[논문리뷰] The Shadow Price of Reasoning: Economic Perspective on Optimal Budget Allocation for LLMs
링크: 논문 PDF로 바로 열기
메타데이터
저자: Xu Wan, Speed Zhu, Jianwei Cai, Guang Chen, XiMing Huang, Wiggin Zhou, Mingyang Sun
1. Key Terms & Definitions (핵심 용어 및 정의)
- Shadow Price: 시스템의 제약 조건(여기서는 고정된 토큰 예산)을 한 단위 완화했을 때 기대할 수 있는 목적 함수(총 추론 효용)의 증가분으로, 자원 최적 배분의 기준이 되는 핵심 지표입니다.
- Shifted-Surge Function: LLM의 추론 효용(Utility)을 모델링하기 위해 제안된 함수로, 임계값(
τ) 이전의 Strict 단계, 급격한 성능 향상이 일어나는 Surge 단계, 그리고 보상이 줄어드는 Ample 단계의 구조를 표현합니다. - Rational Abandonment: 모든 쿼리에 예산을 분배하는 대신, 주어진 Shadow Price 하에서 기대 효용이 마이너스인 '경제적으로 파산한(insolvent)' 쿼리에는 토큰을 할당하지 않고 포기하는 최적화 전략입니다.
- CLEAR (Constrained Latent-utility Equilibrium Allocation for Reasoning): Shadow Price를 기반으로 시장 균형을 찾아 개별 쿼리에 최적의 토큰 수를 할당하는 플러그 앤 플레이 방식의 추론 제어 프레임워크입니다.
- Lambert W Function: 초월 방정식 형태의 최적화 조건을 Closed-form으로 풀기 위해 사용하는 특수 함수로, 본 논문에서 개별 쿼리의 최적 토큰 할당량을 계산하는 데 사용됩니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 고정된 컴퓨팅 자원 환경에서 LLM의 추론 성능을 극대화하기 위한 효율적인 예산 배분 문제를 해결합니다. 기존의 Uniform 정책은 모든 쿼리에 동일한 토큰 제한을 부여함으로써, 쉬운 문제에는 자원을 낭비하고 어려운 문제에는 성능 발휘에 필요한 충분한 자원을 제공하지 못하는 한계가 있습니다. 이러한 비효율은 추론 유틸리티가 단순한 선형 관계가 아닌 S자 형태의 곡선을 따른다는 점 [Figure 1]에서 기인합니다. 따라서 저자들은 제한된 총 토큰 예산 내에서 개별 쿼리의 효용을 극대화하는 전역 제약 최적화 문제(Global Constrained Optimization Problem)로 이 문제를 재정의합니다.
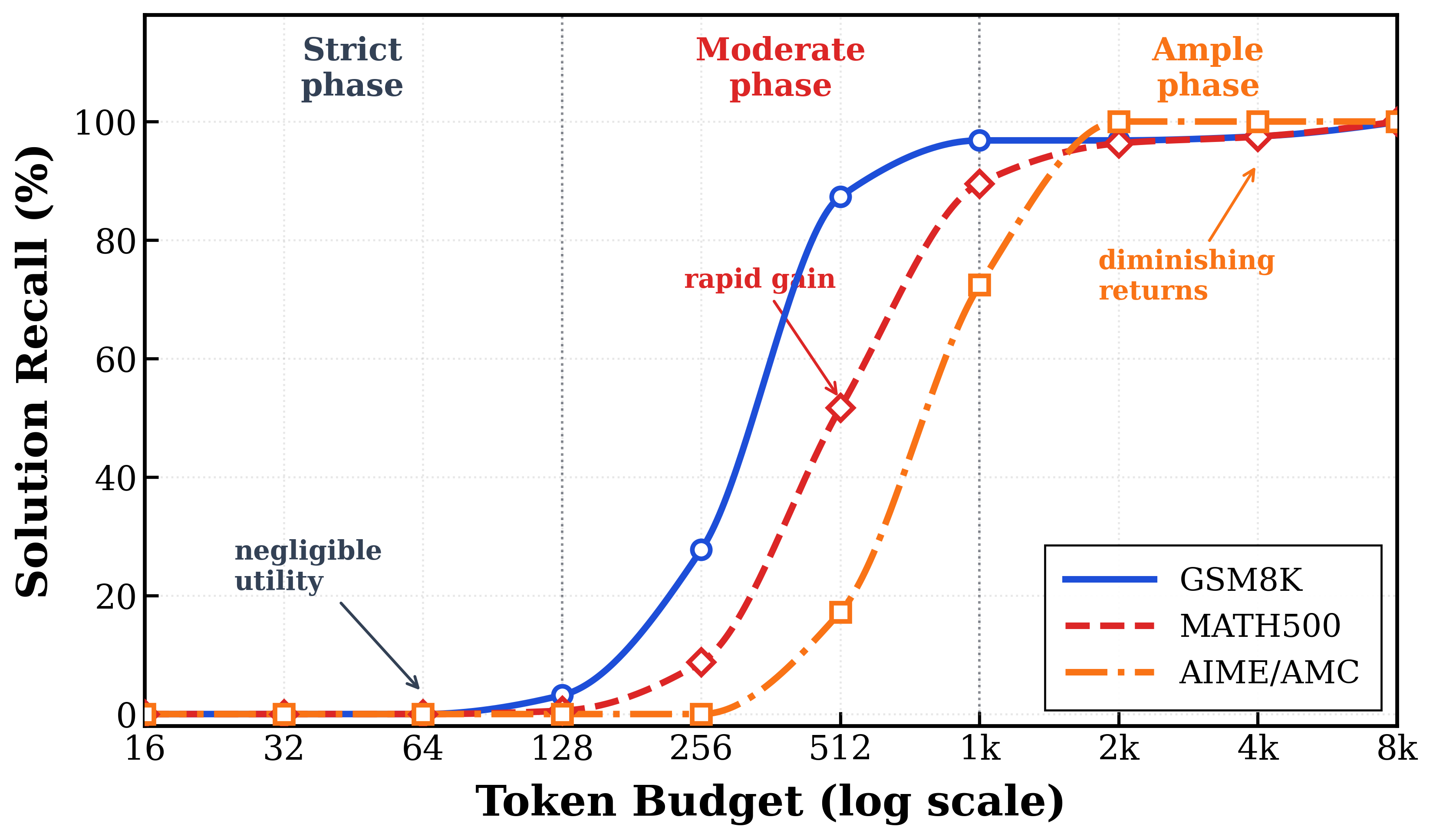
Figure 1 — 추론 효용의 S-곡선
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Lagrangian 기반의 경제적 원리를 도입하여, 한계 효용(Marginal Utility)이 전역 Shadow Price와 일치하는 지점에서 최적 배분이 발생함을 이론적으로 증명합니다. 제안된 CLEAR 방법론은 1) DeBERTa-v3 기반의 예측기를 통해 쿼리별 임계값(τ)을 추정하고, 2) Bisection 탐색을 통해 총 예산을 소진하는 시장 균형 가격(Shadow Price)을 발견하며, 3) Lambert W Function을 활용한 Closed-form 정책으로 쿼리별 토큰 할당량을 결정합니다 [Theorem 4.2].
실험 결과, CLEAR는 리소스가 제한된 환경에서 Uniform 배분 대비 압도적인 성능 우위를 보입니다. 정량적으로는 Balanced 스트림에서 +11.6, Mostly-Easy 스트림에서는 최대 +24.0의 Accuracy 향상을 달성했습니다 [Table 1]. 특히, 낮은 예산 제약 조건 하에서 Uniform 배분은 성능이 정체되는 반면, CLEAR는 Rational Abandonment를 통해 자원을 선택적으로 재분배함으로써 성능의 Pareto frontier를 획기적으로 개선합니다 [Figure 5]. 이러한 효과는 수학적 추론뿐만 아니라 코드 생성 태스크에서도 일관되게 나타납니다 [Table 2].
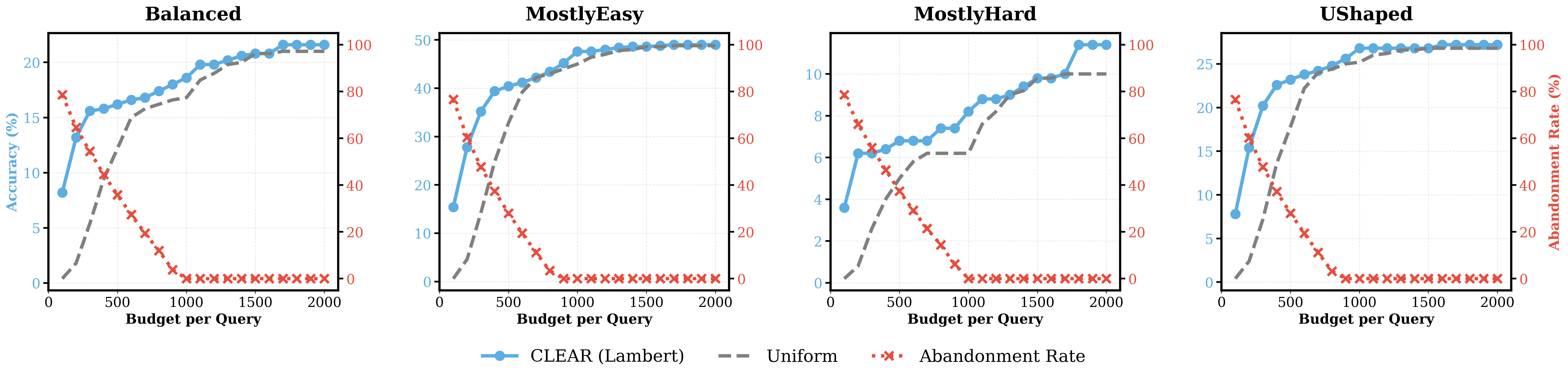
Figure 5 — 예산에 따른 상전이
4. Conclusion & Impact (결론 및 시사점)
본 연구는 LLM의 inference-time scaling을 경제학적 관점에서 정립하여, 추론 예산 배분을 위한 강력한 수학적 토대를 제공합니다. CLEAR 프레임워크는 기존 모델의 재학습 없이도 즉각적인 추론 효율성 개선이 가능하며, 리소스가 제약된 에지 디바이스나 대규모 클라우드 API 서비스 환경에서 실질적인 비용-성능 최적화 솔루션으로 활용될 수 있습니다. 본 연구의 시사점은 모델 지능의 천장을 높이는 것을 넘어, 주어진 제약 조건 하에서 시스템 전반의 효용을 극대화하는 '시스템 수준의 지능(System-level intelligence)' 설계의 중요성을 강조합니다.
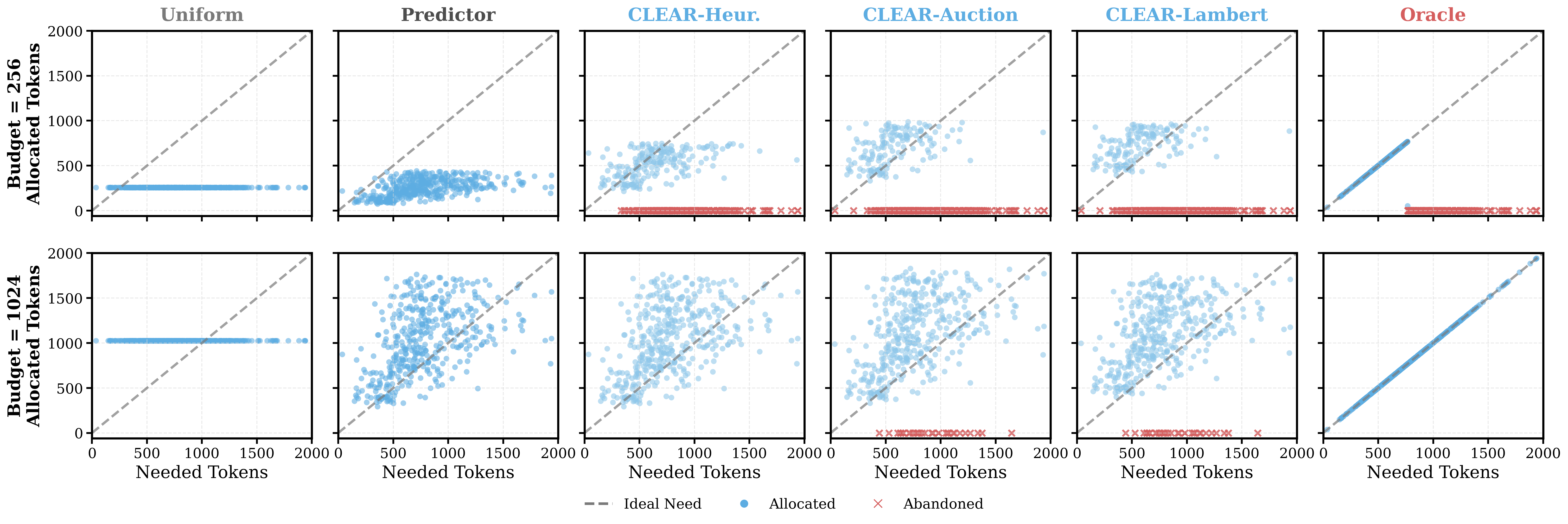
Figure 6 — 토큰 할당 시각화
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Critic-R: Improving Agentic Search using Instruction-tuned Retrievers with Natural Language Introspective Feedback
- [논문리뷰] Where Do Deep-Research Agents Go Wrong? Span-Level Error Localization in Agent Trajectories
- [논문리뷰] Long Live The Balance: Information Bottleneck Driven Tree-based Policy Optimization
- [논문리뷰] From Reasoning Chains to Verifiable Subproblems: Curriculum Reinforcement Learning Enables Credit Assignment for LLM Reasoning
- [논문리뷰] Nudging Beyond the Comfort Zone: Efficient Strategy-Guided Exploration for RLVR
Review 의 다른글
- 이전글 [논문리뷰] TIDE: Proactive Multi-Problem Discovery via Template-Guided Iteration
- 현재글 : [논문리뷰] The Shadow Price of Reasoning: Economic Perspective on Optimal Budget Allocation for LLMs
- 다음글 [논문리뷰] The Shape of Addition: Geometric Structures of Arithmetic in Large Language Models
댓글