[논문리뷰] Rethinking Continual Experience Internalization for Self-Evolving LLM Agents
링크: 논문 PDF로 바로 열기
메타데이터
저자: Jingwen Chen, Wenkai Yang, Shengda Fan, Wenbo Nie, Chenxing Sun, Shaodong Zheng, Yangen Hu, Lu Pan, Ke Zeng, Yankai Lin
1. Key Terms & Definitions (핵심 용어 및 정의)
- Experience Internalization: LLM이 과거 상호작용을 통해 얻은 Contextual Experience를 모델의 Parametric Capability로 변환하여 재사용 가능한 형태로 내재화하는 프로세스입니다.
- Experience Granularity: 경험을 저장하는 수준으로, 개별 Trajectory의 세부 정보를 포함하는 Instance-level과 재사용 가능한 전략 및 원칙을 추상화한 Principle-level로 구분됩니다.
- Experience Injection Pattern: 학습 시 경험을 모델에 주입하는 방식이며, 전체 Trajectory에 고정된 Context를 제공하는 Global Injection과 결정 상태에 따라 경험을 선택적으로 주입하는 Step-wise Injection이 있습니다.
- Internalization Regime: 경험을 모델에 학습시키는 분배 방식으로, 학생 모델의 Trajectory를 사용하는 On-policy 방식과 교사 모델의 성공적인 Trajectory를 활용하는 Off-policy 방식으로 나뉩니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM Agent의 Continual Learning을 위한 Experience Internalization 과정에서 나타나는 Capability Collapse 문제를 해결하고자 합니다. 기존 연구들은 단일 반복(Single-iteration) 학습에서는 우수한 성능을 보이나, 반복적인 Self-evolution 과정에서는 성능이 지속적으로 향상되지 않고 오히려 퇴보하는 현상이 발생합니다 [Figure 1]. 이러한 불안정성은 경험의 표현, 주입 방식, 그리고 학습 분배 체계 간의 부조화에서 기인함을 발견하였습니다. 따라서 본 연구는 다중 반복(Multi-iteration) 환경에서도 성능 하락 없이 지속 가능한 학습이 가능하도록 만드는 안정적인 메커니즘을 정의합니다.
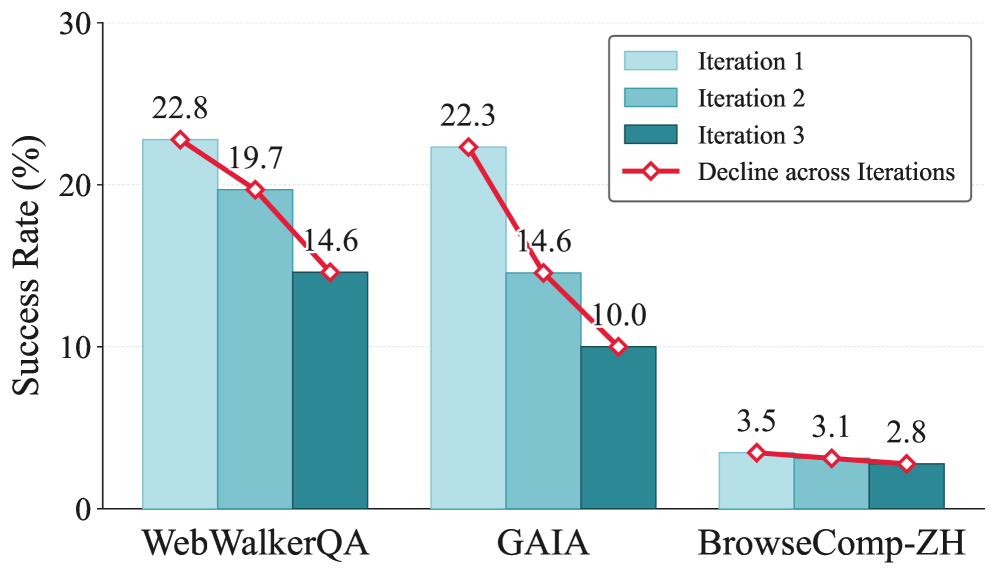
Figure 1 — 반복적 학습 시 성능 하락
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 지속 가능한 경험 내재화를 위해 Experience Granularity, Experience Injection Pattern, Internalization Regime의 세 가지 차원을 재설계하였습니다. 먼저, Principle-level experience는 불필요한 노이즈를 제거하여 더 견고한 학습 신호를 제공하며 [Figure 2], Step-wise injection은 실시간으로 결정 상태에 적합한 경험을 선택함으로써 모델의 추론 성능을 개선합니다 [Figure 3]. 마지막으로, Off-policy context-distillation을 도입하여 모델이 성공적인 교사(Teacher) Trajectory로부터 학습하도록 함으로써 데이터의 품질을 최적화하고 학습 효율성을 높였습니다.
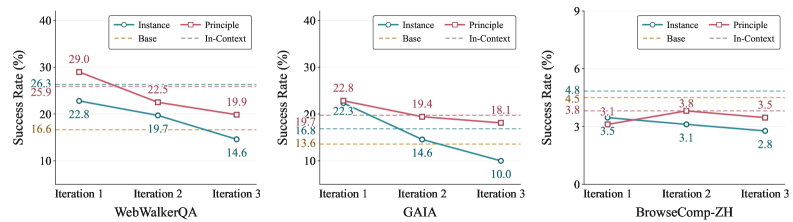
Figure 2 — 경험 세분화 수준의 영향
실험 결과, 제안된 통합 프레임워크는 WebWalkerQA, GAIA, BrowseComp-ZH 등 주요 벤치마크에서 반복적인 학습을 거쳐도 안정적인 성능 향상을 유지하였습니다 [Figure 6]. 특히, Step-wise injection을 적용한 경우 Premature-answer rate를 0%로 줄여 불필요한 조기 종료를 방지하고, Long-horizon 도구 사용 작업에서 뛰어난 성능 우위를 확보하였습니다 [Table 2]. 이는 제안된 기법이 단순한 일회성 성능 개선을 넘어, 모델과 경험 풀(Experience pool)이 상호 강화되는 지속 가능한 Self-evolution을 구현함을 입증합니다.
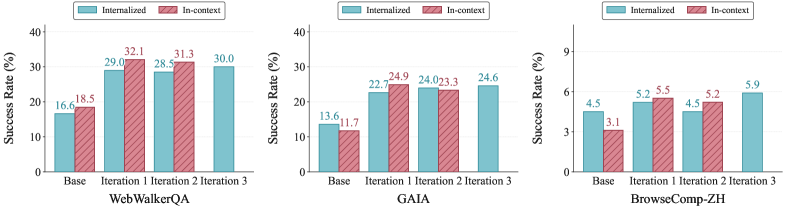
Figure 6 — 최종 제안 모델의 성능 향상
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Experience Internalization의 성공을 위한 세 가지 핵심 설계 원칙을 제시하며, 이를 통해 반복적인 Self-evolution 과정에서의 성능 퇴보 문제를 근본적으로 해결하였습니다. 제시된 기법들은 LLM Agent가 경험을 파라미터 내로 성공적으로 통합하고, 매 세대마다 점진적으로 더 강력한 추론 능력을 확보할 수 있도록 돕습니다. 본 연구는 학계 및 산업계에서 자율적이고 지속적으로 진화하는 Agent 시스템을 구축하기 위한 실질적이고 견고한 엔지니어링 가이드를 제공합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] XSkill: Continual Learning from Experience and Skills in Multimodal Agents
- [논문리뷰] Distilling Feedback into Memory-as-a-Tool
- [논문리뷰] EvoArena: Tracking Memory Evolution for Robust LLM Agents in Dynamic Environments
- [논문리뷰] DAR: Deontic Reasoning with Agentic Harnesses
- [논문리뷰] Language Models Need Sleep: Learning to Self-Modify and Consolidate Memories
Review 의 다른글
- 이전글 [논문리뷰] Reinforcement Learning Elicits Contextual Learning of Unseen Language Translation
- 현재글 : [논문리뷰] Rethinking Continual Experience Internalization for Self-Evolving LLM Agents
- 다음글 [논문리뷰] Revising Context, Shifting Simulated Stance: Auditing LLM-Based Stance Simulation in Online Discussions
댓글