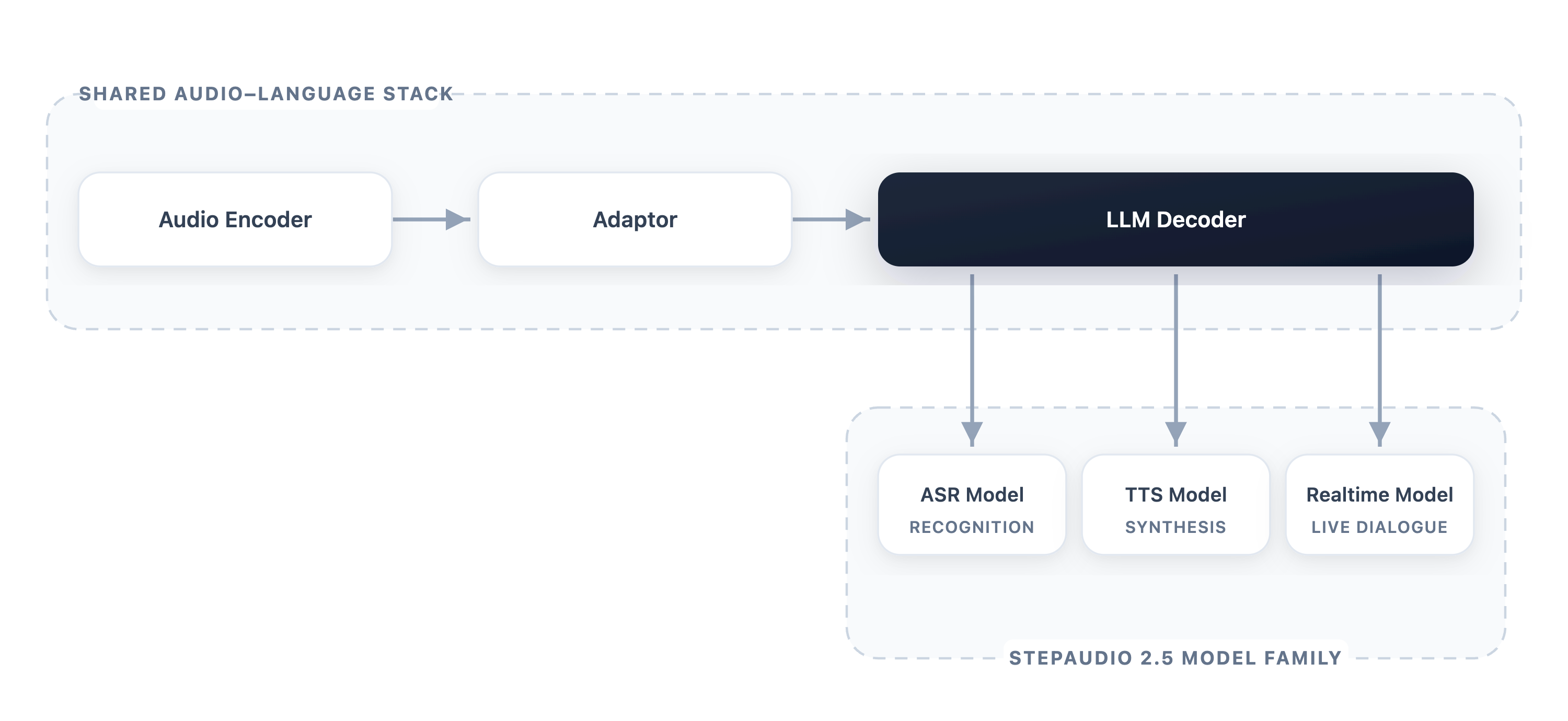
Figure 1 — 모델 통합 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 공유 백본(Shared Backbone)을 유지하면서 ASR, TTS, Realtime이라는 세 가지 방향으로 특화된 운영 체제를 구축합니다. ASR 브랜치는 MTP-5 기법을 도입하여 토큰 단위의 검증 과정을 통해 디코딩 효율성을 크게 개선하였습니다 [Figure 2]. TTS 브랜치는 인코더를 제거하고 LLM 기반의 순수 Next-Token Prediction으로 전환하여 정교한 오디오-텍스트 정렬을 달성했으며, Realtime 브랜치는 RLHF와 생성형 보상 모델(Generative Reward Model)을 활용하여 낮은 지연 시간과 페르소나 일관성을 구현했습니다.
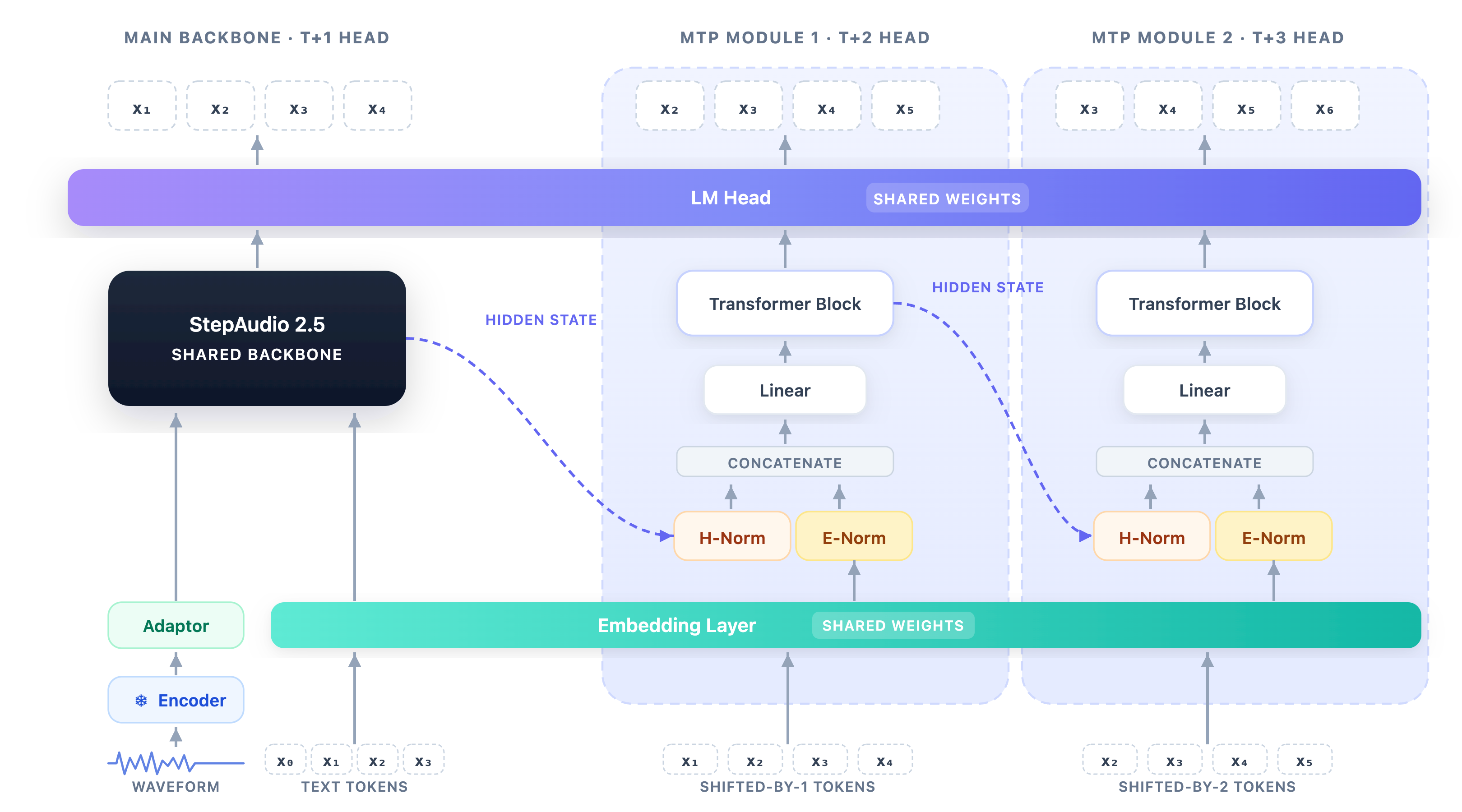
Figure 2 — ASR MTP 아키텍처
실험 결과, StepAudio 2.5는 ASR 분야에서 Chinese CER 2.97%, English WER 3.68%로 SOTA 성능을 기록하며 특히 긴 문맥(Long-form) 처리에서 뛰어난 정확도를 보였습니다 [Table 1]. 또한, ASR 디코딩 과정에서 RTF 0.0053이라는 압도적인 효율성을 입증했습니다 [Table 2]. TTS 부문에서는 MiniMax-2.8-HD, Elevenlabs-v3 등 기존 강자들을 상대로 67.6%의 승률(Win Rate)을 기록하며 우위를 점했습니다 [Figure 4]. Realtime 평가지표에서도 모든 테스트 스위트에서 베이스라인 모델을 능가하며, 특히 인간 평가에서 +10.0의 높은 마진을 확보하는 성과를 거두었습니다 [Figure 5].
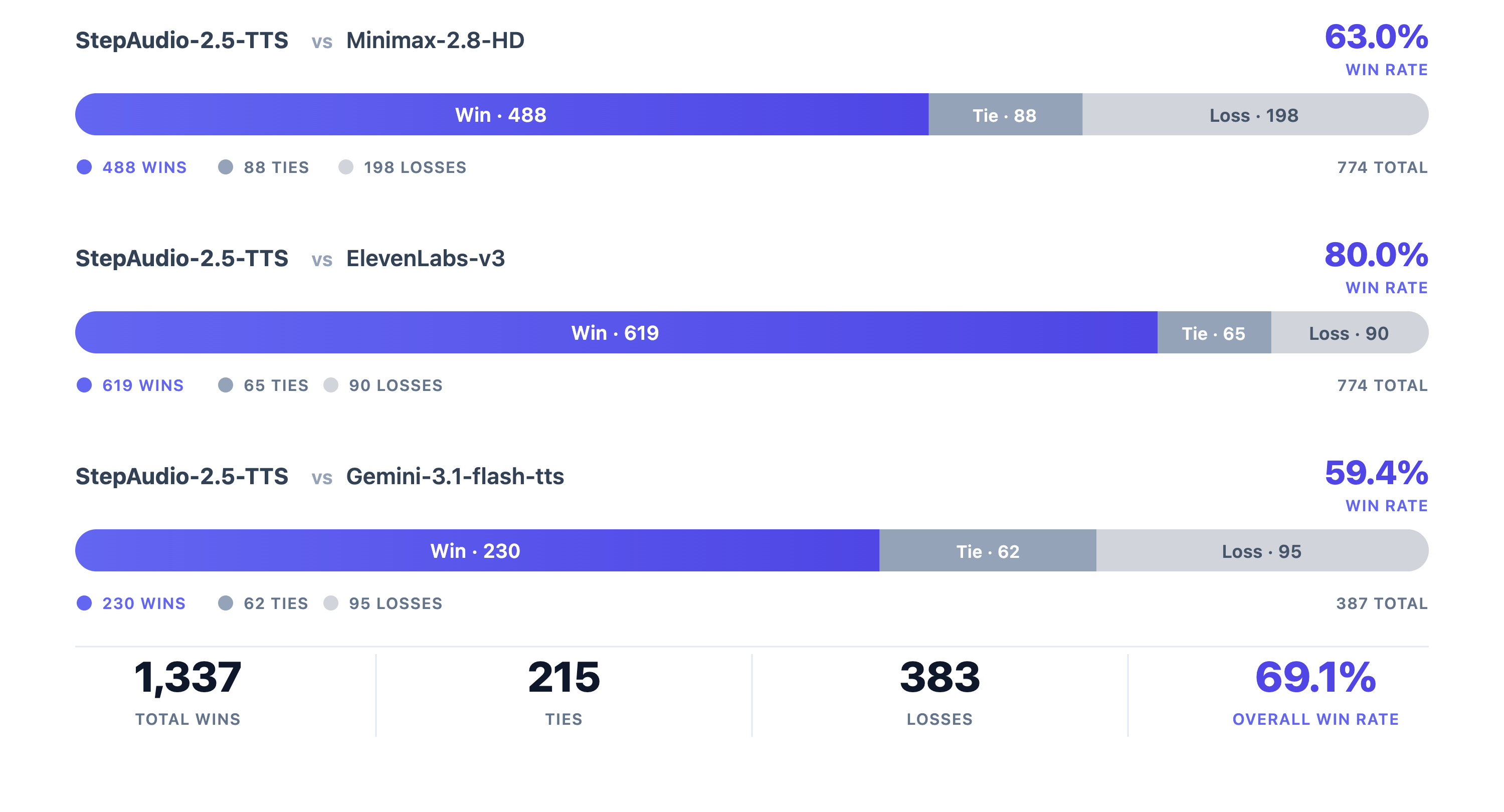
Figure 4 — TTS 성능 비교 결과
4. Conclusion & Impact (결론 및 시사점)
본 연구는 통합 음성-언어 모델이 단순히 여러 작업을 모아둔 시스템이 아니라, 공통의 기반 위에 서로 다른 최적화 및 배포 전략을 적용함으로써 개별 특화 모델 이상의 성능을 발휘할 수 있음을 입증했습니다. 이 모델은 음성 인식, 합성, 실시간 상호작용이라는 세 가지 도메인을 하나의 아키텍처로 통합하는 데 성공했으며, 특히 RLHF와 MTP 같은 기술적 시도는 향후 고성능 범용 음성 모델 설계의 새로운 표준을 제시합니다. 이러한 성과는 산업계의 실시간 음성 대화 시스템 구현에 실질적인 기술적 돌파구를 제공할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Qwen-Image-2.0-RL Technical Report
- [논문리뷰] Duration Aware Scheduling for ASR Serving Under Workload Drift
- [논문리뷰] Flow-DPPO: Divergence Proximal Policy Optimization for Flow Matching Models
- [논문리뷰] The Flip Side of RLHF: On-Policy Feedback for Reward Model Self-Supervised Improvement
- [논문리뷰] Alignment Tampering: How Reinforcement Learning from Human Feedback Is Exploited to Optimize Misaligned Biases
Review 의 다른글
- 이전글 [논문리뷰] SkillOpt: Executive Strategy for Self-Evolving Agent Skills
- 현재글 : [논문리뷰] StepAudio 2.5 Technical Report
- 다음글 [논문리뷰] The Expense of Seeing: Attaining Trustworthy Multimodal Reasoning Within the Monolithic Paradigm
댓글