[논문리뷰] SePO: Self-Evolving Prompt Agent for System Prompt Optimization
링크: 논문 PDF로 바로 열기
메타데이터
저자: Wangcheng Tao, Han Wu, Weng-Fai Wong
1. Key Terms & Definitions (핵심 용어 및 정의)
- SePO (Self-Evolving Prompt Optimization): Prompt Agent의 시스템 프롬프트를 최적화의 대상으로 포함하여, Task Agent와 Prompt Agent를 동시에 진화시키는 자가 참조(self-referential) 설계 기반의 프롬프트 최적화 프레임워크입니다.
- Prompt Agent: Task Agent의 시스템 프롬프트를 개선하기 위해 평가 피드백을 기반으로 수정된 프롬프트를 제안하는 에이전트입니다.
- Open-Ended Evolutionary Search: 후보 프롬프트들의 아카이브를 유지하며 더 우수한 자식 프롬프트를 탐색하고, 이전 프롬프트를 성장의 발판으로 삼는 진화적 최적화 방식입니다.
- Two-Stage Training Pipeline: Pre-training 단계에서 다양한 Task 풀을 통해 Prompt Agent의 최적화 능력을 배양하고, Fine-tuning 단계에서 타겟 Task에 적용하는 2단계 학습 체계입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 시스템 프롬프트 최적화 방식이 갖는 불완전한 최적화 루프 문제를 해결하고자 합니다. 기존 연구(Baseline)에서는 Task Agent의 프롬프트만 최적화 대상으로 간주할 뿐, 정작 이를 수행하는 Prompt Agent의 시스템 프롬프트는 사람이 직접 설계한(hand-engineered) 고정된 형태를 유지합니다 [Figure 1]. 이러한 방식은 Prompt Agent가 새로운 Task를 경험하며 학습하고 개선될 기회를 차단하며, 최적화 성능이 인간의 엔지니어링 수준에 갇히는 한계를 가집니다. 따라서 저자들은 Prompt Agent 스스로를 최적화 대상으로 포함하여 최적화 루프를 닫는 자가 참조 설계가 필수적이라고 판단하였습니다.
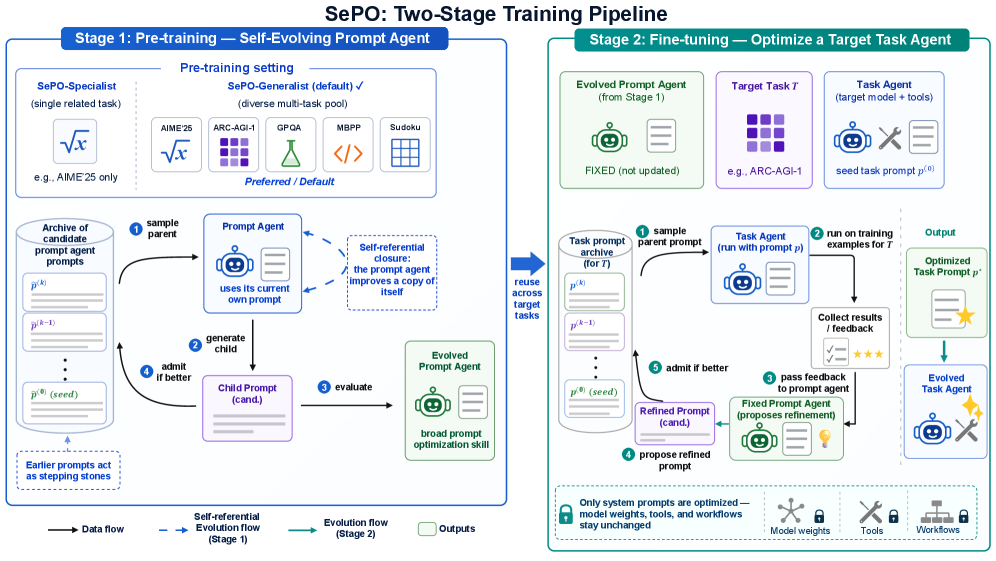
Figure 1 — 기존 방식과 SePO의 설계 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 SePO 프레임워크를 통해 Prompt Agent와 Task Agent의 시스템 프롬프트를 동일한 진화적 절차로 개선하는 방법을 제안합니다 [Figure 2]. SePO는 Pre-training 단계에서 다양한 Task 풀을 사용하여 Prompt Agent의 최적화 스킬을 고도화하고, Fine-tuning 단계에서 이 숙련된 에이전트를 특정 타겟 Task에 적용하여 효율적으로 프롬프트를 개선합니다. 실험 결과, SePO-Generalist는 Manual-CoT 대비 5개 벤치마크(AIME'25, ARC-AGI-1, GPQA, MBPP, Sudoku)에서 평균 정확도를 4.49 points 향상시키며 가장 우수한 성능을 입증하였습니다 [Table 1]. 또한, TextGrad 및 MetaSPO와 같은 기존 기법들이 Manual-CoT보다 낮은 성능을 보인 반면, SePO는 일관된 성능 우위를 점했습니다. 특히 Pre-training에 포함되지 않은 Task(예: Sudoku)에서도 범용적인 최적화 스킬을 바탕으로 성능 개선을 이루어내어 강력한 Cross-Task Generalization 능력을 확인하였습니다 [Figure 4].
Figure 2 — SePO의 2단계 학습 파이프라인
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Prompt Agent를 고정된 도구에서 지속적으로 학습하는 구성 요소로 전환함으로써 시스템 프롬프트 최적화의 새로운 패러다임을 제시했습니다. SePO의 자가 참조 설계와 2단계 학습 파이프라인은 최적화 비용을 효율화하면서도 다양한 Task에 걸친 일반화 성능을 극대화하였습니다. 이러한 방법론은 향후 시스템 프롬프트를 넘어 에이전트의 도구 사용, 워크플로우, 구조적 설계까지 자가 개선 범위를 확장하는 데 중요한 기초가 될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Evoflux: Inference-Time Evolution of Executable Tool Workflows for Compact Agents
- [논문리뷰] When Gradients Collide: Failure Modes of Multi-Objective Prompt Optimization for LLM Judges
- [논문리뷰] Self-Improving Language Models with Bidirectional Evolutionary Search
- [논문리뷰] MemTrace: Tracing and Attributing Errors in Large Language Model Memory Systems
- [논문리뷰] Web2BigTable: A Bi-Level Multi-Agent LLM System for Internet-Scale Information Search and Extraction
Review 의 다른글
- 이전글 [논문리뷰] SEAOTTER: Sensor Embedded Autoencoding with One-Time Transcode for Efficient Reconstruction
- 현재글 : [논문리뷰] SePO: Self-Evolving Prompt Agent for System Prompt Optimization
- 다음글 [논문리뷰] TIDE: Proactive Multi-Problem Discovery via Template-Guided Iteration
댓글