[논문리뷰] Revising Context, Shifting Simulated Stance: Auditing LLM-Based Stance Simulation in Online Discussions
링크: 논문 PDF로 바로 열기
메타데이터
저자: Xinnong Zhang, Wanting Shan, Hanjia Lyu, Zhongyu Wei, Jiebo Luo
1. Key Terms & Definitions (핵심 용어 및 정의)
- Counterfactual Context Revision: 원본 대화의 마지막 사용자 메시지를 제어된 전략으로 수정하여, 동일한 상황에서 모델의 예측(Stance)이 어떻게 변화하는지 검증하는 프레임워크입니다.
- Average Directional Stance Shift: 수정된 문맥 하에서 시뮬레이션된 Stance가 얼마나 지지적(Positive) 또는 반대(Negative) 방향으로 이동했는지를 정량화한 지표입니다.
- Stance Transition Rate: 수정 전후의 Stance 라벨 변화(Supportive, Neutral, Opposing) 패턴을 측정하여 모델의 민감도를 평가하는 지표입니다.
- Multimodal Revision: 단순 텍스트 수정을 넘어, Meme을 활용해 humor, emotional framing 등 시각적 맥락을 도입하여 시뮬레이션의 변화를 유도하는 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 LLM이 온라인 사용자들의 의견을 시뮬레이션할 때, 이것이 실제 신념의 반영인지 아니면 문맥에 따른 모델의 표면적 반응인지를 체계적으로 파악하고자 합니다. 기존의 LLM 기반 Stance 시뮬레이션 연구들은 단일 정적 문맥에서의 예측에 치중되어 있어, 대화 문맥의 사소한 변화가 모델의 결과값에 미치는 영향력을 규명하는 데 한계가 있었습니다. 저자들은 [Figure 2]에 제시된 바와 같이, 원본 대화에서 수정한 대화로의 전환 과정을 통해 모델이 실제 인간의 의견 역학을 안정적으로 모사하는지 감사(Audit)할 수 있는 새로운 접근 방식을 제안합니다.
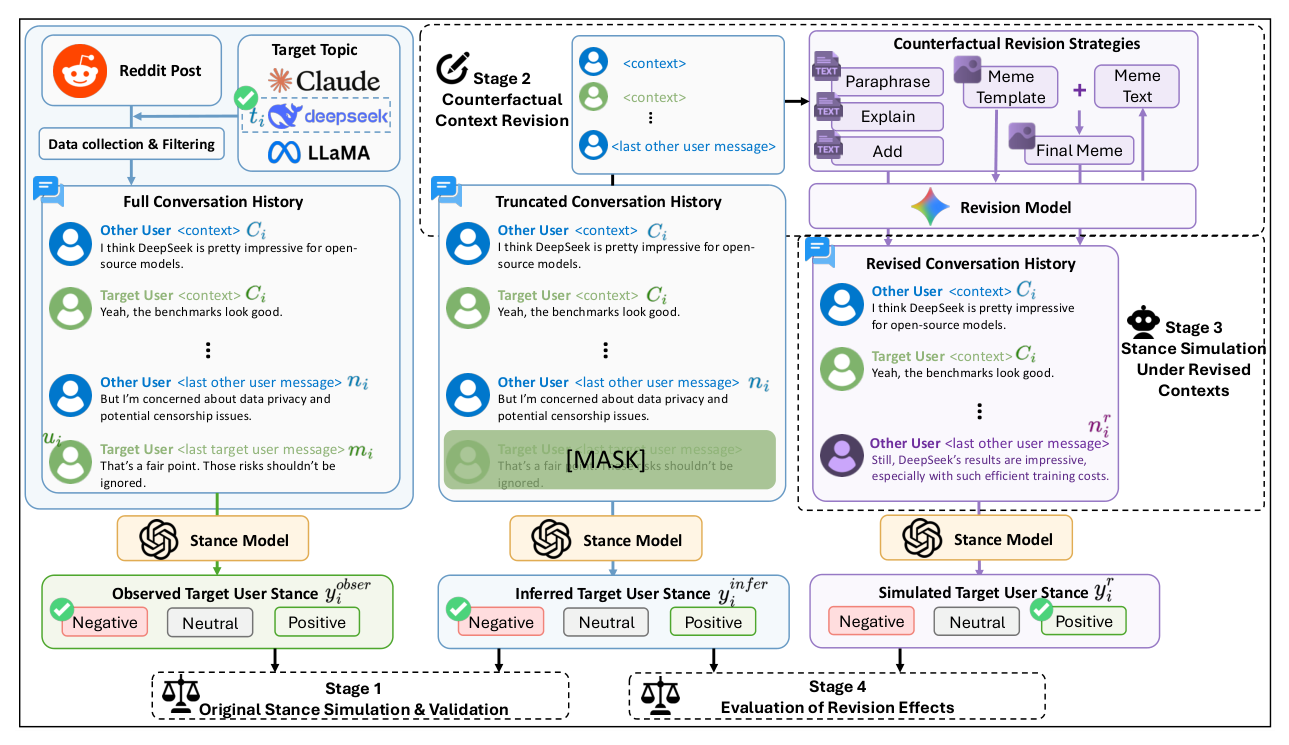
Figure 2 — 전체적인 counterfactual context revision 프레임워크와 실험 단계를 도식화한 핵심 다이어그램입니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 3개의 LLM 패밀리(DeepSeek, Claude, Llama)를 대상으로, Paraphrase, Explain, Add, Meme 등 다양한 전략을 사용하여 대화 맥락을 수정하고 Stance 변화를 관찰합니다. 실험 결과, Add 전략은 대화에 추가적인 논거를 제시하여 중립적 성향의 의견을 지지 방향으로 긍정적으로 이동시키는 효과가 탁월하며, Meme 전략은 시각적 맥락을 통해 더 강력하고 극적인 Stance 변화를 유도함을 확인했습니다. [Table 1]에서 볼 수 있듯이, 수정 전 원본 대화에 대한 기본 시뮬레이션 정확도는 77.64%의 Accuracy와 78.10%의 Macro F1을 기록하며 안정적인 베이스라인을 제공했습니다. 또한, [Table 2]에 따르면 Meme 전략은 평균 +49.3%의 Directional Stance Shift를 보여주며, 단순 텍스트 수정을 넘어선 멀티모달 정보의 추가적인 영향력을 증명하였습니다.
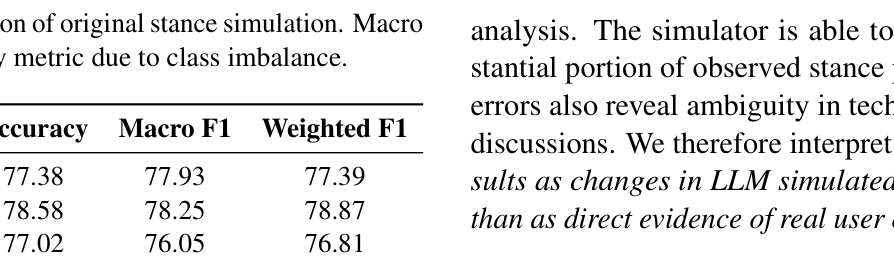
Table 1 — LLM 기반 시뮬레이션의 기준(Baseline) 성능을 보여주는 핵심 지표입니다.

Table 2 — 각 수정 전략(Paraphrase, Explain, Add, Meme)에 따른 Stance 변화 폭을 보여주는 핵심 결과 데이터입니다.
4. Conclusion & Impact (결론 및 시사점)
LLM 기반의 Stance 시뮬레이션은 수정된 대화 맥락에 매우 민감하게 반응하며, 특히 멀티모달 콘텐츠인 Meme이 강력한 설득력을 발휘함을 입증하였습니다. 이 연구는 사회과학 분야에서 LLM을 대규모 사용자 샘플링 도구로 사용할 때 고려해야 할 '맥락 민감도'라는 중요한 리스크를 제시합니다. 향후 연구자들은 모델의 의견 시뮬레이션 결과를 해석할 때, 그것이 실제 사용자의 견해인지 아니면 대화 프레임 구조에 의해 유도된 결과인지 엄격히 구분하여 분석해야 한다는 중요한 학술적 통찰을 제공합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] Where, What, Why, and Importance: Structured Defect Grounding for Text-to-Image Feedback
- [논문리뷰] WeaveBench: A Long-Horizon, Real-World Benchmark for Computer-Use Agents with Hybrid Interfaces
- [논문리뷰] WEAVER, Better, Faster, Longer: An Effective World Model for Robotic Manipulation
- [논문리뷰] Visual Para-Thinker++: A Single-Policy Multi-Agent Framework for Visual Reasoning
Review 의 다른글
- 이전글 [논문리뷰] Rethinking Continual Experience Internalization for Self-Evolving LLM Agents
- 현재글 : [논문리뷰] Revising Context, Shifting Simulated Stance: Auditing LLM-Based Stance Simulation in Online Discussions
- 다음글 [논문리뷰] RobotValues: Evaluating Household Robots When Human Values Conflict
댓글