[논문리뷰] FRAPPE: Full Input, Residual Output Autoencoding with Projection Pursuit Encoder
링크: 논문 PDF로 바로 열기
메타데이터
저자: Dan Jacobellis, Neeraja J. Yadwadkar
1. Key Terms & Definitions (핵심 용어 및 정의)
- FRAPPE: Full Input, Residual Output Autoencoding의 약자로, 입력 데이터 전체를 활용하여 출력단의 Residual을 예측하는 효율적인 비대칭(asymmetric) 오토인코딩 프레임워크입니다.
- Projection-Pursuit Encoder: 데이터의 특징을 중요한 순서대로 추출하기 위해 학습 가능한 선형 투영을 반복적으로 수행하는 인코더 구조로, 별도의 가중치 추가 없이 순차적인 압축 성능 향상을 가능하게 합니다.
- Asymmetric Codec Design: 인코더의 연산 비용은 극도로 낮추고, 상대적으로 고성능의 하드웨어가 가용한 클라우드 단에서 디코딩 복잡도를 수용하도록 설계된 모델링 철학입니다.
- Zero-overhead variable-rate coding: 동일한 인코더 가중치를 사용하여 추가적인 학습이나 별도의 모듈 없이 출력 Latent 채널 수를 조절함으로써 가변적인 비트레이트 압축을 수행하는 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 로봇, 웨어러블 기기 등 자원이 제한된 환경에서 클라우드 기반의 AI 인식을 원활하게 수행하기 위한 실시간 영상 압축 기술의 한계를 해결하고자 합니다. 기존의 최신 미디어 표준(VVC, AV1)이나 범용적인 DNN 기반 코덱은 높은 인코딩 리소스 요구사항으로 인해 실시간 온-디바이스(on-device) 처리가 어렵다는 문제점이 있습니다. 특히, 기존 학습형 코덱들은 GPU/NPU 가속 없이는 실시간 처리가 불가능하거나, 가변적인 비트레이트 환경에 대응하기 위해 복잡한 재학습 또는 추가적인 연산 비용을 수반합니다. 본 논문은 인코딩 시 발생하는 이러한 성능 저하와 비효율성 문제를 극복하기 위해 가벼운 인코더 구조를 지향하는 새로운 프레임워크를 제안합니다 [Figure 1].

Figure 1 — FRAPPE-Image의 인코더 가중치 시각화
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 입력 데이터 전체를 사용하여 출력 잔차(Residual)를 예측하는 Projection-Pursuit 방식의 FRAPPE 프레임워크를 제안합니다. 제안된 인코더는 병렬적으로 작동하는 독립적인 선형 투영(Linear Projection) 구조를 채택하여, 인코딩 과정에서 순차적인 의존성을 제거하고 DAG(Directed Acyclic Graph) 기반의 병렬 처리를 극대화합니다 [Figure 2]. 인코딩된 각 채널은 중요도에 따라 자동으로 정렬되어, 필요에 따라 채널 수를 절단하는 것만으로 손쉽게 가변 비트레이트 대응이 가능합니다. 실험 결과, FRAPPE-Image는 고압축 환경(~0.1 bpp)에서 AVIF 대비 더 높은 지각적 품질(DISTS)을 제공하면서도 인코딩 속도는 47배 더 빠릅니다 [Figure 3]. 또한, 1080p 30fps의 실시간 인코딩이 저전력 CPU 환경에서 가능함을 입증하였으며, 기존 mbt2018 모델과 비교하여 압도적인 처리량(Throughput) 이점을 달성하였습니다.

Figure 2 — 채널 수 변경에 따른 점진적 복원
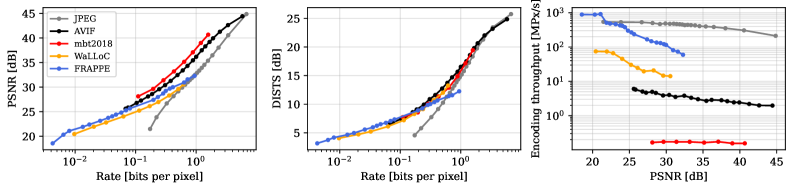
Figure 3 — RD 및 인코딩 처리량 비교 결과
4. Conclusion & Impact (결론 및 시사점)
본 연구는 자원 제한적인 환경에서도 클라우드 지원이 가능한 고효율 비대칭 압축 프레임워크인 FRAPPE를 성공적으로 설계하고 구현하였습니다. 이 프레임워크는 제로 오버헤드 가변 레이트 코딩을 지원하며, 인코딩 비용을 비약적으로 낮춰 모바일 센서 데이터의 실시간 전송 가능성을 크게 확대했습니다. 본 기술은 로봇 공학 및 웨어러블 디바이스 분야에서 대규모 클라우드 AI 처리를 위한 핵심적인 인프라 기술로 활용될 수 있으며, 향후 비디오, 3D 볼륨 데이터 등 다양한 신호 도메인으로의 확장이 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Wan-Streamer v0.2: Higher Resolution, Same Latency
- [논문리뷰] NoPA: Non-Parametric Online 3D Scene Graph Generation
- [논문리뷰] DreamForge-World 0.1 Preview: A Low-Compute Real-Time Controllable World Model
- [논문리뷰] Lip Forcing: Few-Step Autoregressive Diffusion for Real-time Lip Synchronization
- [논문리뷰] SwiftVR: Real-Time One-Step Generative Video Restoration
Review 의 다른글
- 이전글 [논문리뷰] Exploring Autonomous Agentic Data Engineering for Model Specialization
- 현재글 : [논문리뷰] FRAPPE: Full Input, Residual Output Autoencoding with Projection Pursuit Encoder
- 다음글 [논문리뷰] Flat-Pack Bench: Evaluating Spatio-Temporal Understanding in Large Vision-Language Models through Furniture Assembly
댓글