[논문리뷰] World-Language-Action Model for Unified World Modeling, Language Reasoning, and Action Synthesis
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yi Yang, Zhihong Liu, Siqi Kou, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- WLA (World-Language-Action Model): 텍스트 지시사항, 이미지, 로봇 상태를 입력받아 언어적 의도, 미래 시각 상태, 로봇 액션을 예측하는 통합된 embodied foundation model입니다.
- World Expert: AR(Autoregressive) backbone이 생성한 물리적 역학 정보를 바탕으로 미래의 시각적 상태(visual state)를 예측하는 전용 모듈입니다.
- Action Expert: WLA backbone에서 생성된 latent action을 입력받아 실제 로봇 실행 가능한 액션 chunk를 생성하는 모듈입니다.
- TTS (Test-Time Scaling): 추론 과정에서 여러 후보 액션을 생성하고, World Expert가 예측한 미래 상태를 가치 모델(value model)이 평가하여 최적의 액션을 선택하는 성능 확장 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 WAM (World-Action Model)과 VLA (Vision-Language-Action Model)가 가진 한계를 극복하기 위해 제안되었다. 기존 WAM은 비디오 생성 능력은 뛰어나지만 언어 기반의 추론 능력이 부족하며, VLA는 고수준의 언어적 계획 능력은 갖췄으나 물리적 역학(physical dynamics) 예측이 부족하여 정교한 제어가 어렵다는 문제가 있다 [Figure 1]. 저자들은 고수준의 언어적 의도와 저수준의 물리적 역학을 결합하는 것이 로봇의 장기 작업(long-horizon task) 수행에 핵심적이라고 판단하였다. 이를 위해 비디오 예측의 부담을 World Expert로 분산하고, AR Transformer 기반의 통합 아키텍처를 설계하였다.
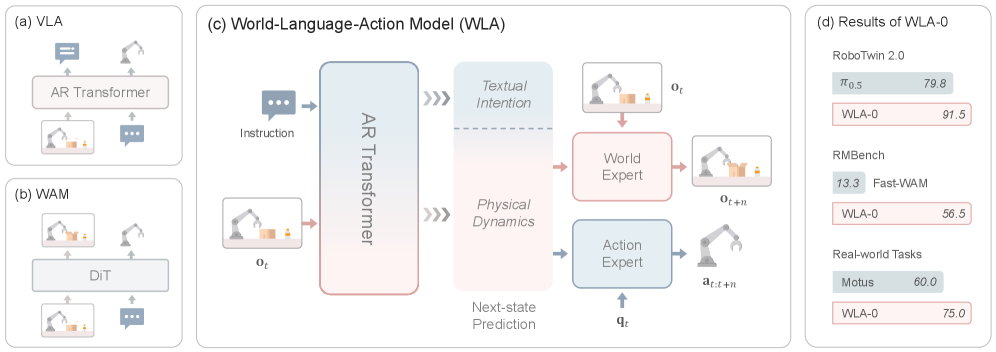
Figure 1 — WLA와 기존 모델 아키텍처 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 AR Transformer를 backbone으로 활용하여, 텍스트 지시사항을 통해 미래의 subtask를 예측하고, 이를 바탕으로 Action Expert가 물리적 액션을 생성하는 WLA 프레임워크를 제안한다 [Figure 2]. 핵심 방법론은 meta-query를 통해 World Expert가 물리적 역학을 학습하게 하고, 학습 시에는 이들이 협력하도록 하되, 추론 시에는 World Expert를 비활성화하여 실시간성(~40ms latency)을 확보하는 것이다.
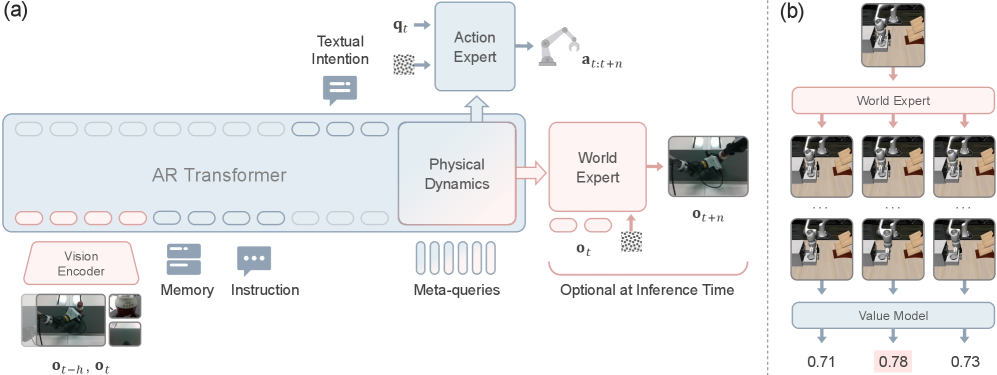
Figure 2 — WLA 프레임워크 및 TTS 모드
주요 실험 결과는 다음과 같다:
- RoboTwin 2.0 벤치마크에서 92.94%의 높은 성공률을 기록하며 SOTA 성능을 달성하였다 [Table 1].
- RMBench와 같은 메모리 의존적인 장기 작업에서 56.5%의 성공률을 기록하여, 이전 SOTA 모델 대비 성능을 거의 2배 향상시켰다 [Table 2].
- Test-Time Scaling 기법을 적용했을 때 LIBERO 벤치마크에서 성공률이 추가로 향상되었으며, 복잡한 실환경 작업에서도 baseline 대비 높은 효율성과 견고함을 입증하였다 [Figure 3].
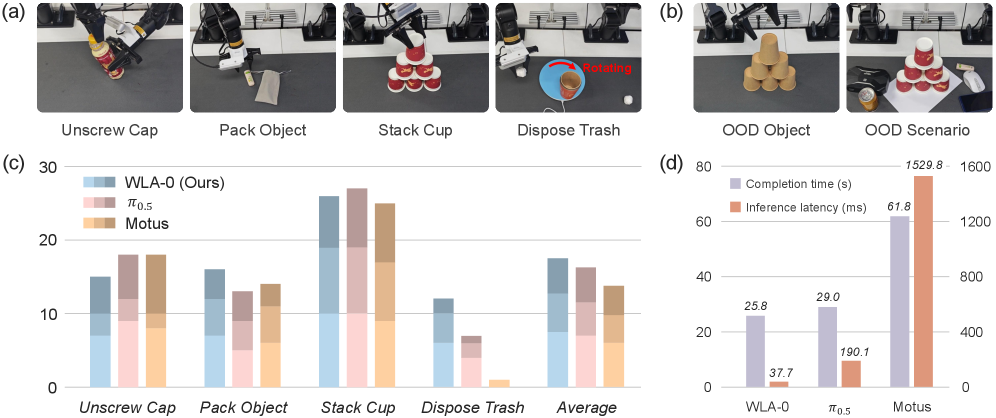
Figure 3 — 실환경 로봇 작업 성능 평가
4. Conclusion & Impact (결론 및 시사점)
본 논문은 세계 모델링, 언어적 추론, 액션 합성을 하나로 통합한 WLA 모델을 통해 복잡한 embodied 제어 문제를 성공적으로 해결하였다. WLA-0의 성공은 명시적인 embodied pretraining 없이도 고수준의 성능과 추론 효율성을 동시에 달성할 수 있음을 보여준다. 이 연구는 향후 로봇 학습 데이터를 확장하기 위한 cross-embodiment 비디오 학습 및 실시간 로봇 제어 분야에 중요한 기술적 이정표가 될 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] MaxProof: Scaling Mathematical Proof with Generative-Verifier RL and Population-Level Test-Time Scaling
- [논문리뷰] LabVLA: Grounding Vision-Language-Action Models in Scientific Laboratories
- [논문리뷰] WorldOlympiad: Can Your World Model Survive a Triathlon?
- [논문리뷰] Next Forcing: Causal World Modeling with Multi-Chunk Prediction
- [논문리뷰] WorldCraft: From Camera Navigation to Object Manipulation in Interactive Video World Models
Review 의 다른글
- 이전글 [논문리뷰] VideoKR: Towards Knowledge- and Reasoning-Intensive Video Understanding
- 현재글 : [논문리뷰] World-Language-Action Model for Unified World Modeling, Language Reasoning, and Action Synthesis
- 다음글 [논문리뷰] AnchorWorld: Embodied Egocentric World Simulation with View-based Evolution Customization
댓글