[논문리뷰] StreamChar: Long-Horizon Streaming Character Audio-Video Generation with Decoupled Orchestration
링크: 논문 PDF로 바로 열기
메타데이터
저자: Linrui Tian, Qi Wang, Bang Zhang
1. Key Terms & Definitions (핵심 용어 및 정의)
- Orchestrator: LLM을 기반으로 transcript와 과거 이력을 분석하여, 현재 chunk에 적합한 frame-aligned audio condition($\mathbf{c}_{a}$)을 생성하는 모듈입니다.
- DiT (Diffusion Transformer): 오디오와 비디오의 joint denoising을 수행하는 핵심 백본으로, Bidirectional attention을 통해 짧은 시간 내에 고품질의 audio-visual 합성을 담당합니다.
- DMD (Distribution Matching Distillation): 다단계 샘플링 과정을 소수 단계로 압축하여, 생성 품질을 유지하면서 실시간 추론 속도를 달성하기 위한 기술입니다.
- PAP (Progress-Aware Pointer): 생성 중인 오디오와 transcript 간의 동기화를 위해, transcript의 종결 지점을 예측하고 불필요한 부분을 truncation하는 메커니즘입니다.
- Sink-frame/Sink-chunk: 장기 생성 시 발생하는 영상 드리프트를 방지하기 위해, 초기 chunk를 지속적으로 참조하여 시각적 앵커(anchor) 역할을 수행하게 하는 전략입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 실시간 streaming 환경에서 긴 호흡의(long-horizon) 캐릭터 오디오-비디오를 생성할 때 발생하는 transcript-audio 불일치와 시각적 품질 저하 문제를 해결합니다 [Figure 1]. 기존의 통합형(monolithic) 멀티모달 DiT 모델은 global한 문맥 이해와 local한 시공간 denoising을 동시에 수행해야 하므로, 생성 과정에서 의미론적 드리프트(semantic drift)나 오디오-비디오 동기화 오류가 빈번하게 발생합니다. 또한, 실시간성을 위한 과도한 distillation은 모델의 모드 붕괴(mode collapse)와 자동 회귀(autoregressive) 생성 중의 오차 누적을 야기합니다. 이러한 문제를 해결하기 위해 저자들은 global한 계획 수립과 local한 생성 단계를 분리하는 새로운 구조를 제안합니다.
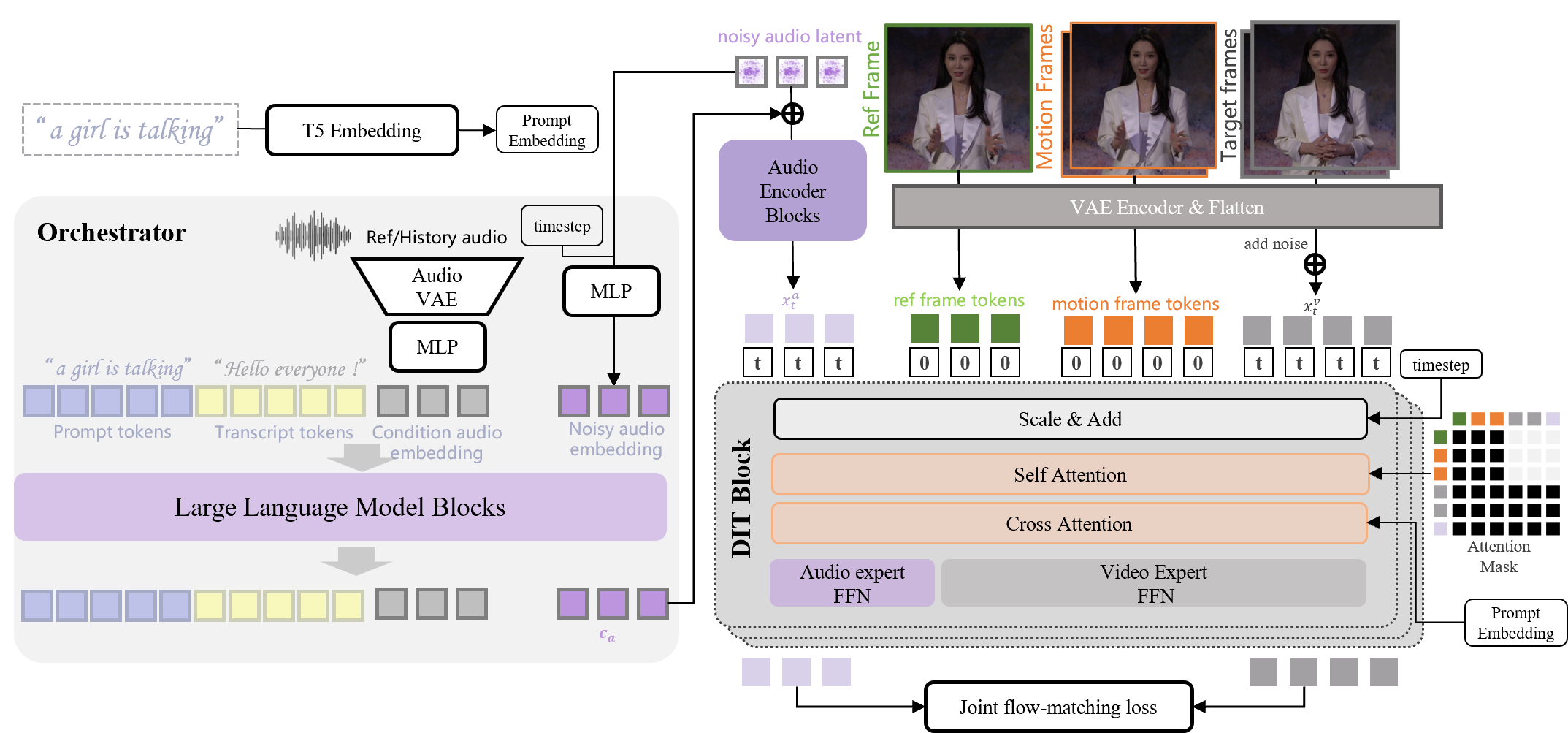
Figure 1 — StreamChar 전체 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 LLM 기반의 Orchestrator와 bidirectional denoising을 수행하는 DiT를 분리한 아키텍처를 제안합니다 [Figure 1]. 전역적인 transcript 계획은 LLM이 담당하고, DiT는 motion frame conditioning을 통해 cross-chunk 연속성을 유지하며 로컬 합성에 집중합니다. 효율적인 배포를 위해 DMD를 사용한 1단계(step reduction)와 online rollout을 통한 2단계(consistency refinement)로 구성된 2단계 distillation 파이프라인을 설계했습니다 [Figure 2]. 특히 PAP를 도입하여 생성 오디오와 transcript의 정확한 정렬을 보장하며, sink-chunk memory를 통해 장기 스트리밍 시 영상 드리프트를 효과적으로 억제합니다 [Figure 3]. 실험 결과, StreamChar는 단일 H100 GPU에서 실시간 스트리밍이 가능하며, WER(3.65%)과 Human Anatomy(0.941) 지표에서 기존의 강력한 non-streaming 및 audio-driven 모델들과 비교하여 동등하거나 우수한 성능을 입증했습니다 [Table 1]. 또한, 긴 시퀀스 생성 시 Drift 수치를 낮게 유지하며 높은 스트리밍 안정성을 보여줍니다 [Table 2].
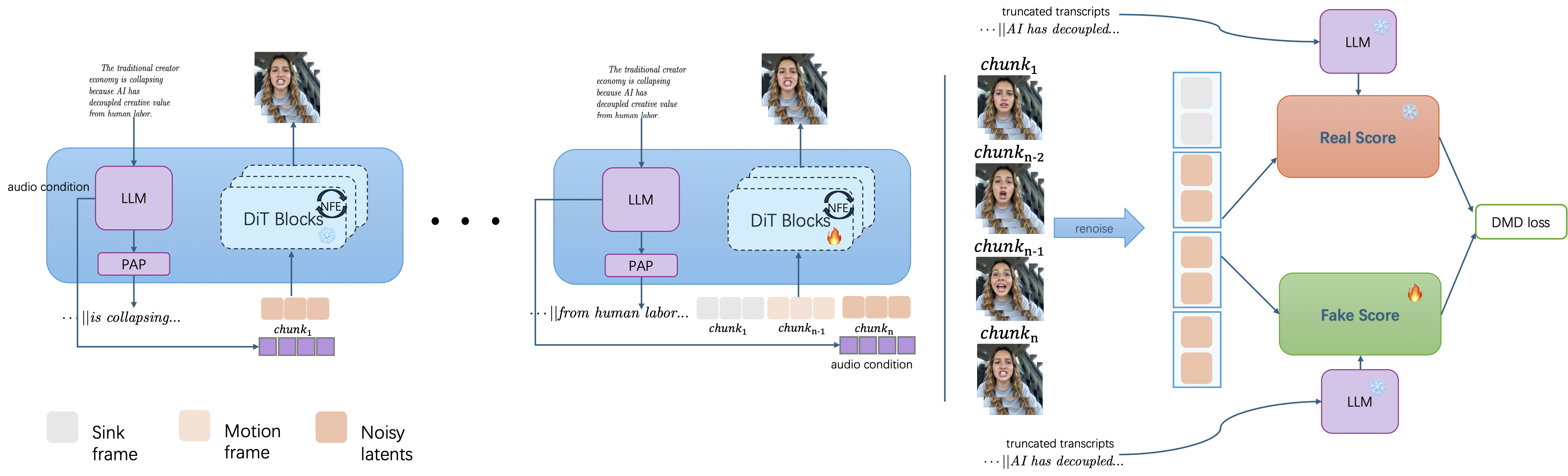
Figure 2 — 온라인 롤아웃 distillation
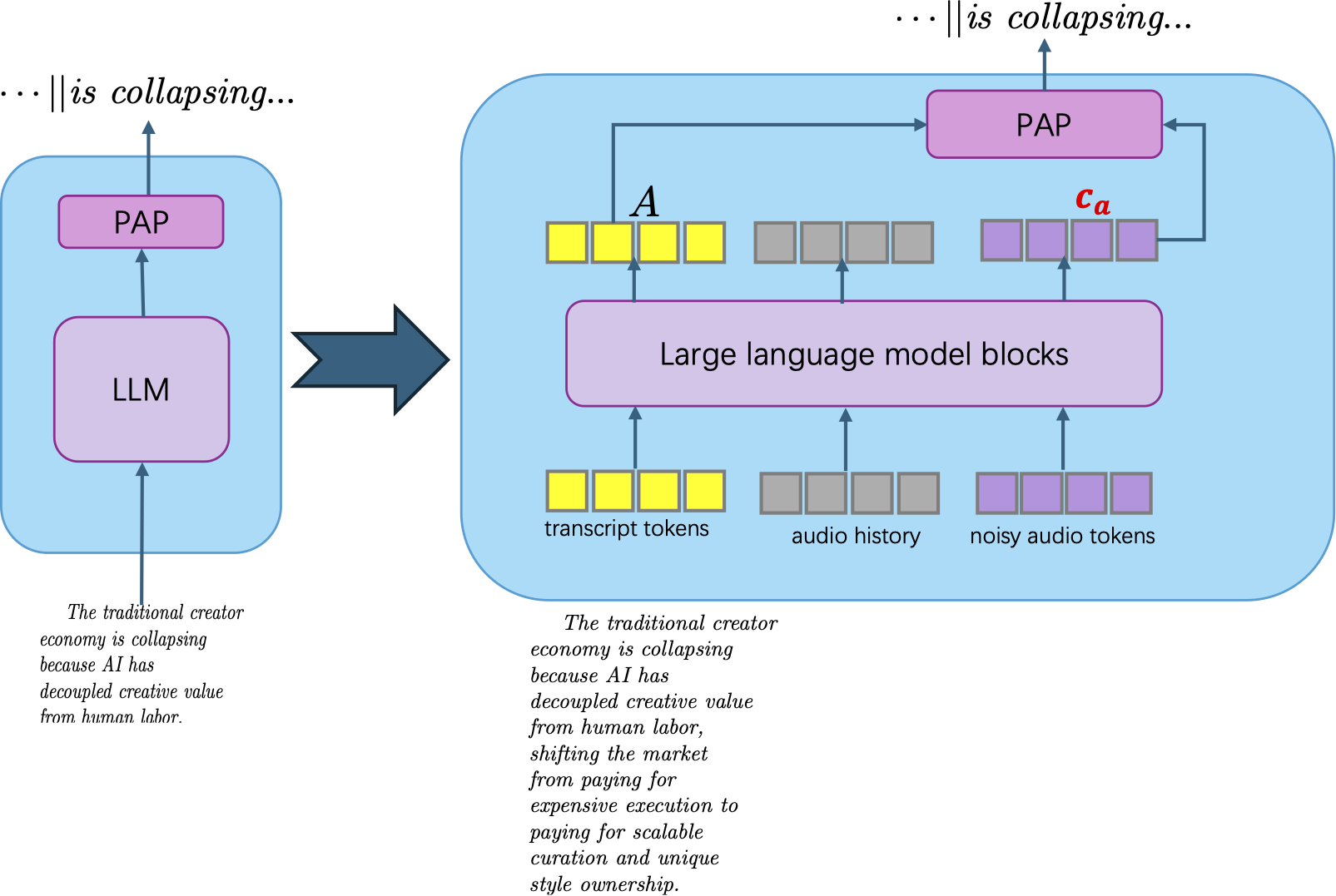
Figure 3 — 진행 인식 포인터(PAP) 구조
4. Conclusion & Impact (결론 및 시사점)
본 연구는 고성능 LLM 오케스트레이션과 효율적인 2단계 distillation 전략을 결합하여, 긴 호흡의 캐릭터 오디오-비디오 생성 문제에 대한 효과적인 해결책을 제시합니다. 이 접근 방식은 연산 부담이 큰 멀티모달 생성 모델을 실시간 상호작용 시스템에 성공적으로 통합할 수 있는 기반을 마련했습니다. 향후 이 연구는 실시간 가상 아바타, 대화형 AI 캐릭터 등의 분야에서 시각적 품질과 스트리밍 안정성을 획기적으로 개선하는 데 중요한 기술적 토대가 될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] DreamID-Omni: Unified Framework for Controllable Human-Centric Audio-Video Generation
- [논문리뷰] SCAIL: Towards Studio-Grade Character Animation via In-Context Learning of 3D-Consistent Pose Representations
- [논문리뷰] Qwen-Music Technical Report
- [논문리뷰] On-Policy Delta Distillation
- [논문리뷰] Boogu-Image-0.1: Boosting Open-Source Unified Multimodal Understanding and Generation
Review 의 다른글
- 이전글 [논문리뷰] Speculative Pipeline Decoding: Higher-Accruacy and Zero-Bubble Speculation via Pipeline Parallelism
- 현재글 : [논문리뷰] StreamChar: Long-Horizon Streaming Character Audio-Video Generation with Decoupled Orchestration
- 다음글 [논문리뷰] StressDream: Steering Video World Models for Robust Policy Evaluation and Improvement
댓글