[논문리뷰] Channel-wise Vector Quantization
링크: 논문 PDF로 바로 열기
The content is available. I will now extract the required information.
Part 1: Summary Body
- Authors: Wei Song, Tianhang Wang, Yitong Chen, Tong Zhang, Zuxuan Wu, Ming Li, Jiaqi Wang, Kaicheng Yu
- Keywords: I will identify 5-8 keywords based on the abstract and introduction.
- Channel-wise Vector Quantization (CVQ)
- Autoregressive Generation (AR)
- Next-Channel Prediction (NCP)
- Codebook Utilization
- Visual Tokenization
- Image Reconstruction
- Text-to-Image Generation
- Nested Channel Dropout
- Key Terms & Definitions: I'll pick 3-5 crucial terms and define them from the paper.
- Channel-wise Vector Quantization (CVQ): A novel image tokenization paradigm that quantizes each channel of a feature map, representing an image as discrete levels of visual details rather than spatial patches.
- Channel-wise Auto-Regressive (CAR): A visual autoregressive framework that predicts image channels sequentially, generating images by progressively enriching visual details from global structures to fine-grained attributes.
- Codebook Utilization: The percentage of active codebook vectors that receive updates during the training of a Vector Quantization (VQ) model, indicating the efficiency of the learned discrete representations.
- Nested Channel Dropout: A training strategy applied during tokenizer training to enforce an ordered coarse-to-fine sequence for autoregressive generation, where a random subset of channels (
c_keep) is retained, and the rest are masked. - Next-Channel Prediction (NCP): A strategy in autoregressive visual modeling where the autoregressive unit is an entire channel, instead of a patch token, allowing for sequential prediction of visual content.
- Motivation & Problem Statement: I'll describe the core problems and limitations of existing methods.
- Conventional VQ with patch-wise tokenization suffers from insufficient codebook usage and information loss, leading to poor reconstruction quality.
- Patch-wise tokenization discretizes images into 2D grids, which are then flattened into 1D sequences for autoregressive learning, causing a structural mismatch and suboptimal token ordering for unidirectional AR modeling.
- This structural mismatch disrupts local spatial dependencies and makes it difficult to impose an AR-friendly ordering using methods like nested dropout.
- Method & Key Results: I'll explain CVQ and CAR and present quantitative results.
- CVQ reformulates VQ by quantizing each channel (
h x w x 1feature vector) instead of1 x 1 x cpatch feature vectors. This leads to more separable embeddings and addresses codebook collapse. - CAR uses a next-channel prediction strategy, where a decoder-only transformer predicts channel tokens sequentially, progressively refining visual details.
- Nested channel dropout is applied during tokenizer training to establish a coarse-to-fine channel order for AR generation.
- Reconstruction Performance: CVQ achieves 100% codebook utilization even with a 16K+ codebook size, significantly outperforming vanilla VQGAN (4.5% utilization). For 1024 tokens, CVQ attains an rFID of 0.88 and a PSNR of 25.02 dB, surpassing MoVQGAN (1.05 rFID) and VQGAN-LC (1.29 rFID).
- Generation Performance: CAR (8B) achieves a GenEval score of 0.79 and a DPG overall score of 86.72, demonstrating strong effectiveness for text-to-image generation and competitive performance against strong VAR methods like Infinity and InfinityStar.
- CVQ reformulates VQ by quantizing each channel (
- Conclusion & Impact: Summarize findings and implications.
- CVQ is a simple yet effective quantization paradigm that discretizes images along the channel dimension, achieving high codebook utilization and reconstruction fidelity.
- CAR, based on CVQ, reformulates autoregressive generation as next-channel prediction, producing progressively detailed visual content.
- This work highlights channel-wise tokens as a promising direction, offering new insights into visual tokenization, potentially leading to more efficient and compact visual representations and unified vision models.
Part 2: Important Figure Information
I need to select up to 3 important figures. Looking at the figures in the paper:
- Figure 1: VQ vs. CVQ (tokenization) and AR vs. CAR (generation process). This is crucial for understanding the core contribution.
- Figure 2: Visualizes channel activation maps and ablation. Good, but Figure 1 and 3 are more high-level architecture/methodology.
- Figure 3: (a) Conventional VQ and standard AR; (b) Proposed CVQ and CAR. This is an overall architecture/methodology comparison and very important.
- Figure 4: t-SNE visualizations of embedding distributions and codebook usage. This supports the claim about codebook utilization.
- Figure 5: The generation process of CAR. Illustrates the progressive generation.
- Figure 6: Qualitative results.
- Figure 7: More t-SNE visualizations (Appendix).
I will choose Figure 1, Figure 3, and Figure 4 as they explain the core concepts (CVQ vs VQ, CAR vs AR) and provide key evidence (codebook utilization).
Image URLs extraction:
- Figure 1:
2605.26089v1/x1.png->https://arxiv.org/html/2605.26089v1/x1.png - Figure 3:
2605.26089v1/x3.png->https://arxiv.org/html/2605.26089v1/x3.png - Figure 4:
2605.26089v1/x4.png->https://arxiv.org/html/2605.26089v1/x4.png
Now I will structure the output according to the specified format.저자: Wei Song, Tianhang Wang, Yitong Chen, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Channel-wise Vector Quantization (CVQ): 기존 patch-wise tokenization과 달리 feature map의 각 channel을 양자화하여 이미지를 공간적 패치가 아닌 시각적 세부 사항의 이산적 레벨로 표현하는 새로운 이미지 tokenization 패러다임입니다.
- Channel-wise Auto-Regressive (CAR): "next-channel prediction"을 기반으로 하는 시각적 autoregressive 프레임워크로, 이미지를 channel별로 순차적으로 예측하여 점진적으로 풍부한 시각적 디테일을 생성합니다.
- Codebook Utilization: Vector Quantization (VQ) 모델 훈련 중 업데이트를 받는 활성 codebook vector의 비율을 나타내는 지표로, 학습된 이산 표현의 효율성을 측정합니다.
- Nested Channel Dropout: Tokenizer 훈련 단계에서 autoregressive 생성을 위한 coarse-to-fine 순서를 확립하기 위해 적용되는 훈련 전략으로, 무작위로 선택된
c_keep개의 channel만 유지하고 나머지는 마스킹합니다. - Next-Channel Prediction (NCP): Autoregressive 시각 모델링에서 autoregressive 단위가 patch token이 아닌 전체 channel인 전략으로, 시각적 콘텐츠의 순차적 예측을 가능하게 합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 기존 Vector Quantization (VQ) 기반 이미지 tokenization 및 autoregressive 생성 방식의 근본적인 한계점을 해결하고자 합니다. 기존 patch-wise VQ는 불충분한 codebook utilization 문제를 겪으며, 이는 codebook collapse로 이어져 정보 손실과 저조한 재구성 품질을 야기합니다. 또한, 이미지를 2D grid의 patch로 이산화한 후 이를 1D 시퀀스로 평탄화하여 autoregressive 학습에 적용하는 방식은 언어와 시각 데이터 간의 구조적 불일치(structural mismatch)를 초래합니다. 이러한 불일치는 인접한 token들 간의 지역적 공간 의존성(local spatial dependencies)을 방해하여 unidirectional autoregressive 모델링에 부적합한 token ordering을 야기하며, nested dropout과 같은 AR-friendly ordering 적용을 어렵게 만듭니다. Figure 3 (a)는 이러한 기존 VQ 및 AR 모델의 한계를 명확히 보여줍니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 기존 VQ의 quantization 축을 변경하여 Channel-wise Vector Quantization (CVQ)을 제안합니다. 기존 VQ가 1x1xc patch feature vector에 인덱스를 할당하는 반면, CVQ는 feature map의 각 channel(hxw x1 feature vector)에 인덱스를 할당합니다 [Figure 1, Figure 3]. 이는 이미지의 유사성과 반복성으로 인해 발생하는 patch 간의 높은 중복성을 줄여, channel 차원별로 특징을 분할함으로써 더 분리 가능한 embedding을 생성하고, 결과적으로 codebook utilization을 크게 향상시킵니다 [Figure 4]. CVQ는 추가적인 모듈이나 제약 없이 100% codebook utilization을 달성하며, 특히 16,384 이상의 대규모 codebook에서도 이러한 성능을 유지합니다. 256 token 예시에서 CVQ는 기존 VQGAN의 4.5% codebook utilization 대비 월등한 효율성을 보였으며, 1024 token 설정에서는 rFID 0.88 및 PSNR 25.02 dB를 기록하며 MoVQGAN (1.05 rFID) 및 VQGAN-LC (1.29 rFID)와 같은 강력한 baseline을 능가하는 재구성 품질을 입증했습니다.
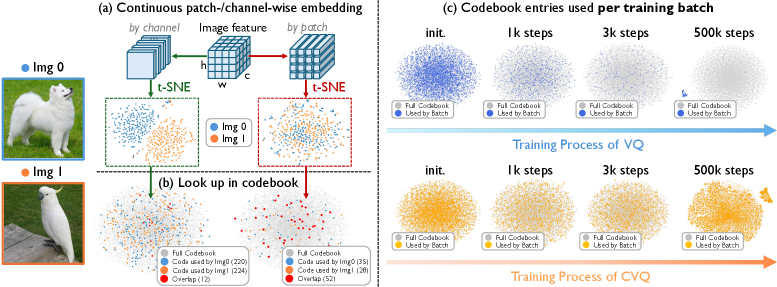
Figure 4 — 임베딩 분포 및 코드북 활용률
CVQ를 기반으로, 저자들은 Channel-wise Auto-Regressive (CAR) 모델을 도입하여 autoregressive 이미지 생성을 next-channel prediction으로 재구성합니다 [Figure 3 (b)]. CAR은 decoder-only transformer를 사용하여 channel token들을 텍스트 컨텍스트에 따라 순차적으로 예측하며, 이는 인간 예술가의 작업 흐름과 유사하게 전반적인 구조를 스케치한 후 점진적으로 세부 사항을 다듬는 방식입니다 [Figure 1, Figure 5]. channel은 본질적인 순서가 없으므로, tokenizer 훈련 단계에서 nested channel dropout을 적용하여 AR 훈련을 위한 coarse-to-fine 시퀀스를 확립합니다. 이 간단한 전략은 channel-wise token이 AR-friendly한 ordering을 형성하도록 효과적으로 유도합니다. 실험 결과, 8B 파라미터를 가진 CAR 모델은 GenEval 점수 0.79 및 DPG 전체 점수 86.72를 달성하여, NextStep-1 (14B) 및 Emu3 (8B)와 같은 강력한 AR baseline은 물론 Infinity 및 InfinityStar와 같은 VAR 방식과도 경쟁력 있는 text-to-image 생성 성능을 보여주었습니다.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 channel dimension을 따라 이미지를 이산화하는 간단하지만 효과적인 양자화 패러다임인 CVQ를 성공적으로 제안했습니다. CVQ는 아키텍처 수정이나 보조 손실 함수 없이도 높은 codebook utilization과 우수한 재구성 충실도를 달성합니다. 또한, CVQ를 기반으로 구축된 CAR은 기존의 공간적 patch 예측에서 next-channel prediction으로 autoregressive 패러다임을 전환하는 생성 프레임워크를 제시합니다. 이 연구는 channel-wise token이 autoregressive 이미지 생성에 있어 유망한 방향임을 강조하며, 시각 tokenization의 근본적인 단위를 재고하는 새로운 통찰력을 제공합니다. 이는 향후 보다 효율적이고 압축적인 시각 표현 학습 및 시각 이해와 생성을 통합하는 통합 비전 모델(unified vision models) 개발에 중요한 시사점을 가집니다.
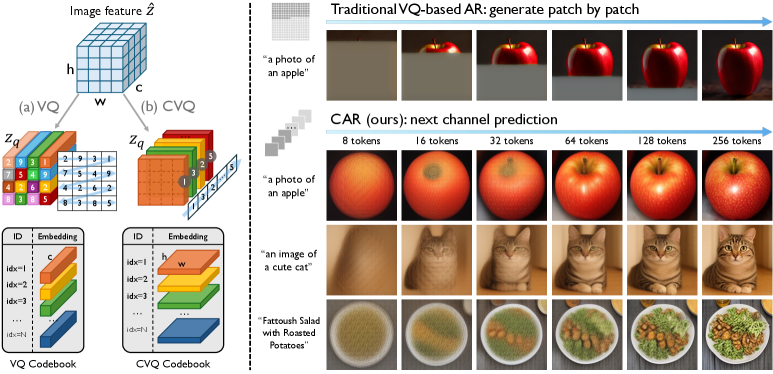
Figure 1 — VQ vs CVQ, AR vs CAR 비교
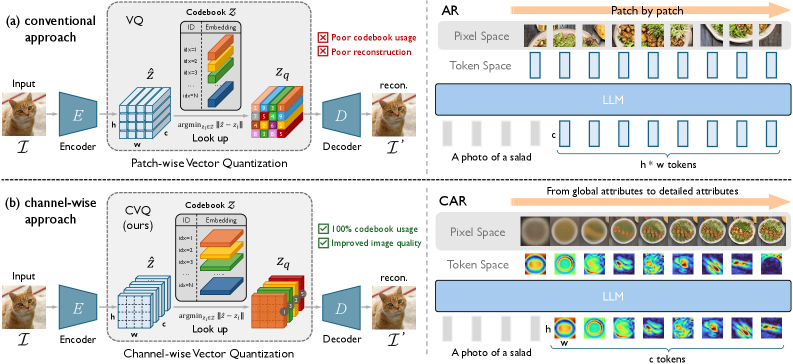
Figure 3 — 기존 및 제안 방법론 개요
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Read It Back: Pretrained MLLMs Are Zero-Shot Reward Models for Text-to-Image Generation
- [논문리뷰] Vidu S1: A Real-Time Interactive Video Generation Model
- [논문리뷰] Flex-Forcing: Towards a Unified Autoregressive and Bidirectional Video Diffusion Model
- [논문리뷰] LiveEdit: Towards Real-Time Diffusion-Based Streaming Video Editing
- [논문리뷰] Parallel Rollout Approximation for Pixel-Space Autoregressive Image Generation
Review 의 다른글
- 이전글 [논문리뷰] AutoResearch AI: Towards AI-Powered Research Automation for Scientific Discovery
- 현재글 : [논문리뷰] Channel-wise Vector Quantization
- 다음글 [논문리뷰] Claw-Anything: Benchmarking Always-On Personal Assistants with Broader Access to User's Digital World
댓글