[논문리뷰] VibeSearchBench: Benchmarking Long-horizon Proactive Search in the Wild
링크: 논문 PDF로 바로 열기
메타데이터
저자: Z.Y., S.L., Lei Huang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- VibeSearch: 사용자와 AI 에이전트가 모호한 의도를 다회차 대화를 통해 점진적으로 구체화하며 정보를 탐색하는 검색 패러다임.
- Progressive-disclosure User Simulator: 사용자의 정보 요구사항을 단계별로 나누어 에이전트의 proactive한 의도 도출(intent elicitation)을 유도하는 시뮬레이터.
- Schema-free Knowledge Graph: 고정된 스키마 없이 자유로운 형태의 Directed Graph로 정보를 구조화하여 유연하고 객관적인 평가를 가능하게 하는 출력 및 평가 포맷.
- OpenClaw: 실제 배포 환경에서 사용되는 개인 AI 어시스턴트용 에이전트 harness.
- Evaluation–Experience Gap: 기존 벤치마크 점수와 실제 사용자 체감 품질 간의 불일치 현상.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM 기반 에이전트가 기존 벤치마크에서는 높은 성능을 보임에도 불구하고, 실사용 환경에서는 사용자 만족도가 낮은 'Evaluation–Experience Gap' 문제를 해결하고자 한다. [Figure 1] 기존 벤치마크들은 과도하게 명시적인 쿼리, 단일 턴 상호작용, 고정된 스키마 평가 방식에 의존하고 있어, 사용자와 에이전트가 협력하여 의도를 구체화하는 실질적인 검색 프로세스를 반영하지 못한다. 저자들은 이러한 한계를 극복하기 위해 실제 검색 환경의 동적 특성을 반영한 새로운 벤치마크를 제안한다.
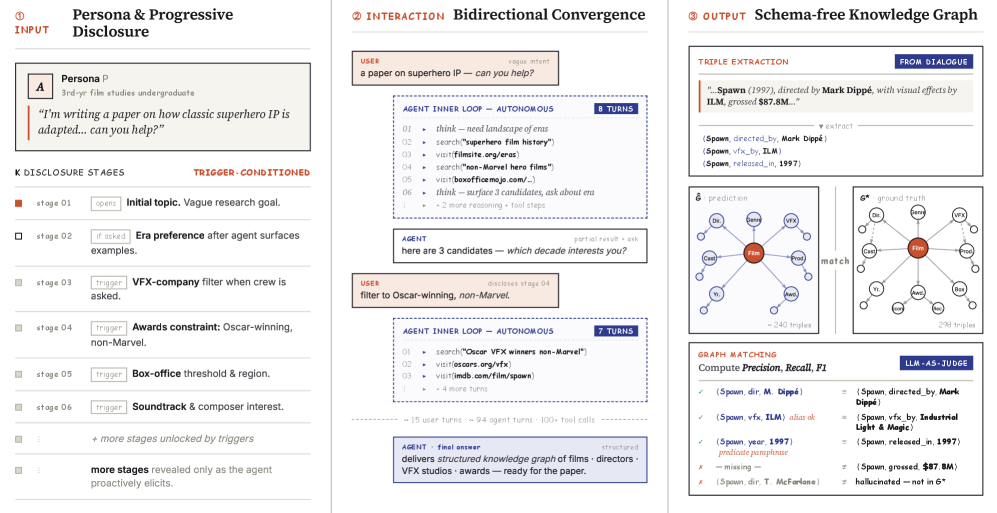
Figure 1 — VibeSearchBench의 전체 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 검색을 일방적인 질의응답이 아닌, 상호작용을 통한 의도 수렴 과정으로 정의하고 이를 평가하기 위해 VibeSearchBench를 구축하였다. 이는 20개 도메인, 200개의 전문적(Pro) 및 일상적(Daily) 작업으로 구성되며, Persona-based Progressive Disclosure 시뮬레이터와 Graph-matching 평가 프레임워크를 사용한다. [Figure 2] 7개의 Frontier 모델을 ReAct 및 OpenClaw 환경에서 평가한 결과, 모든 모델이 VibeSearch 수행에 있어 상당히 부족함을 드러냈다. 최고 성능을 기록한 Claude Opus 4.6조차 OpenClaw 환경에서 평균 F1 30.30에 그쳤으며, 다른 모델들은 20~23점대의 낮은 점수를 기록하였다. 실험 결과, 프로액티브한 전략(사용자 턴당 7-8회 툴 호출)이 성능과 양의 상관관계를 보였으나, 과도한 리소스 소비는 Context Overflow를 유발하여 오히려 성능을 저하시키는 결과를 낳았다. [Figure 3] 또한 하위 에이전트 협업, 메모리 기능 등 기존 프레임워크 수준의 보완책들은 성능 향상에 유의미한 도움을 주지 못했다.
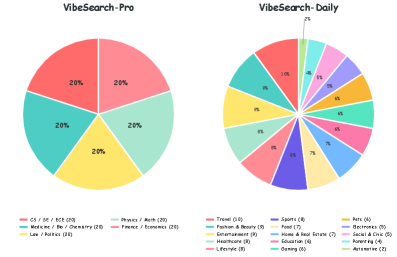
Figure 2 — 벤치마크 도메인 분포
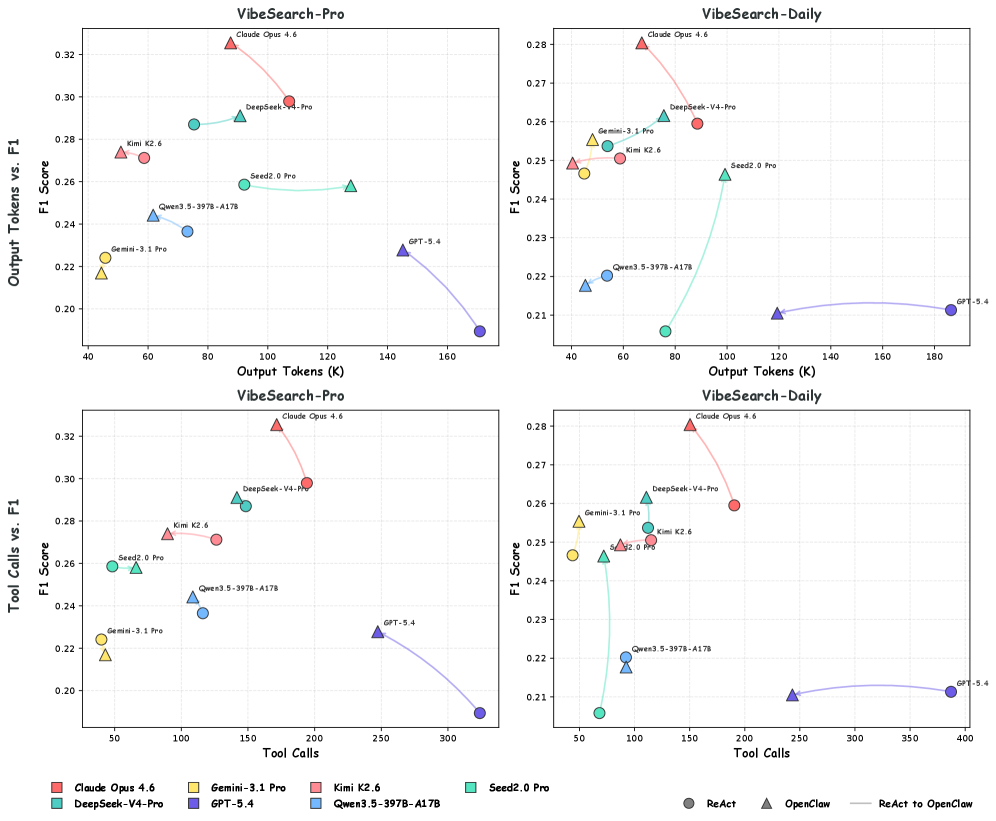
Figure 3 — 리소스 소비와 F1 성능 비교
4. Conclusion & Impact (결론 및 시사점)
본 논문은 현재 LLM 에이전트들이 실시간 검색 환경에서 요구되는 능동적인 의도 도출 및 복잡한 지식 구조화에 근본적인 한계를 가지고 있음을 입증하였다. 연구 결과는 아키텍처 개선만으로는 부족하며, Long-context 추론 능력 향상과 구조적 정보 추출을 위한 모델 차원의 근본적인 발전이 필요함을 시사한다. 이는 향후 에이전트 중심의 실용적 검색 시스템 설계를 위한 중요한 이정표가 될 것이다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] When Search Agents Should Ask: DiscoBench for Clarification-Aware Deep Search
- [논문리뷰] ChartWalker: Benchmarking the Cross-Chart RAG Task
- [논문리뷰] No Resource, No Benchmarks, No Problem? Evaluating and Improving LLMs for Code Generation in No-Resource Languages
- [논문리뷰] MyPCBench: A Benchmark for Personally Intelligent Computer-Use Agents
- [논문리뷰] ChLogic: Evaluating Robustness of Logical Reasoning in Chinese Expressions
Review 의 다른글
- 이전글 [논문리뷰] Verus-SpecGym: An Agentic Environment for Evaluating Specification Autoformalization
- 현재글 : [논문리뷰] VibeSearchBench: Benchmarking Long-horizon Proactive Search in the Wild
- 다음글 [논문리뷰] AdaState: Self-Evolving Anchors for Streaming Video Generation
댓글