[논문리뷰] Flat-Pack Bench: Evaluating Spatio-Temporal Understanding in Large Vision-Language Models through Furniture Assembly
링크: 논문 PDF로 바로 열기
저자: Aditya Chetan, Eric Cai, Peeyush Kushwaha, Bharath Raj Nagoor Kani, Utkarsh Mall, Qianqian Wang, Noah Snavely, Bharath Hariharan
1. Key Terms & Definitions (핵심 용어 및 정의)
- Flat-Pack Bench: 가구 조립 영상 데이터를 기반으로 LVLM의 세밀한 시공간적 이해 능력을 평가하기 위해 제안된 새로운 벤치마크.
- LVLM (Large Vision-Language Models): 비디오와 텍스트 입력을 모두 처리하여 복잡한 시각적 질문에 답변하고 추론할 수 있는 거대 시각-언어 모델.
- Visual Prompt: 모델이 영상 내 특정 객체나 부품을 명확히 식별할 수 있도록 세그멘테이션 마스크와 레이블을 씌워 제공하는 시각적 힌트.
- Spatio-Temporal Reasoning: 비디오 시퀀스 내에서 객체의 위치(Spatial) 변화와 시간에 따른 이벤트 순서(Temporal)를 인과적으로 추론하는 능력.
- TVA (Temporal Video Agent): SAM2 등 시각적 툴을 사용하여 복잡한 시공간적 질문을 단계별 프로그램으로 분해하여 해결하고자 하는 에이전트 기반 베이스라인.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현대의 LVLM이 일상적인 비디오 이해와 조작 과제를 해결하기 위한 세밀한 시공간적 추론 능력이 부족하다는 문제에서 시작한다. 기존의 많은 비디오 벤치마크는 단편적인 동작 분류나 coarse-grained한 요약에만 집중되어 있어, 가구 조립처럼 다수의 부품이 복잡하게 얽힌 환경에서의 정교한 상호작용을 평가하지 못한다 [Figure 1]. 저자들은 기존 연구들이 uncluttered한 환경이나 간단한 객체에 의존하여 모델의 실질적인 추론 한계를 제대로 드러내지 못했다고 지적하며, 가구 조립이라는 도전적인 시나리오를 통해 이를 체계적으로 평가하고자 한다.
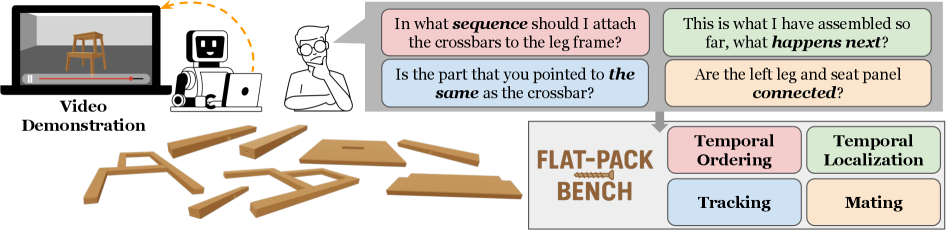
Figure 1 — 가구 조립을 통한 시공간 추론 평가 동기
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 가구 조립 영상을 바탕으로 Temporal Ordering, Temporal Localization, Tracking, Mating 등 4가지 범주의 질문으로 구성된 602개의 질문 세트를 구축하였다 [Figure 2]. 각 질문은 시각적 명확성을 높이기 위해 수동으로 보정된 세그멘테이션과 visual prompt를 활용한다 [Table 1]. 실험 결과, 최신 상용 모델인 GPT-5와 Gemini 2.5 Pro조차 약 33~37%의 정확도를 기록하여, 인간의 성능(약 94%)에 비해 매우 저조한 spatio-temporal reasoning 능력을 보여주었다 [Table 2]. 특히, 영상의 시간적 컨텍스트를 활용하는 대신 부품 ID의 순서나 정적인 시각적 단서에만 의존하는 모델의 편향(shortcut) 문제가 확인되었다. 에이전트 기반 접근법인 TVA 역시 SAM2와 같은 툴의 부정확한 트래킹 성능으로 인해 근본적인 해결책을 제시하지 못했다 [Table 5].

Figure 2 — 벤치마크 구성 요소
4. Conclusion & Impact (결론 및 시사점)
본 연구는 현재의 고성능 LVLM들이 실제 비디오 환경에서의 복잡한 객체 상호작용과 시간적 흐름을 이해하는 데 큰 한계가 있음을 입증하였다. 벤치마크 결과는 모델들이 시공간적 일관성을 유지하는 트래킹이나 물리적 접촉을 판단하는 데 있어 단순한 언어 모델 이상의 정밀한 시각적 grounding이 필요함을 시사한다. 이 벤치마크는 향후 LVLM이 정교한 조작이나 실생활 보조를 위한 agent로 발전하기 위해 극복해야 할 구체적인 기술적 난제를 제시했다는 점에서 중요한 학술적 의의를 갖는다.
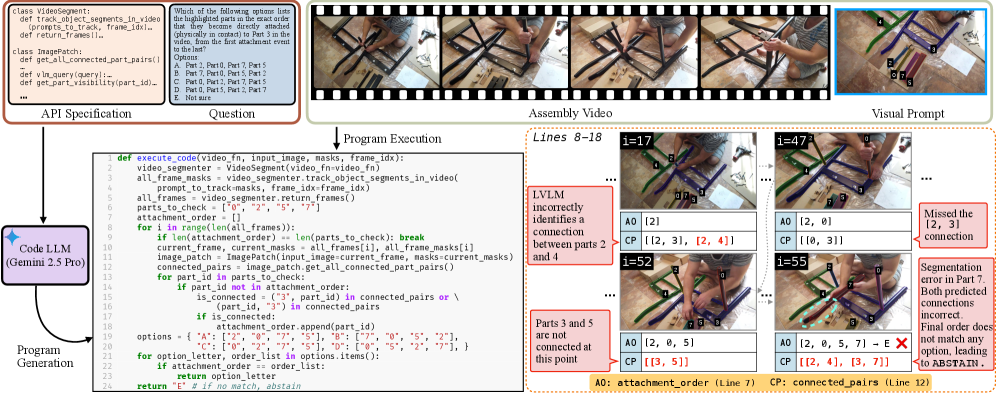
Figure 5 — Temporal Video Agent 개요
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Molmo2: Open Weights and Data for Vision-Language Models with Video Understanding and Grounding
- [논문리뷰] VideoChat3: Fully Open Video MLLM for Efficient and Generalist Video Understanding
- [논문리뷰] VIABench: A Comprehensive Video Benchmark Collected from Blind Individuals for Visual Impairment Assistance
- [논문리뷰] Why Can't I Open My Drawer? Mitigating Object-Driven Shortcuts in Zero-Shot Compositional Action Recognition
- [논문리뷰] Video-Oasis: Rethinking Evaluation of Video Understanding
Review 의 다른글
- 이전글 [논문리뷰] FRAPPE: Full Input, Residual Output Autoencoding with Projection Pursuit Encoder
- 현재글 : [논문리뷰] Flat-Pack Bench: Evaluating Spatio-Temporal Understanding in Large Vision-Language Models through Furniture Assembly
- 다음글 [논문리뷰] From Prompt Injection to Persistent Control: Defending Agentic Harness Against Trojan Backdoors
댓글