[논문리뷰] MIRA: Mid-training Rubric Anchoring for Source-Aware Data Selection
링크: 논문 PDF로 바로 열기
메타데이터
저자: Haowen Wang, Yaxin Du, Jian Yang, Jiajun Wu, Shukai Liu, Yuxuan Zhang, Pingjie Wang, Siheng Chen, Tuney Zheng, Ming Zhou, Xianglong Liu, Bryan Dai
1. Key Terms & Definitions (핵심 용어 및 정의)
- Mid-training: 거대 언어 모델(LLM)의 Pretraining과 최종 Post-training 단계 사이에서, 특화된 Capability(코딩, 수학적 추론 등)를 강화하기 위해 수행되는 데이터 학습 단계입니다.
- Rubric Discovery: 다양한 데이터 소스에 대해 고정된 기준을 적용하는 대신, Teacher 모델을 활용하여 각 소스 그룹의 특성에 맞는 품질 평가 기준(Dimension)을 스스로 도출하는 과정입니다.
- Anchored Judge Distillation: 발견된 Rubric을 바탕으로 Teacher 모델의 판단을 학습하여, 전체 말뭉치(Full Corpus)에 대해 효율적으로 추론할 수 있는 경량화된 Student Scorer를 생성하는 기법입니다.
- Source-Conditioned Reliability Aggregation: Student Scorer의 예측값 중 신뢰도가 낮은 특정 차원(Dimension)을 필터링하거나 마스킹하여 최종 점수의 Robustness를 높이는 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 이질적인(Heterogeneous) Mid-training 데이터 혼합물에서 효과적인 데이터 선택이 어렵다는 문제를 해결하고자 합니다. 기존의 Pretraining 중심 필터링 기법은 확장성은 높으나 데이터의 의미론적 품질(Semantic Quality)을 정의하지 못하며, Post-training 기법은 강력한 의미적 감독을 제공하지만 고정된 기준만을 가정하여 다양한 소스 형태를 처리하기 어렵습니다. 이러한 불일치(Mismatch)로 인해 모델 학습에 기여하는 데이터 선별에 한계가 발생합니다 [Figure 1]. 따라서 본 연구는 소스별 특성을 적응적으로 반영하면서도 대규모 말뭉치에 적용 가능한 새로운 데이터 선택 프레임워크가 필요함을 시사합니다.
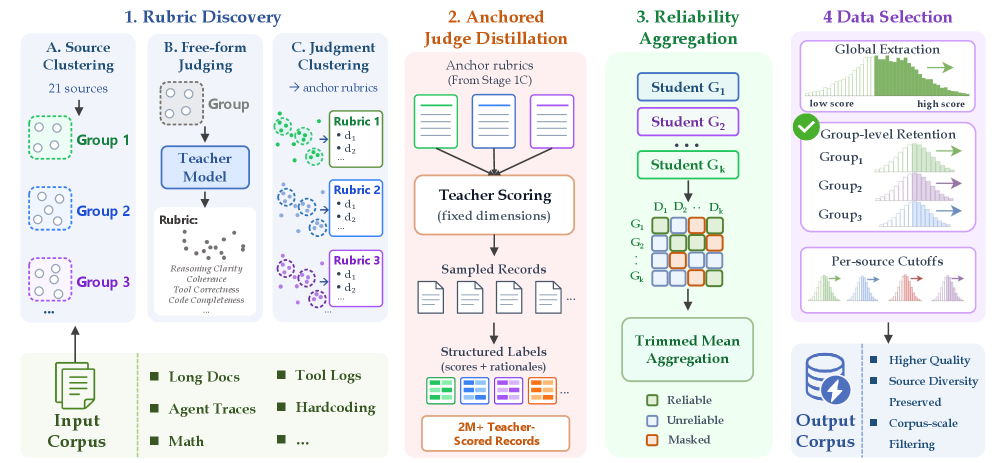
Figure 1 — MIRA 파이프라인 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문에서 제안하는 MIRA는 Self-anchored rubric discovery를 통해 데이터 선택의 Rubric을 데이터로부터 직접 도출하는 프레임워크입니다. 먼저 데이터 소스들을 의미론적으로 유사한 그룹으로 클러스터링하고, Teacher 모델을 통해 그룹별 고유 품질 기준(Anchor Dimensions)을 추출합니다. 이후 추출된 Anchor를 바탕으로 Teacher가 상세 점수와 근거를 생성하게 하고, 이를 경량 Student Scorer에 증류(Distillation)하여 전체 데이터에 대한 확장 가능한 스코어링을 수행합니다. 최종적으로는 Source-conditioned reliability aggregation을 통해 학생 모델의 차원별 예측 오류를 보정하고, 그룹별 임계값(Threshold)을 적용하여 데이터를 선별합니다 [Figure 1].
실험 결과, MIRA-Group 기법은 50B 토큰의 전체 데이터셋 대비 절반인 25B 토큰만 사용하고도, 다수의 코드 벤치마크에서 우수한 성능을 입증했습니다. Macro Average 기준 64.20점을 기록하며, Random sampling(63.23), DataMan(63.01), DSIR(59.55) 등 주요 Baseline을 상회하는 성과를 보였습니다 [Table 1]. 특히 시퀀스 길이에 따른 성능 분석에서 MIRA는 기존 필터링 기법과 달리 길이 변화에 강건(Robust)한 score profile을 유지함을 확인했습니다 [Figure 2].
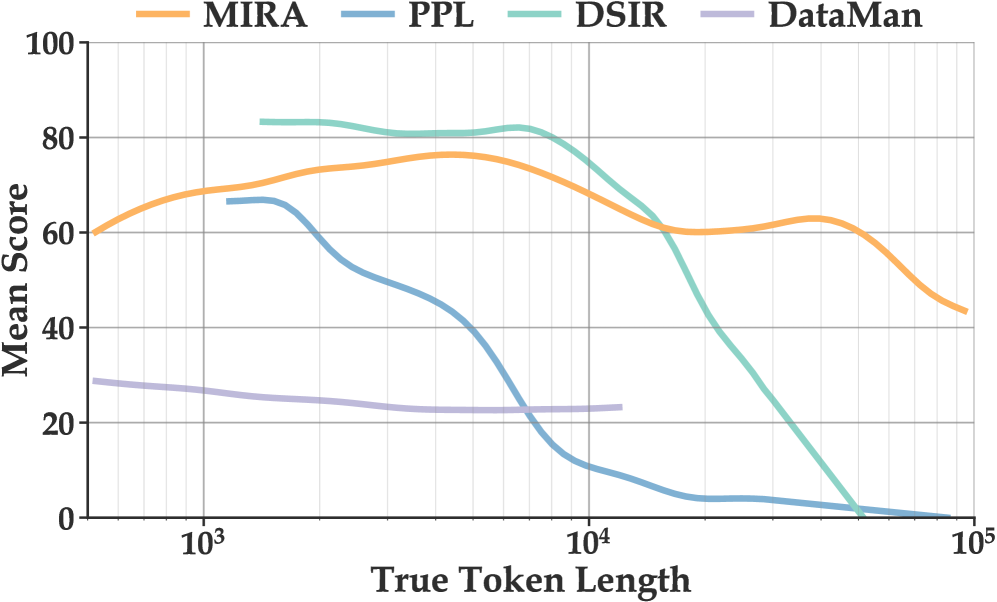
Figure 2 — 길이 변화에 따른 점수 안정성
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Mid-training 과정에서의 데이터 선택 문제를 소스 적응형(Source-adaptive) 의미 품질 평가로 재정의하여 성공적으로 해결했습니다. MIRA 프레임워크는 Rubric 도출과 증류 기반 스코어링을 결합함으로써, 모델 학습 효율성을 극대화함과 동시에 데이터의 다양성을 효과적으로 보존하는 방법을 제시했습니다. 이러한 접근 방식은 향후 데이터 중심(Data-centric) LLM 학습 파이프라인에서 자원 제약 상황에서의 모델 최적화에 중요한 방법론적 토대를 마련할 것으로 평가됩니다.
Figure 3 — 신뢰도 기반 마스킹 분석
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] ToolSense: A Diagnostic Framework for Auditing Parametric Tool Knowledge in LLMs
- [논문리뷰] EvoBrowseComp: Benchmarking Search Agents on Evolving Knowledge
- [논문리뷰] ArogyaSutra: A Multi-Agent Framework for Multimodal Medical Reasoning in Indic Languages
- [논문리뷰] Online Skill Learning for Web Agents via State-Grounded Dynamic Retrieval
- [논문리뷰] Kwai Keye-VL-2.0 Technical Report
Review 의 다른글
- 이전글 [논문리뷰] MERIT: Learning Disentangled Music Representations for Audio Similarity
- 현재글 : [논문리뷰] MIRA: Mid-training Rubric Anchoring for Source-Aware Data Selection
- 다음글 [논문리뷰] Mitigating Perceptual Judgment Bias in Multimodal LLM-as-a-Judge via Perceptual Perturbation and Reward Modeling
댓글