[논문리뷰] Thinking Before Constraining: A Unified Decoding Framework for Large Language Models
링크: 논문 PDF로 바로 열기
저자: Ngoc Trinh Hung Nguyen, Alonso Silva, Laith Zumot, Liubov Tupikina, Armen Aghasaryan, Mehwish Alam
1. Key Terms & Definitions (핵심 용어 및 정의)
- In-Writing: LLM의 자유로운 추론 과정(free-form reasoning)과 구조화된 출력 생성(structured generation)을 하나의 호출에서 결합하는 프레임워크입니다.
- Constrained Decoding: Finite-State Machine(FSM)을 활용하여 LLM이 특정 문법이나 정규식(Regex)을 준수하도록 출력 토큰을 제한하는 기법입니다.
- Trigger Token: 추론 단계(unconstrained)에서 구조화된 생성 단계(constrained)로 전환을 유도하는 특정 토큰(예:
<eos>,{)입니다. - Premature Triggering: 제약 조건이 너무 일찍 활성화되어 모델의 진행 중인 추론을 중단시키는 현상으로, 성능 저하의 주요 요인입니다.
- NL-to-Format: 첫 단계에서 자연어(NL)를 생성하고, 두 번째 단계에서 별도의 파서 모델이 이를 대상 형식으로 변환하는 파이프라인 방식입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM의 풍부한 추론 능력과 엄격한 출력 형식 보장 사이의 상충 관계(trade-off)를 해결하고자 합니다. 기존의 Constrained Decoding 방식은 생성 초기부터 문법을 강제하여 모델의 추론 유연성을 제한하고 성능을 떨어뜨리는 문제를 발생시킵니다. 또한, NL-to-Format 방식은 별도의 파서 모델을 활용하므로 추가적인 컴퓨팅 비용이 발생하며, 구조화된 출력의 즉각적인 신뢰성을 보장하지 못합니다. 저자들은 기존 연구들이 추론과 형식을 긴밀하게 결합(coupling)하여 문제를 복잡하게 만든다고 지적하며, 추론 과정을 온전히 보존하면서도 최종 출력의 형식을 보장하는 새로운 프레임워크가 필요함을 역설합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구에서 제안하는 In-Writing은 추론(reasoning)과 구조화된 생성(formatting)을 논리적으로 분리하고, Trigger Token을 사용하여 제약 조건이 필요한 마지막 단계에서만 Constrained Decoding을 활성화합니다. 이 프레임워크는 수식 (5)와 같이 추론 흔적(R)이 제약 조건(F)으로부터 독립적임을 수학적으로 공식화하여, 자유로운 추론 후 구조화된 파싱을 수행함으로써 효율성을 극대화합니다. 특히, <eos>와 같은 단일 Trigger Token 전략은 Premature Triggering 문제를 효과적으로 억제하여 추론의 연속성을 유지합니다. 실험 결과, In-Writing은 다양한 데이터셋에서 기존 Natural Generation 대비 최대 27%의 정확도 향상을 달성했습니다. 또한, 다양한 모델군(Qwen, Llama, Gemma, DeepSeek, SmolLM)에서 NL-to-Format이나 기존 Constrained Decoding보다 우수한 성능을 입증하였으며, 5~20개의 토큰 오버헤드만으로 100%의 형식 준수(parse rate)를 기록하였습니다. 특히 CRANE 대비 symbolic reasoning 작업에서 최대 32%의 성능 우위를 점하며 그 효율성을 증명했습니다.
4. Conclusion & Impact (결론 및 시사점)
본 논문은 In-Writing 프레임워크를 통해 추론과 출력 형식 보장을 분리함으로써 LLM의 생성 능력을 극대화하는 통합적인 디코딩 전략을 제시합니다. Constrained Decoding을 단순히 문법을 강제하는 도구가 아닌, 추론 완료 후의 '파서 및 교정기(post-reasoning parser and corrector)'로 재정의한 점이 학계와 산업계에 큰 시사점을 줍니다. 이 방법론은 복잡한 프롬프트 엔지니어링 없이도 신뢰성 높은 구조화된 데이터를 얻을 수 있게 하여, 산업 현장에서의 LLM 활용성을 대폭 향상시킬 것으로 기대됩니다.
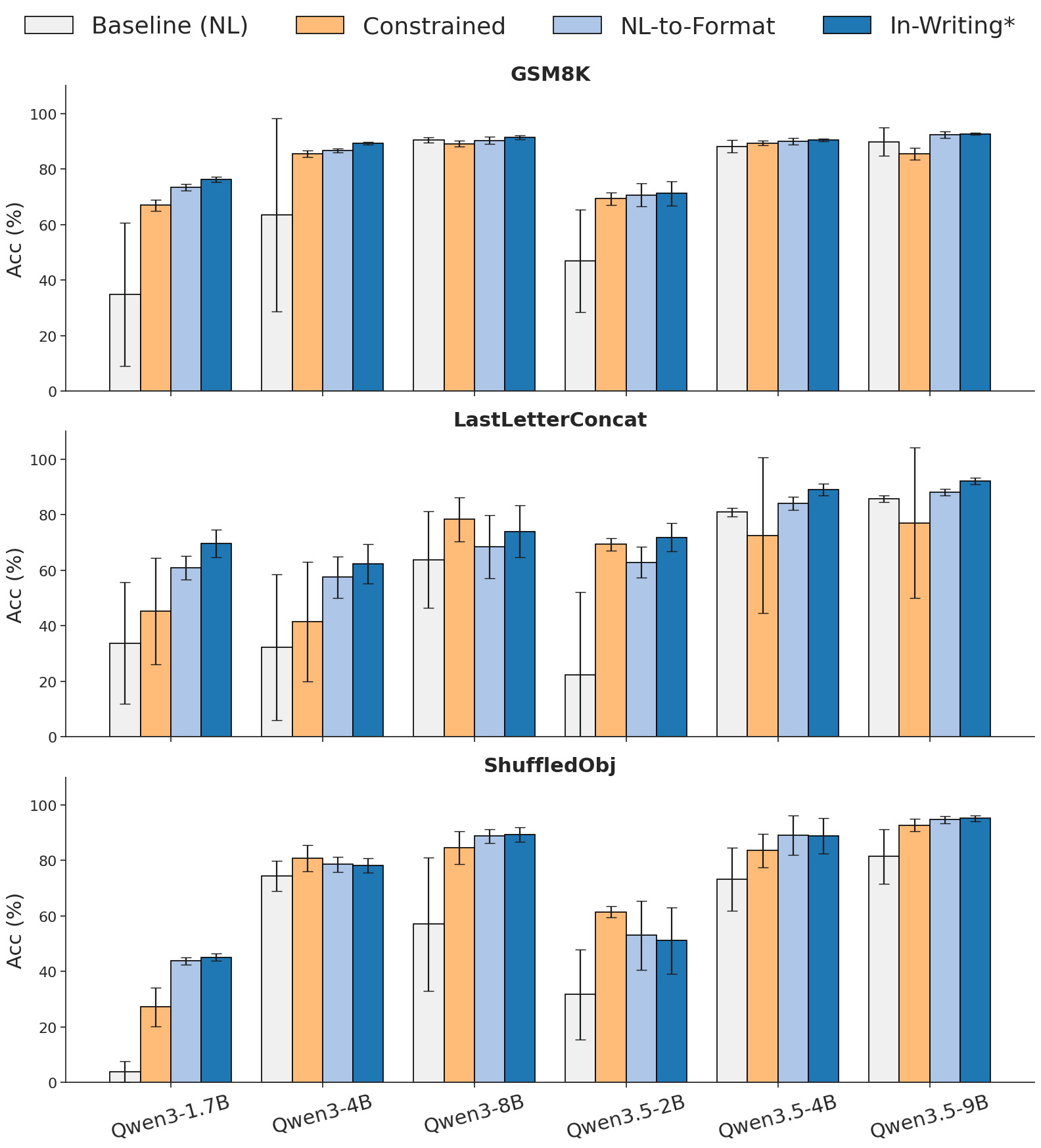
Figure 2 — 모델 크기별 제로샷 성능 비교
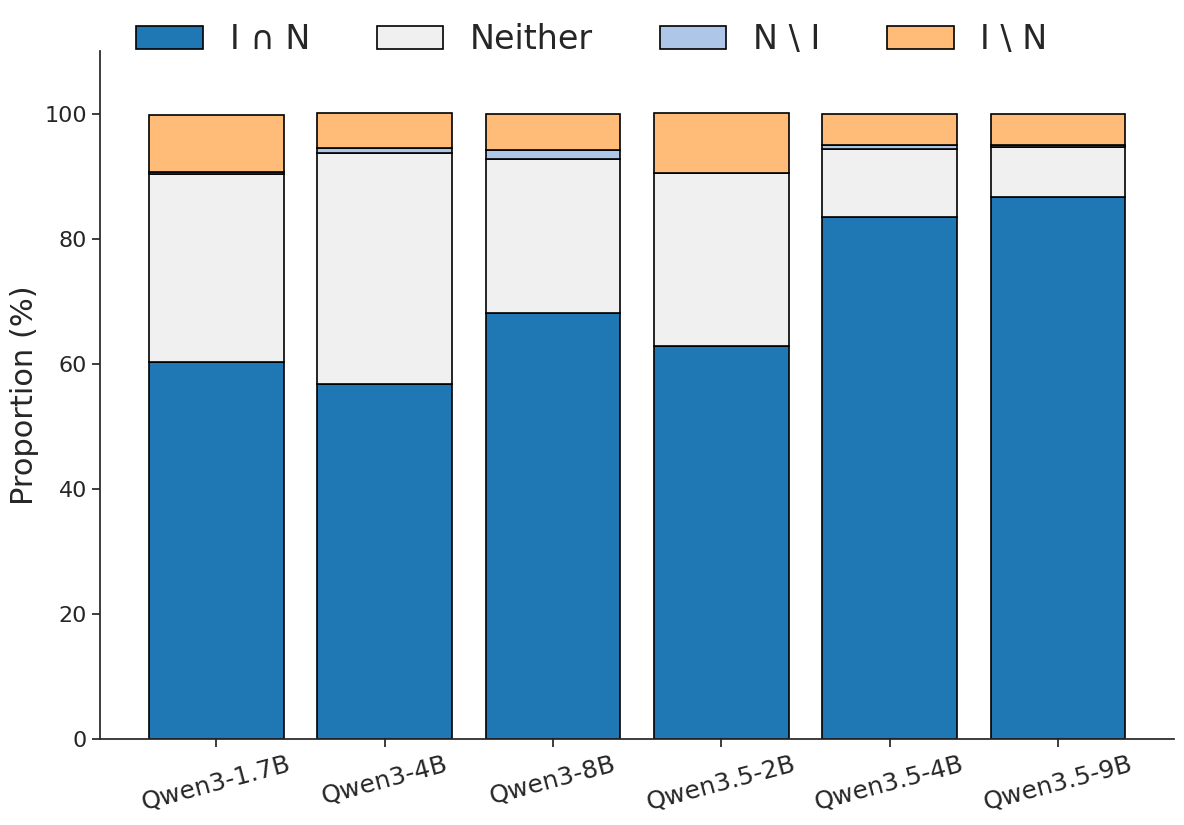
Figure 3 — NL-to-Format과 In-Writing의 오버랩 분석
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Implicit Reasoning for Large Language Model-based Generative Recommendation
- [논문리뷰] AdaSR: Adaptive Streaming Reasoning with Hierarchical Relative Policy Optimization
- [논문리뷰] Reasoning over Grammar: Can Synthetic Linguistic Reasoning Traces Enhance Low-Resource Machine Translation?
- [논문리뷰] Compress-Distill: Reasoning Trace Compression for Efficient Knowledge Distillation
- [논문리뷰] Latent Reasoning with Normalizing Flows
Review 의 다른글
- 이전글 [논문리뷰] SmartDirector: Keyframe-Conditioned Cinematic Video Generation with Narrative Pacing Control
- 현재글 : [논문리뷰] Thinking Before Constraining: A Unified Decoding Framework for Large Language Models
- 다음글 [논문리뷰] Token-Level Generalization in LoRA Adapter Backdoors: Attack Characterization and Behavioral Detection
댓글