[논문리뷰] Watch, Remember, Reason: Human-View Video Understanding with MLLMs
링크: 논문 PDF로 바로 열기
저자: Jiahao Meng, Yue Tan, Qi Xu, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- MLLM (Multimodal Large Language Models): 비디오, 오디오, 텍스트 등 다중 모달 데이터를 이해하고 추론하는 거대 언어 모델 기반의 시스템을 지칭합니다.
- Watching (Functional Perspective): 비디오 스트림에서 태스크와 관련된 시각적 및 청각적 증거를 선택적으로 인식하고 구조화하는 초기 인지 단계를 의미합니다.
- Remembering (Functional Perspective): 비디오의 장기적인 컨텍스트를 유지하고, 관련 정보를 축적하며 중복을 제거하여 시공간적 이해를 보존하는 프로세스입니다.
- Reasoning (Functional Perspective): 감각적 증거와 메모리를 바탕으로 복합적인 관계를 추론하고, 최종적으로 설득력 있는 답변이나 행동을 도출하는 지적 단계를 말합니다.
- VTG (Video Temporal Grounding): 자연어 쿼리를 바탕으로 비디오 내의 특정 이벤트 발생 시간(timestamp)을 정밀하게 국소화(localization)하는 과업을 의미합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 짧은 클립 위주의 비디오 이해에서 벗어나 분 단위 이상의 장기적이고 다중 모달이 얽힌 복잡한 비디오 환경으로 변화하는 트렌드를 다룹니다. 기존 연구들은 태스크나 데이터셋별로 단편적으로 분절되어 있어, 모델이 정보를 어떻게 관찰하고(Watch), 저장하며(Remember), 추론하는지(Reason)에 대한 통합적 설계 체계가 부족합니다 [Figure 1]. 특히, 긴 비디오 내에 존재하는 정보의 희소성(sparsity)과 중복성(redundancy) 사이의 충돌은 모델의 연산 효율성과 정밀한 증거 확보를 어렵게 만드는 핵심 문제로 대두되고 있습니다. 저자들은 인간의 인지 과정을 모티베이션으로 삼아 비디오 이해를 고립된 과업이 아닌 'Watch-Remember-Reason'이라는 기능적 프로세스로 재정의할 필요성을 강조합니다.
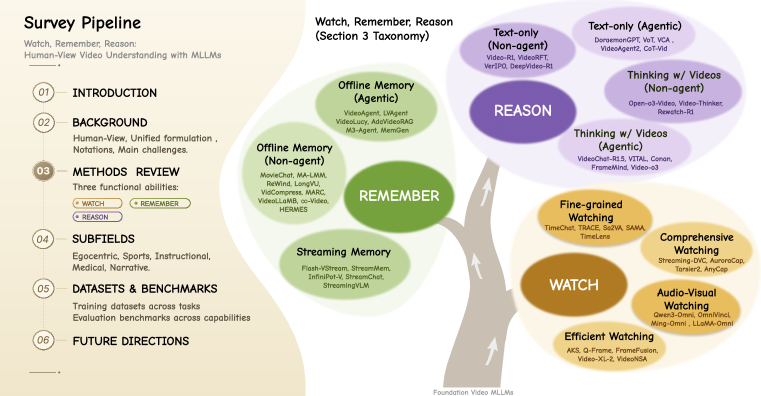
Figure 1 — 비디오 MLLM의 기능적 택소노미
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 비디오 이해 시스템을 위한 통합 프레임워크인 Watch–Remember–Reason 택소노미를 제안하며, 각 기능별로 최신 방법론들을 체계적으로 분류하였습니다 [Figure 1, Figure 2]. Watching 단계에서는 TimeChat [16]이나 LITA [36]와 같이 타임스탬프를 언어 토큰화하여 미세한 시간적 정밀도를 높이는 기법과, AKS [17]처럼 쿼리 관련성을 기반으로 프레임을 선별하는 효율적인 인지 기법을 분석합니다. Remembering 단계에서는 스트리밍 메모리 관리와 계층적 컨텍스트 보존 방식을 통해 장시간 비디오 처리의 한계를 극복하려는 시도들을 다룹니다. Reasoning 단계에서는 단순 텍스트 기반 추론을 넘어, Open-o3-Video [26]와 같이 시공간적 바운딩 박스를 증거로 활용하는 grounded reasoning 방식의 발전상을 조명합니다. 실험적으로는 GRPO(Group Relative Policy Optimization)를 활용한 강화학습 post-training이 모델의 추론 안정성과 증거 기반의 신뢰성(faithfulness)을 크게 향상시킴을 확인했습니다 [Table I]. 특히 태스크별 벤치마크 비교 결과, 기존의 end-to-end 모델 대비, 시공간적 Grounding과 메모리 기반 추론을 결합한 모델들이 long-video 시나리오에서 우수한 성능을 보임을 제시합니다.
4. Conclusion & Impact (결론 및 시사점)
본 논문은 MLLM 기반의 비디오 이해 분야를 'Watch-Remember-Reason'이라는 인간 중심의 기능적 관점에서 체계화하여 기술 발전을 위한 명확한 가이드라인을 제공합니다. 제안된 프레임워크는 연구자들이 모델의 아키텍처를 perception, memory, reasoning의 역할로 나누어 평가하고 설계할 수 있게 함으로써 학계와 산업계의 표준화된 접근을 가능하게 합니다. 향후 연구 방향으로 공간적 추론 강화, 시간 단위의 비디오 이해를 위한 구조적 메모리 설계, 그리고 강화학습을 통한 verifiable video reasoning의 확장을 제시합니다. 이 연구는 고도화된 실시간 egocentric 영상 분석, 의료용 영상 진단, 그리고 복합 내러티브 이해와 같은 실제 응용 분야에서 핵심적인 기술적 토대가 될 것으로 기대됩니다.
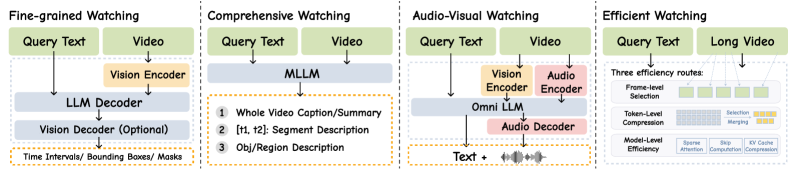
Figure 2 — Watching 기능의 세부 요소
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Video-Thinker: Sparking 'Thinking with Videos' via Reinforcement Learning
- [논문리뷰] Benchmarking Visual State Tracking in Multimodal Video Understanding
- [논문리뷰] Q-Zoom: Query-Aware Adaptive Perception for Efficient Multimodal Large Language Models
- [논문리뷰] Video-MME-v2: Towards the Next Stage in Benchmarks for Comprehensive Video Understanding
- [논문리뷰] Towards Universal Video MLLMs with Attribute-Structured and Quality-Verified Instructions
Review 의 다른글
- 이전글 [논문리뷰] UniSHARP: Universal Sharp Monocular View Synthesis
- 현재글 : [논문리뷰] Watch, Remember, Reason: Human-View Video Understanding with MLLMs
- 다음글 [논문리뷰] When Gradients Collide: Failure Modes of Multi-Objective Prompt Optimization for LLM Judges
댓글