[논문리뷰] AAD-1: Asymmetric Adversarial Distillation for One-Step Autoregressive Video Generation
링크: 논문 PDF로 바로 열기
메타데이터
저자: Haobo Li, Yanhong Zeng, Yunhong Lu, Jiapeng Zhu, Hao Ouyang, Qiuyu Wang, Ka Leong Cheng, Yujun Shen, Zhipeng Zhang
1. Key Terms & Definitions (핵심 용어 및 정의)
- One-Step Autoregressive Video Generation: 이전 프레임의 맥락을 바탕으로 다음 프레임을 단 한 번의 추론 단계(NFE=1)로 생성하는 효율적인 영상 생성 기법입니다.
- Asymmetric Adversarial Distillation (AAD): 생성자는 인과적(Causal) 구조를 유지하여 스트리밍을 지원하고, 판별자는 비인과적(Bidirectional) 구조를 통해 전체 시퀀스를 평가하는 비대칭적 적대적 증류 방식입니다.
- Holistic Discrimination: 판별자가 전체 비디오 시퀀스를 하나의 비인과적 맥락으로 분석하여 단일 realism 점수를 산출함으로써, 국소적인 프레임 단위 평가로는 포착하기 어려운 장기적인 시간적 드리프트(drift)를 탐지하는 기술입니다.
- DMD (Distribution Matching Distillation): 교사 모델의 분포를 학생 모델이 모사하도록 유도하는 분포 수준의 증류 기법으로, AAD-1에서는 적대적 학습 전 안정적인 초기화를 위해 사용됩니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 one-step autoregressive video generation에서 발생하는 motion collapse와 학습 불안정성 문제를 해결하고자 합니다 [Figure 1]. 기존의 적대적 증류 기법은 대개 생성자와 판별자가 동일한 인과적 구조를 공유하는 대칭적 설계를 채택하는데, 이는 판별자가 미래 정보를 보지 못해 시간에 따라 누적되는 temporal degradation을 효과적으로 평가하지 못한다는 한계가 있습니다. 결과적으로 생성된 비디오는 초기 프레임에 고착되거나 시각적 일관성을 상실하는 motion collapse 현상을 겪게 됩니다. 또한, 학습 초기 단계에서 학생 모델의 성능이 데이터 분포와 멀리 떨어져 있을 경우, 처음부터 적대적 학습을 수행하면 학습 역학이 크게 불안정해지는 고질적인 문제가 존재합니다.

Figure 1 — AAD-1 전체 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Asymmetric Adversarial Distillation 프레임워크인 AAD-1을 제안하며, 이를 위해 비대칭적 구조와 3단계 학습 전략을 도입합니다 [Figure 3]. AAD-1의 핵심은 생성자는 causal 구조를 유지하여 실시간 스트리밍이 가능하게 하되, 판별자는 bidirectional attention을 사용하여 전체 비디오 시퀀스를 통합적으로 평가하는 Holistic Discrimination을 적용하는 것입니다 [Figure 2]. 학습은 1단계 ODE 초기화, 2단계 DMD 기반 warm-up, 3단계 비대칭적 적대적 정교화(refinement) 과정을 거치며, 이를 통해 one-step 모델임에도 안정적인 학습과 고품질 생성을 구현합니다. 실험 결과, VBench 평가에서 AAD-1은 기존 multi-step autoregressive 기법(예: CausVid, Self Forcing) 대비 훨씬 적은 연산 비용으로도 우수한 주체 일관성(94.34)과 배경 일관성(95.08)을 달성했습니다 [Table 1]. 특히, 정성적 분석 결과 기존 방식들은 장기 생성 시 identity drift가 발생하지만, AAD-1은 320 프레임까지 안정적인 영상을 생성함을 확인하였습니다 [Figure 4, Figure 7].
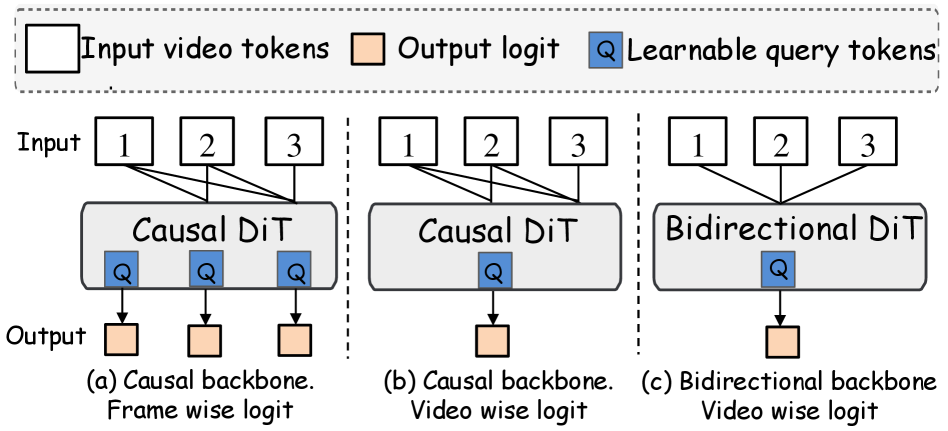
Figure 2 — 판별자 구조 비교
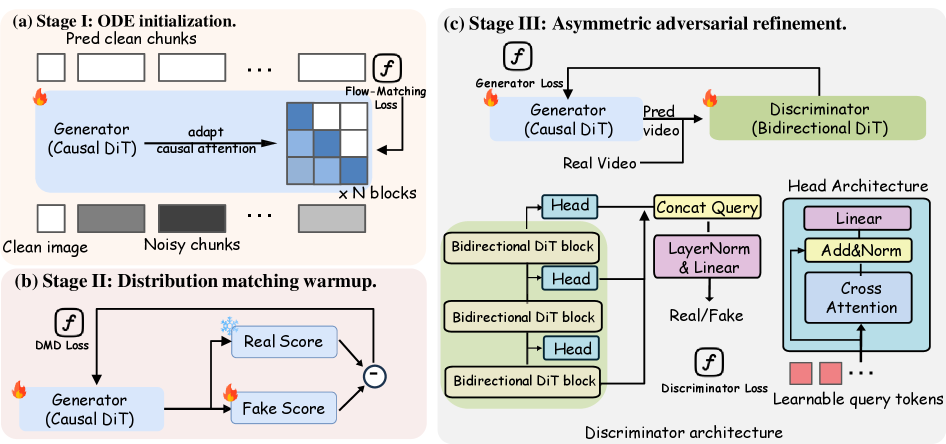
Figure 3 — 3단계 학습 파이프라인
4. Conclusion & Impact (결론 및 시사점)
본 논문은 비대칭적 적대적 증류 구조와 단계적 학습 방식을 통해 one-step autoregressive video generation의 한계를 성공적으로 극복했습니다. 본 연구는 실시간 인터랙티브 비디오 스트리밍 시스템 구축에 있어 필수적인 효율성과 고품질 영상 생성의 균형을 제시했다는 점에서 큰 학술적, 산업적 의의를 갖습니다. 특히, 판별자의 비대칭적 설계가 생성 모델의 장기 시간적 일관성 향상에 결정적임을 증명함으로써, 향후 고해상도 고속 비디오 생성 연구의 새로운 지표를 마련했습니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Context Forcing: Consistent Autoregressive Video Generation with Long Context
- [논문리뷰] VideoMDM: Towards 3D Human Motion Generation From 2D Supervision
- [논문리뷰] MaskAlign: Token-Subset Representation Alignment for Efficient Diffusion Training
- [논문리뷰] High-Fidelity Two-Step Image Generation via Teacher-Aligned End-to-End Distillation
- [논문리뷰] MilliVid: Hierarchical Latents for Long-Range Consistency in Video Generation
Review 의 다른글
- 이전글 [논문리뷰] αDepth: Learning Single-Pass Soft Boundary Decomposition for Stereo Conversion
- 현재글 : [논문리뷰] AAD-1: Asymmetric Adversarial Distillation for One-Step Autoregressive Video Generation
- 다음글 [논문리뷰] AUDITFLOW: Executable Symbolic Environments for Structured Financial Reporting Verification
댓글