[논문리뷰] TIDE: Proactive Multi-Problem Discovery via Template-Guided Iteration
링크: 논문 PDF로 바로 열기
메타데이터
저자: Soyeong Jeong, Jinheon Baek, Minki Kang, Sung Ju Hwang
1. Key Terms & Definitions (핵심 용어 및 정의)
- TIDE (Template-guided Iterative Discovery and rEsolution): 문맥(Context) 내에 숨겨진 다수의 문제를 식별하고, 근거를 마련하며, 해결책을 제안하는 능동적 에이전트 프레임워크입니다.
- Thought Templates: 과거에 해결된 사례로부터 추출한 재사용 가능한 발견 스키마로, 특정 문제 클래스를 추론하기 위한 증거 흐름과 구조적 패턴을 정의합니다.
- Iterative Discovery: 단일 패스 예측의 한계를 극복하기 위해, 에이전트가 이전 단계의 발견 상태를 조건부로 하여 여러 라운드에 걸쳐 새로운 후보를 점진적으로 탐색하는 매커니즘입니다.
- Coverage & F1: 다수의 숨겨진 문제를 얼마나 포괄적으로 찾아내는지(Coverage)와, 각 문제에 대한 식별 및 해결의 정밀도를 조화 평균(F1)으로 측정하는 본 논문의 핵심 평가 지표입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 LLM 에이전트가 사용자 요청에만 의존하는 수동적(Reactive) 모델이라는 점을 문제로 정의합니다. 실제 환경에서는 사용자가 미처 인지하지 못한 다수의 잠재적 문제가 존재함에도 불구하고, 기존 방식은 가장 눈에 띄는 문제 하나에만 집중하거나 일반적인 추론에 그치는 경향이 있습니다. 따라서 저자들은 명시적 요청 없이도 문맥 전반에서 복수의 숨겨진 문제를 능동적으로 발견하고 해결하는 새로운 과제를 제시합니다 [Figure 1].
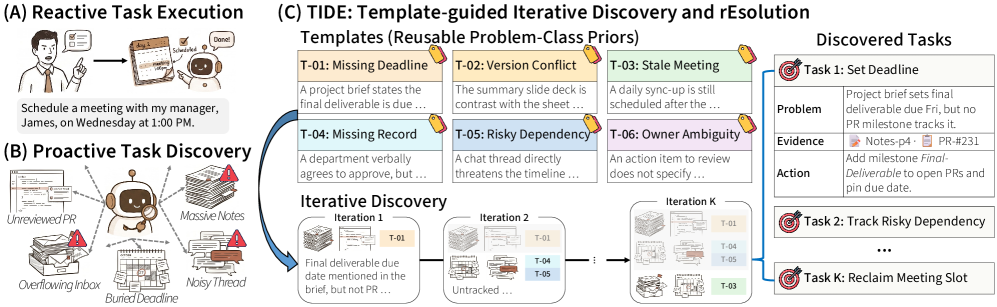
Figure 1 — TIDE 프레임워크 개념도
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 TIDE를 통해 반복적 발견(Iterative Discovery)과 사고 템플릿(Thought Templates)을 결합하여 이 문제를 해결합니다. Iterative Discovery는 매 라운드마다 이미 발견된 문제를 상태로 유지하며 새로운 후보를 탐색하여 전체적인 발견 범위를 확장합니다 [Figure 1]. 동시에 Thought Templates를 통해 각 문제의 증거 패턴을 명확히 함으로써, 에이전트가 모호한 추측 대신 특정 문제 클래스에 기반한 정교한 계획을 수립하도록 합니다. 실험 결과, TIDE는 Personal Workspace 및 Software Repository 설정에서 기존의 Single-Agent 및 Multi-Agent baseline 대비 전반적인 Coverage와 F1 지표에서 우수한 성능을 입증했습니다 [Table 1]. 특히, GPT와 Gemini 등 다양한 백본 모델에서도 일관된 성능 향상을 보였으며, LLM-call budget이 증가함에 따라 TIDE가 Multi-Agent baseline보다 훨씬 가파르게 성능이 스케일링됨을 확인했습니다 [Figure 4].
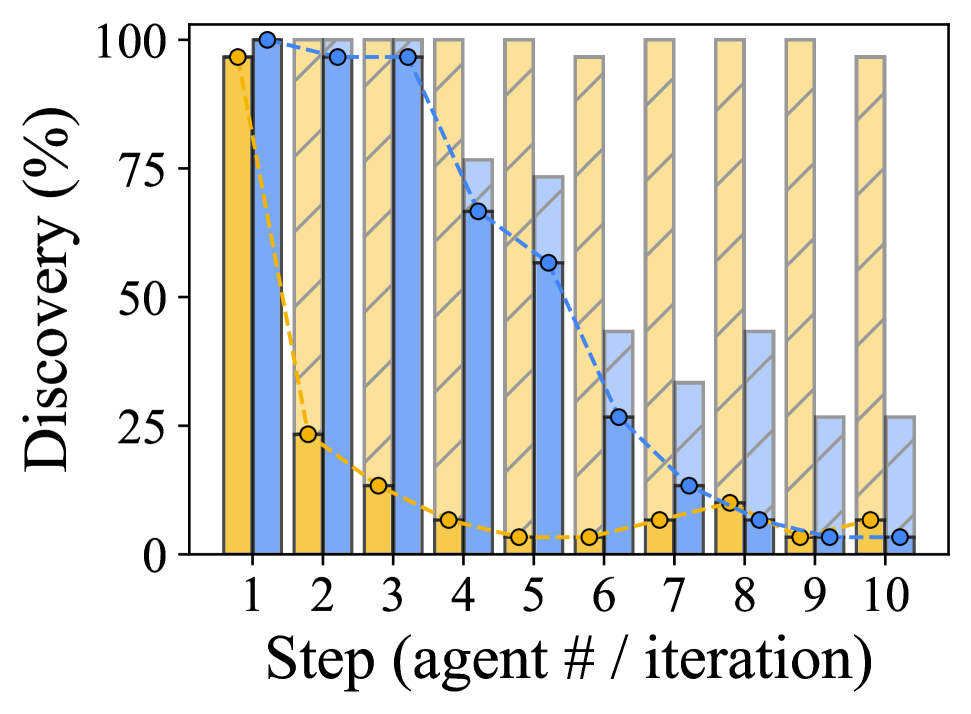
Figure 4 — LLM 호출 예산에 따른 F1 성능 비교
4. Conclusion & Impact (결론 및 시사점)
본 연구는 능동적 도움을 단일 요청에 대한 반응이 아닌, 문맥 전반에 걸친 다단계 발견 과정으로 재정의하였습니다. TIDE의 반복적 탐색과 템플릿 기반의 접근 방식은 복잡한 디지털 환경에서 인간이 인지하지 못한 잠재적 문제를 해결하는 새로운 패러다임을 제시합니다. 이 연구는 향후 에이전트 시스템이 단순히 주어진 명령을 수행하는 수준을 넘어, 잠재적 리스크를 선제적으로 파악하고 해결하는 지능형 어시스턴트로 진화하는 데 중요한 기반을 마련하였습니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Evoflux: Inference-Time Evolution of Executable Tool Workflows for Compact Agents
- [논문리뷰] EvoArena: Tracking Memory Evolution for Robust LLM Agents in Dynamic Environments
- [논문리뷰] Role-Agent: Bootstrapping LLM Agents via Dual-Role Evolution
- [논문리뷰] Retrospective Harness Optimization: Improving LLM Agents via Self-Preference over Trajectory Rollouts
- [논문리뷰] LatentSkill: From In-Context Textual Skills to In-Weight Latent Skills for LLM Agents
Review 의 다른글
- 이전글 [논문리뷰] SePO: Self-Evolving Prompt Agent for System Prompt Optimization
- 현재글 : [논문리뷰] TIDE: Proactive Multi-Problem Discovery via Template-Guided Iteration
- 다음글 [논문리뷰] The Shadow Price of Reasoning: Economic Perspective on Optimal Budget Allocation for LLMs
댓글