[논문리뷰] SEAOTTER: Sensor Embedded Autoencoding with One-Time Transcode for Efficient Reconstruction
링크: 논문 PDF로 바로 열기
메타데이터
저자: Dan Jacobellis, Neeraja J. Yadwadkar
1. Key Terms & Definitions (핵심 용어 및 정의)
- SEAOTTER: Sensor Embedded Autoencoding with One-Time Transcode for Efficient Reconstruction의 약어로, 로봇 센서의 제한된 자원을 활용하면서도 클라우드 인프라와 호환되는 표준 JPEG 출력을 생성하는 효율적인 압축 프레임워크입니다.
- EE-AAE (Encoding-Efficient Asymmetric Autoencoder): 센서 측의 인코딩 비용을 최소화(10–100 MAC/pixel 수준)하고, 이를 복원하는 비용을 클라우드 측에서 부담하도록 설계된 비대칭 구조의 오토인코더입니다.
- JPEG Sandwich: 기존의 JPEG 인프라를 활용하기 위해 신경망 기반의 인코더와 디코더를 표준 JPEG 코덱 전후에 배치하여, 표준 JPEG 파일을 생성하면서도 작업 특화된 성능을 극대화하는 기법입니다.
- Transcoding: 센서로부터 전송된 압축된 latent 데이터를 표준 JPEG 이미지로 한 번 변환하여, 후속 단계에서 여러 소비자(consumer)가 표준 JPEG 규격으로 디코딩할 수 있게 만드는 과정입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
로봇 시스템은 저비용·저전력 센서로부터 방대한 시각 데이터를 수집하지만, 제한된 대역폭과 온디바이스(on-device) 컴퓨팅 자원으로 인해 고해상도 처리에 어려움을 겪고 있습니다. 기존의 AVIF 등 고효율 코덱은 인코딩 비용이 과도하게 높고, 최근의 비대칭 오토인코더들은 표준화된 인프라(JPEG 등)와 호환되지 않는 독자적인 포맷을 사용하여 범용성이 떨어지는 한계가 있습니다. 특히 로봇 운영 환경에서는 하나의 원본을 다수의 소비자(학습 루프, 웹 브라우저, 인식 모델 등)가 반복적으로 읽는 'encode-once, decode-many' 라이프사이클이 일반적이므로, 디코딩 효율성이 매우 중요합니다. 본 연구는 이러한 파편화된 압축 환경에서 센서의 자원 제약을 준수하면서도 범용 JPEG 인프라를 활용할 수 있는 새로운 통합 프레임워크를 제안합니다 [Figure 1].
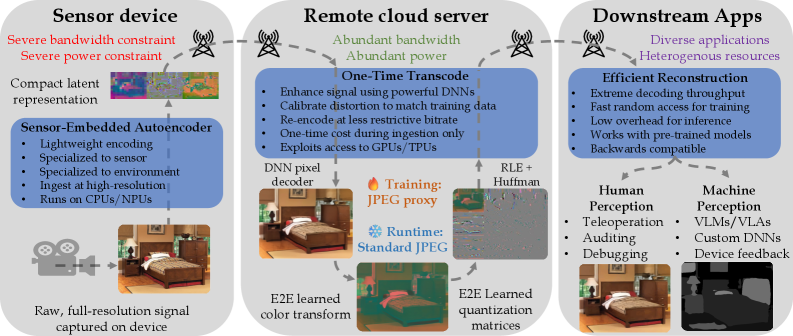
Figure 1 — SEAOTTER 전체 설계 및 워크플로우
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 FRAPPE 인코더를 기반으로 센서 측에서는 최소한의 연산만을 수행하고, 클라우드 측에서 수행되는 One-Time Transcode를 통해 데이터를 범용 JPEG 포맷으로 변환하는 SEAOTTER 프레임워크를 제안합니다 [Figure 1]. 제안하는 구조는 학습 가능한 색상 변환(color transform)과 8×8 DCT 기반의 양자화 매트릭스를 포함하는 'JPEG sandwich'를 통해 데이터의 압축률과 하위 인식 작업의 정확도를 동시에 최적화합니다. 특히, 고정된 인코더를 사용하면서 디코더와 JPEG 래퍼(wrapper)를 특정 작업에 맞게 파인튜닝함으로써 성능 향상을 도모합니다. 실험 결과, SEAOTTER-FT는 압축률 200:1 조건에서 AVIF 대비 인코딩은 7배, 디코딩은 3.5배 빠른 속도를 달성했습니다. 또한, ImageNet 상에서 Top-1 accuracy가 기존 대비 +8% 향상되는 등 뛰어난 성능 우위를 정량적으로 입증하였습니다 [Figure 2], [Table 1].
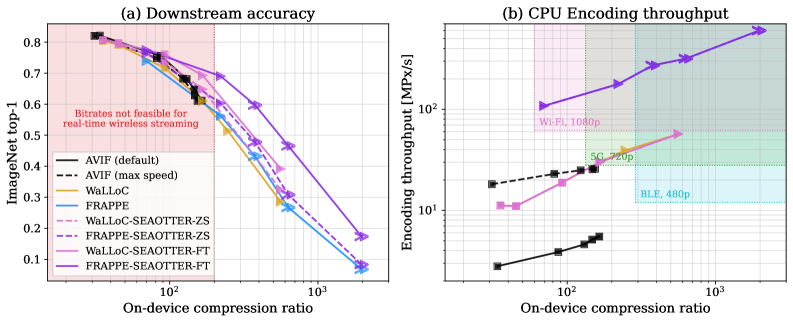
Figure 2 — 정확도, 처리량 및 압축률 비교
4. Conclusion & Impact (결론 및 시사점)
본 논문은 로봇 공학 및 클라우드 컴퓨팅 분야에서 센서의 하드웨어 제약과 클라우드의 인프라 호환성 문제를 동시에 해결하는 혁신적인 압축 프레임워크를 제시하였습니다. 제안하는 SEAOTTER는 고전적인 JPEG 인프라를 신경망 기반 오토인코더와 성공적으로 결합하여, 표준 준수와 높은 작업 정확도라는 두 마리 토끼를 잡았습니다. 본 연구는 향후 클라우드 로보틱스 서비스의 데이터 처리 효율성을 획기적으로 높이고, 실시간 비전 인식 시스템의 배포 문턱을 낮추는 데 기여할 것으로 기대됩니다.
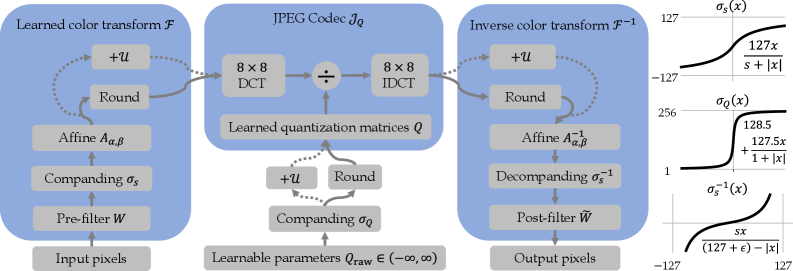
Figure 3 — 학습 가능한 JPEG 래퍼 구조
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] HYDRA-X: Native Unified Multimodal Models with Holistic Visual Tokenizers
- [논문리뷰] FORT-Searcher: Synthesizing Shortcut-Resistant Search Tasks for Training Deep Search Agents
- [논문리뷰] A Stationary (and Therefore Compatible) Representation is All You Need
- [논문리뷰] Semi-Supervised Noise Adaptation: Transferring Knowledge from Noise Domain
- [논문리뷰] MERIT: Learning Disentangled Music Representations for Audio Similarity
Review 의 다른글
- 이전글 [논문리뷰] RobotValues: Evaluating Household Robots When Human Values Conflict
- 현재글 : [논문리뷰] SEAOTTER: Sensor Embedded Autoencoding with One-Time Transcode for Efficient Reconstruction
- 다음글 [논문리뷰] SePO: Self-Evolving Prompt Agent for System Prompt Optimization
댓글