[논문리뷰] MERIT: Learning Disentangled Music Representations for Audio Similarity
링크: 논문 PDF로 바로 열기
메타데이터
저자: Abhinaba Roy, Junyi Liang, Dorien Herremans
1. Key Terms & Definitions (핵심 용어 및 정의)
- MERIT: 음악의 3대 핵심 요소인 Melody, Rhythm, Timbre를 독립적으로 학습하고 분리(Disentangle)하여 각각에 대한 유사도 점수를 제공하는 프레임워크입니다.
- MERT: 본 논문에서 활용하는 Frozen 상태의 사전 학습된 오디오 인코더로, 대규모 데이터를 통해 학습된 풍부한 음악 표현(Representation)을 제공합니다.
- Projection Head: MERT 백본 위에 구축된 경량 MLP(Multi-Layer Perceptron) 구조로, 특정 음악적 요소(요소별 Head)를 분리된 잠재 공간으로 매핑하는 역할을 합니다.
- Circle Loss: 훈련 과정에서 Triplet 간의 유사도 마진을 극대화하여 효율적이고 안정적인 표현 학습을 가능하게 하는 최적화 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 음악 유사도 모델이 여러 음악적 요소를 하나의 Monolithic 점수로 융합하여 표현함에 따라 발생하는 해석 가능성 및 세밀한 쿼리 제어의 한계를 해결하고자 합니다 [Figure 1]. 기존의 CLAP이나 MuLan 같은 임베딩 모델은 Melody, Rhythm, Timbre를 구분하지 않고 고정된 통합 유사도만을 제공하여, 사용자가 원하는 특정 차원의 유사성을 탐색하는 데 한계가 있습니다. 이러한 문제를 극복하기 위해 본 연구는 각 요소를 독립적으로 분리할 수 있는 프레임워크를 제안합니다. 특히 실제 오디오 환경에서는 각 요소가 복합적으로 얽혀 있어 학습이 어렵다는 점에 착안하여, 이를 해결할 새로운 데이터 파이프라인을 구축하였습니다.
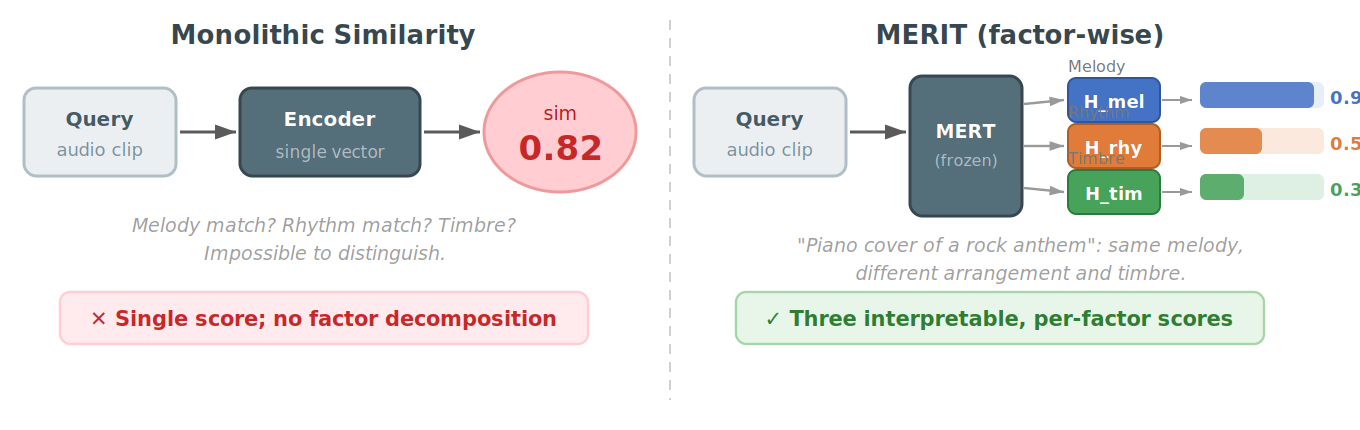
Figure 1 — 통합 vs 요소별 유사도 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Frozen MERT 백본을 공유하면서 학습 가능한 세 개의 독립적인 Projection Head를 사용하여 요소별 Disentangled Representation을 추출하는 MERIT 아키텍처를 제안합니다 [Figure 2]. 데이터 병목 문제를 해결하기 위해 Conditional Audio Generation과 소스 분리 기술을 활용하여, 특정 요소만 변화하는 Triplet 학습 데이터를 생성하였습니다. 학습된 모델은 평가 결과 Triplet Accuracy 지표에서 각 타겟 요소별로 99.6% 이상의 높은 정확도를 기록하며 기존 통합 모델 대비 월등한 성능을 보였습니다 [Table 2]. 특히, Zero-Shot 외부 데이터셋 평가(MUSDB18-HQ, Ballroom Dataset)에서 각 헤드가 의도된 요소에만 강력하게 반응하고 다른 차원에는 불변성을 유지하는 Selectivity를 입증하였습니다. 최종적으로 이러한 요소별 점수의 조합(Score Fusion)을 통해 개별 모델보다 더 나은 검색 성능을 확보할 수 있음을 확인하였습니다 [Figure 3].
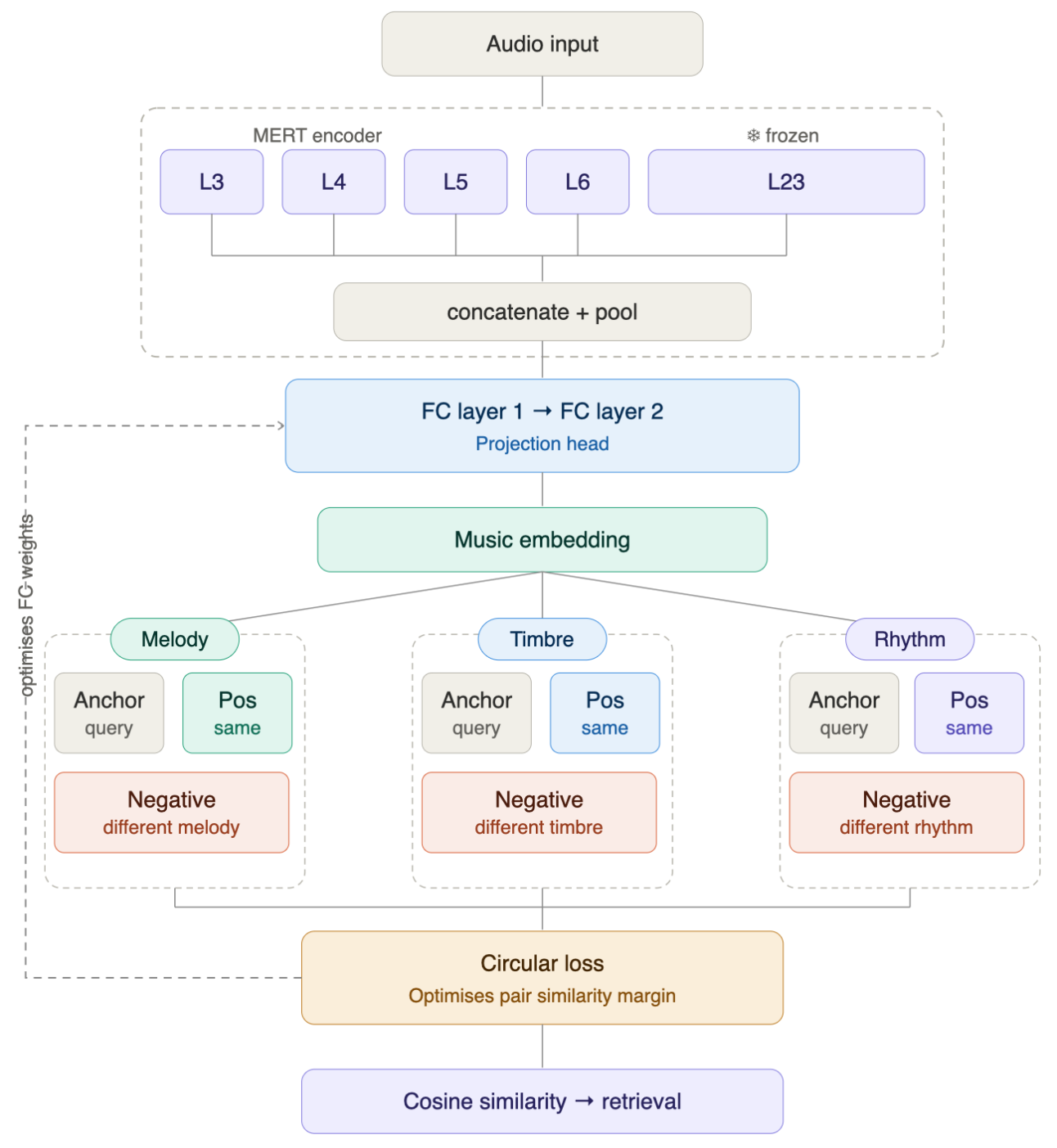
Figure 2 — MERIT 아키텍처 및 파이프라인
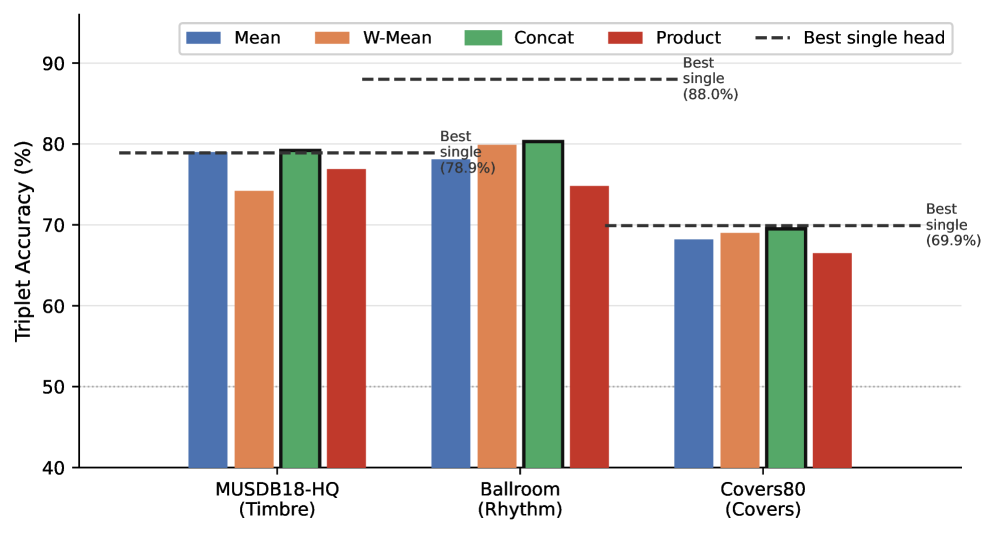
Figure 3 — 점수 융합 전략 비교
4. Conclusion & Impact (결론 및 시사점)
본 연구는 MERIT을 통해 음악의 복잡한 차원을 독립적인 유사도 공간으로 성공적으로 분리하였으며, 이는 음악 정보 검색 및 해석 가능성 측면에서 중요한 진전을 의미합니다. 제안된 프레임워크는 사전 학습된 Frozen 백본의 지식을 유지하면서도 특정 요소에 대한 강력한 제어력을 확보했다는 점에서 학계 및 산업계에 큰 시사점을 제공합니다. 본 연구 결과는 향후 화성(Harmony) 등 더 다양한 음악적 요소를 확장하거나, 더 통합된 Multi-Head Transformer 구조로 발전할 수 있는 강력한 토대를 마련하였습니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] InfoNCE Induces Gaussian Distribution
- [논문리뷰] TabEmbed: Benchmarking and Learning Generalist Embeddings for Tabular Understanding
- [논문리뷰] In Pursuit of Pixel Supervision for Visual Pre-training
- [논문리뷰] Towards Scalable Pre-training of Visual Tokenizers for Generation
- [논문리뷰] UniME-V2: MLLM-as-a-Judge for Universal Multimodal Embedding Learning
Review 의 다른글
- 이전글 [논문리뷰] Language Models Need Sleep: Learning to Self-Modify and Consolidate Memories
- 현재글 : [논문리뷰] MERIT: Learning Disentangled Music Representations for Audio Similarity
- 다음글 [논문리뷰] MIRA: Mid-training Rubric Anchoring for Source-Aware Data Selection
댓글