[논문리뷰] Claw-Anything: Benchmarking Always-On Personal Assistants with Broader Access to User's Digital World
링크: 논문 PDF로 바로 열기
저자: Yusong Lin, Xinyuan Liang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Claw-Anything: Always-on personal assistant agent 평가를 위해 제안된 벤치마크로, user의 digital world에 대한 광범위한 접근을 특징으로 합니다.
- Pass@1: Agent가 특정 task를 첫 번째 시도에서 성공적으로 완료했는지 여부를 나타내는 핵심 성능 지표입니다.
- Investigation-Execution Gap: Agent가 task 수행에 필요한 관련 context를 성공적으로 식별했음에도 불구하고, 이를 효과적인 action으로 전환하는 데 실패하는 현상을 의미합니다.
- Proactive Assistance: Agent가 user의 명시적인 요청 없이도 user의 요구사항을 예측하고 시의적절한 추천이나 도움을 제공하는 기능입니다.
- Context-rich digital environment: Claw-Anything 벤치마크에서 agent가 작동하는 환경으로, user persona, 다양한 devices, 40개 이상의 backend services의 persistent states, 그리고 3개월 이상의 long-horizon activity streams을 포함합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
현재 Large Language Model(LLM) 기반 agent 시스템은 user의 digital world 중 매우 제한적인 부분에만 접근하여 context-sensitive reasoning과 효과적인 assistance 제공에 심각한 한계를 보입니다. 기존 벤치마크들 또한 user state의 부분적이고 정적인 스냅샷만을 제공하여, real-world의 always-on 개인 비서 환경에서의 agent 성능을 제대로 측정하지 못합니다. 이러한 격차를 해소하기 위해, 본 연구는 long-horizon activity histories, interdependent backend services, multi-device (GUI 및 CLI) interaction 세 가지 핵심 차원을 따라 agent context를 확장한 새로운 벤치마크 Claw-Anything을 제안합니다. [Figure 2, Table 1] 이는 현재 agent capabilities와 real-world always-on personal assistance의 복잡한 요구사항 사이의 상당한 간극을 드러내며, 기존 평가에서는 충분히 다뤄지지 않았던 새로운 failure modes를 식별하는 데 기여합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Claw-Anything 벤치마크를 위해 iterative digital environment synthesis, task and verifier generation, automatic filtering, human verification with execution support의 4단계로 구성된 자동화된 파이프라인을 개발했습니다. [Figure 3] 이 파이프라인은 LLM 기반 시뮬레이터를 활용하여 months of user activity를 multi-round event injection 방식으로 시뮬레이션하여 complex world states와 realistic noise를 포함하는 200개의 human-verified evaluation task와 2,000개의 training environment를 생성합니다. 실험 결과, 최신 closed-source 모델인 GPT-5.5조차 Claw-Anything 벤치마크에서 34.5% Pass@1이라는 현저히 낮은 성공률을 기록했습니다. [Figure 1, Table 2] 이는 기존 벤치마크 대비 agent의 perceptual scope 확장이 task 난이도를 크게 증가시켰으며, 현재 모델들이 실제 Always-on personal assistant의 요구사항을 충족하기 어렵다는 점을 시사합니다. 또한, 제안된 데이터 파이프라인을 통해 수집된 1,500개의 successful trajectories로 Qwen3.5-27B 모델을 fine-tuning한 결과, Pass@1 성능이 23.7% 향상되어, 베이스라인 모델을 능가하고 closed-source 모델과의 격차를 줄였음을 보여주었습니다. [Table 2] Ablation studies는 long-horizon event streams, cross-backend services, CLI-GUI collaboration과 같은 context scaling dimension이 agent 성능에 critical한 영향을 미치며, 특히 proactive tasks가 reactive tasks보다 훨씬 어렵다는 것을 입증했습니다. [Table 3, Figure 5]
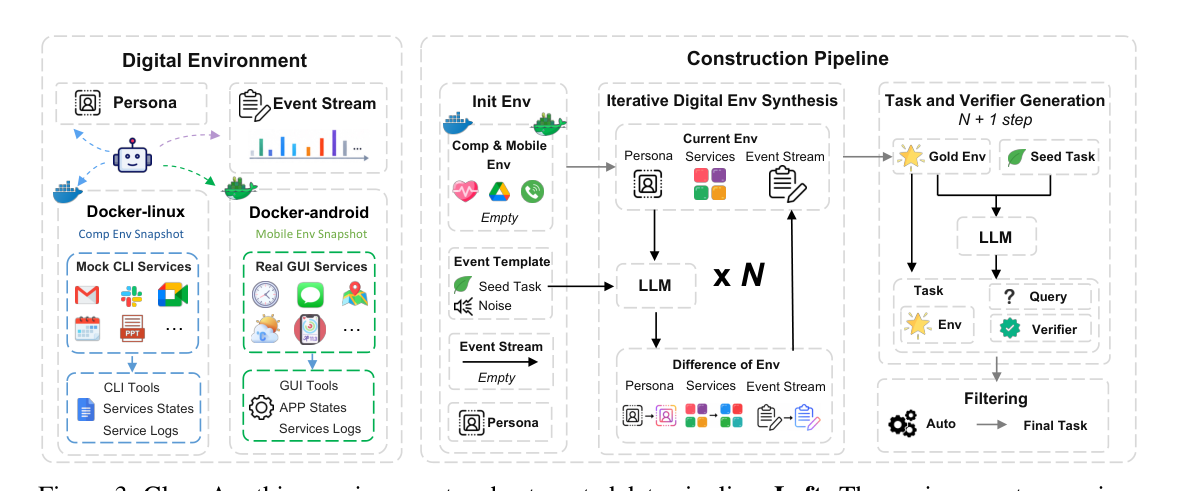
Figure 3 — Claw-Anything의 디지털 환경 구성 요소와 자동화된 데이터 생성 파이프라인을 설명하는 방법론 핵심 다이어그램
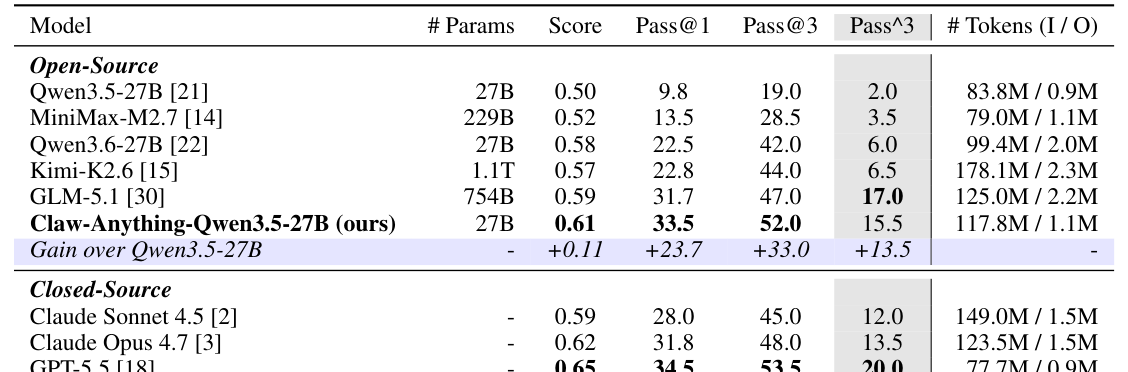
Table 2 — Claw-Anything 벤치마크에서 다양한 LLM 모델들의 Pass@1, Pass@3 등 주요 성능 지표를 비교하는 핵심 결과 테이블
4. Conclusion & Impact (결론 및 시사점)
본 연구는 long-horizon event streams, diverse backend services, multi-device interaction 및 proactive tasks를 통합하여 personal-assistant agent 평가를 위한 포괄적인 벤치마크인 Claw-Anything을 성공적으로 제시했습니다. 이 벤치마크는 현재 LLM agents와 real-world assistance의 요구사항 사이에 존재하는 상당한 성능 격차를 명확히 드러냈으며, context의 범위가 넓어질수록 agent의 성능이 저하되는 현상을 정량적으로 보여주었습니다. 또한, 개발된 자동화된 데이터 생성 파이프라인은 scalable environment construction을 가능하게 하여, future research on personal-assistant agents를 위한 실용적인 기반을 제공합니다. 궁극적으로 Claw-Anything은 agent systems의 operational scope 확장이 복잡한 real-world digital 환경에서 agent가 더 넓은 범위의 tasks를 완수할 수 있도록 하는 데 중요함을 강조하며, AI agent 분야의 발전을 위한 중요한 이정표를 제시합니다.

Figure 1 — Claw-Anything 벤치마크의 전체적인 개념과 모델의 경험적 가치를 시각적으로 보여주는 핵심 다이어그램
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Managing Procedural Memory in LLM Agents: Control, Adaptation, and Evaluation
- [논문리뷰] CoffeeBench: Benchmarking Long-Horizon LLM Agents in Heterogeneous Multi-Agent Economies
- [논문리뷰] Beyond Static Leaderboards: Predictive Validity for the Evaluation of LLM Agents
- [논문리뷰] When Tools Fail: Benchmarking Dynamic Replanning and Anomaly Recovery in LLM Agents
- [논문리뷰] ForeSci: Evaluating LLM Agents for Forward-Looking AI Research Judgment
Review 의 다른글
- 이전글 [논문리뷰] Channel-wise Vector Quantization
- 현재글 : [논문리뷰] Claw-Anything: Benchmarking Always-On Personal Assistants with Broader Access to User's Digital World
- 다음글 [논문리뷰] ControlLight: Towards Controllable, Consistent, and Generalizable Low-Light Enhancement
댓글