[논문리뷰] Value-Aware Stochastic KV Cache Eviction for Reasoning Models
링크: 논문 PDF로 바로 열기
메타데이터
저자: Ting-Yun Chang, Harvey Yiyun Fu, Deqing Fu, Chenghao Yang, Jesse Thomason, Robin Jia
1. Key Terms & Definitions (핵심 용어 및 정의)
- KV Cache: LLM의 Inference 과정에서 이전 토큰의 정보를 저장하는 메모리 공간으로, 생성 단계에서 반복적인 계산을 피하기 위해 사용됨.
- Eviction: 고정된 메모리 예산 내에서 중요도가 낮은 KV pair를 제거하여 메모리 효율성을 확보하는 기법.
- Range (Value-state Magnitude): Value 벡터의 최댓값과 최솟값의 차이로, 이 값이 큰 outlier들은 모델의 추론 성능 유지에 매우 중요한 역할을 함.
- Stochasticity: KV cache 삭제 시 결정론적 방식(예: Top-k) 대신 확률적 샘플링이나 무작위성을 도입하여 캐시 내 정보의 다양성(Diversity)을 높이는 전략.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 Reasoning 모델이 복잡한 추론 과정에서 생성하는 긴 출력(Chain of Thought)으로 인해 발생하는 심각한 메모리 및 연산 병목 현상을 해결하고자 한다. 기존의 KV cache Selection 기법은 정확도는 높으나 메모리 사용량이 시퀀스 길이에 따라 선형적으로 증가하는 한계가 있으며, 기존의 Eviction 기법은 고정된 메모리 효율성은 제공하지만 추론 정확도가 크게 하락하는 문제를 가진다. 저자들은 Value 상태의 magnitude가 큰 토큰을 삭제할 경우 모델이 반복적인 루프에 빠지는 등 치명적인 성능 저하가 발생함을 확인하였다 [Figure 2]. 따라서, 본 연구는 정확도를 보존하면서도 정적인 메모리 Footprint를 유지하는 새로운 Eviction 프레임워크인 VaSE를 제안한다.
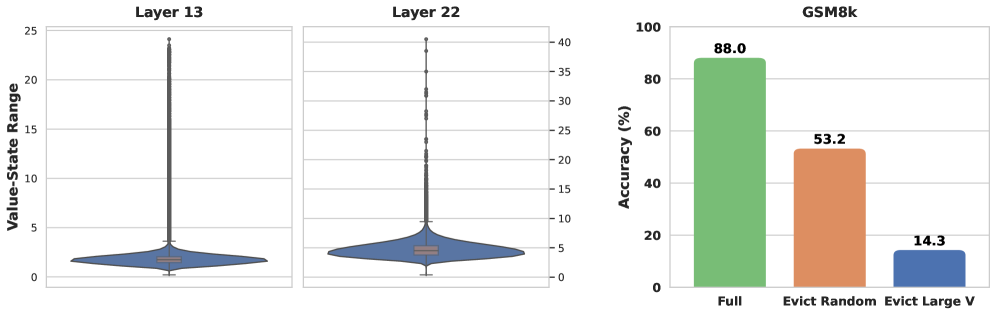
Figure 2 — Value-state 분포와 중요성
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Value state의 중요도를 반영하고 삭제 과정에 확률적 요소를 도입하는 Value-aware Stochastic KV Cache Eviction (VaSE)를 제안한다 [Figure 1]. VaSE는 크게 VaSE-AttnV와 VaSE-DKV 두 가지 변형으로 나뉘며, 전자는 대규모 magnitude를 가진 Value 상태를 보존하고 나머지 공간에 대해 확률적으로 샘플링하며, 후자는 CUR decomposition 기반의 leverage score와 함께 확률적인 가우시안 투영(Gaussian Projection)을 통해 다양성을 확보한다 [Table 1]. 실험 결과, VaSE는 6개의 추론 작업에서 기존 SOTA Eviction 기법인 R-KV 대비 평균 4.4%~4.9% 향상된 정확도를 보였다 [Table 2]. 특히, VaSE-AttnV는 메모리 사용량이 시퀀스 길이에 비례하는 기존 Selection 기법인 SeerAttention-R과 대등한 성능을 보이면서도 더 나은 효율성을 달성하였다 [Figure 3]. 또한, Value state의 Range가 클수록 per-token quantization 시 더 큰 재구성 오차(Reconstruction Error)가 발생함을 입증하여, Value-aware 접근 방식의 타당성을 강화하였다 [Figure 5].
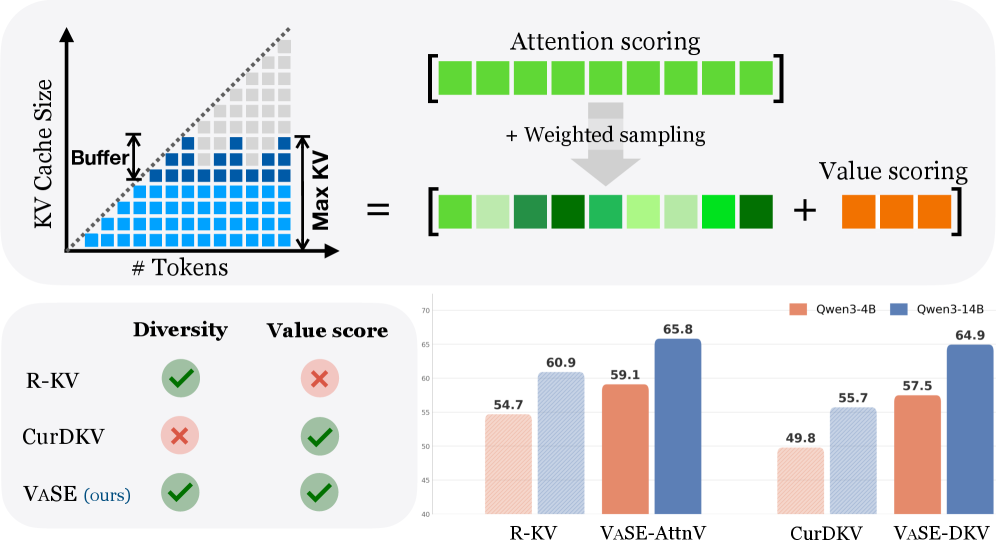
Figure 1 — VaSE 프레임워크 개요
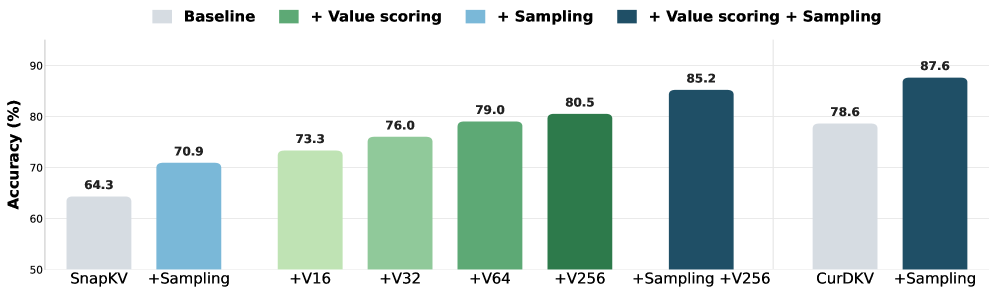
Figure 3 — GSM8K 정확도 비교
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Value-state의 크기와 확률적 샘플링이 KV cache 관리의 핵심 축임을 밝혀내고 이를 최적화한 VaSE를 성공적으로 제시하였다. VaSE는 별도의 추가 학습이 필요 없는 Training-free 기법으로, 추론 성능과 메모리 효율성 사이의 절충점을 획기적으로 개선하였다. 이 연구는 Reasoning 모델의 Inference 효율을 극대화하여 실제 서비스 환경에서 대규모 추론 엔진을 구축하는 데 중요한 기여를 한다. 또한, KV cache 압축뿐만 아니라 모델 양자화 분야에도 광범위하게 적용 가능한 학술적 통찰을 제공한다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] FlashMemory-DeepSeek-V4: Lightning Index Ultra-Long Context via Lookahead Sparse Attention
- [논문리뷰] DenoiseRL: Bootstrapping Reasoning Models to Recover from Noisy Prefixes
- [논문리뷰] MISA: Mixture of Indexer Sparse Attention for Long-Context LLM Inference
- [논문리뷰] Universal YOCO for Efficient Depth Scaling
- [논문리뷰] Free(): Learning to Forget in Malloc-Only Reasoning Models
Review 의 다른글
- 이전글 [논문리뷰] Ultralytics YOLO26: Unified Real-Time End-to-End Vision Models
- 현재글 : [논문리뷰] Value-Aware Stochastic KV Cache Eviction for Reasoning Models
- 다음글 [논문리뷰] World Models Meet Language Models: On the Complementarity of Concrete and Abstract Reasoning
댓글