[논문리뷰] Text-to-Image Models Need Less from Text Encoders Than You Think
링크: 논문 PDF로 바로 열기
메타데이터
저자: Nurit Spingarn, Noa Cohen, Tamar Rott Shaham, Tomer Michaeli et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Contextless Embedding: 전체 프롬프트의 맥락(Context)을 완전히 제거하고, 개별 단어의 의미와 위치 정보만을 보존하여 생성된 입력 임베딩을 의미합니다.
- BoPTW (Bag of Position-Tagged-Words): 본 논문에서 제안하는 방식으로, 각 단어의 의미와 함께 해당 단어가 프롬프트 내에서 차지하는 절대적 위치 정보를 결합한 형태의 표현입니다.
- DiT (Diffusion Transformer): 최신 Text-to-Image 모델의 기반이 되는 아키텍처로, 이전의 U-Net 기반 모델과 달리 복잡한 언어 구조를 모델 내부에서 자체적으로 해석하는 능력이 뛰어난 것이 특징입니다.
- Non-inferiority Rate: 제안된 방법론으로 생성된 이미지가 기존의 Full Embedding 기반 이미지와 비교했을 때, 성능이 낮지 않다고 평가받는 비율을 의미하며 모델의 효과성을 측정하는 주요 지표입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 최신 Text-to-Image(TTI) 모델들이 복잡한 Text Encoder에 크게 의존하는 현상을 분석하고, 과연 이러한 모델들이 실제로 풍부한 문맥 정보를 활용하는지 의문을 제기합니다. 기존 연구들은 대규모 Pretrained Language Models를 활용하여 구성성(Compositionality)과 속성 결합(Attribute binding) 능력을 강화해왔으나, 실제 이미지 모델이 이러한 정보를 효율적으로 활용하는지에 대해서는 명확히 규명되지 않았습니다. 저자들은 기존의 복잡한 텍스트 임베딩을 제거하더라도 TTI 모델이 여전히 높은 품질의 이미지를 생성할 수 있음을 입증하고자 합니다 [Figure 1].

Figure 1 — 문맥 정보 없이도 유지되는 생성 품질
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 프롬프트에서 문맥 정보를 점진적으로 제거한 BoT, BoW, BoPTW라는 세 가지 유형의 contextless embedding을 구성하여 그 성능을 측정합니다 [Figure 2]. BoPTW는 단어의 의미와 프롬프트 내 절대적 위치 정보를 결합하여, 문맥 없는 표현임에도 불구하고 높은 수준의 속성 결합과 공간적 이해를 가능하게 합니다 [Figure 3]. 실험 결과, SD 3, FLUX.1 Schnell, FLUX.2와 같은 DiT 모델들은 BoPTW만으로도 Full Embedding 대비 65% 이상의 non-inferiority rate를 달성하며 대등한 성능을 보였습니다 [Figure 6]. 이는 최신 TTI 모델이 텍스트의 구조를 텍스트 인코더에 의존하기보다, 모델 내부적으로 직접 추론하고 있음을 시사합니다 [Figure 4]. 반면, 이전 세대의 U-Net 기반 모델들(예: SDXL, SD 2.1)은 이러한 contextless 환경에서 생성 능력을 거의 상실하여, 최근 아키텍처 변화가 모델의 linguistic decoding 역량을 크게 변화시켰음을 증명하였습니다.
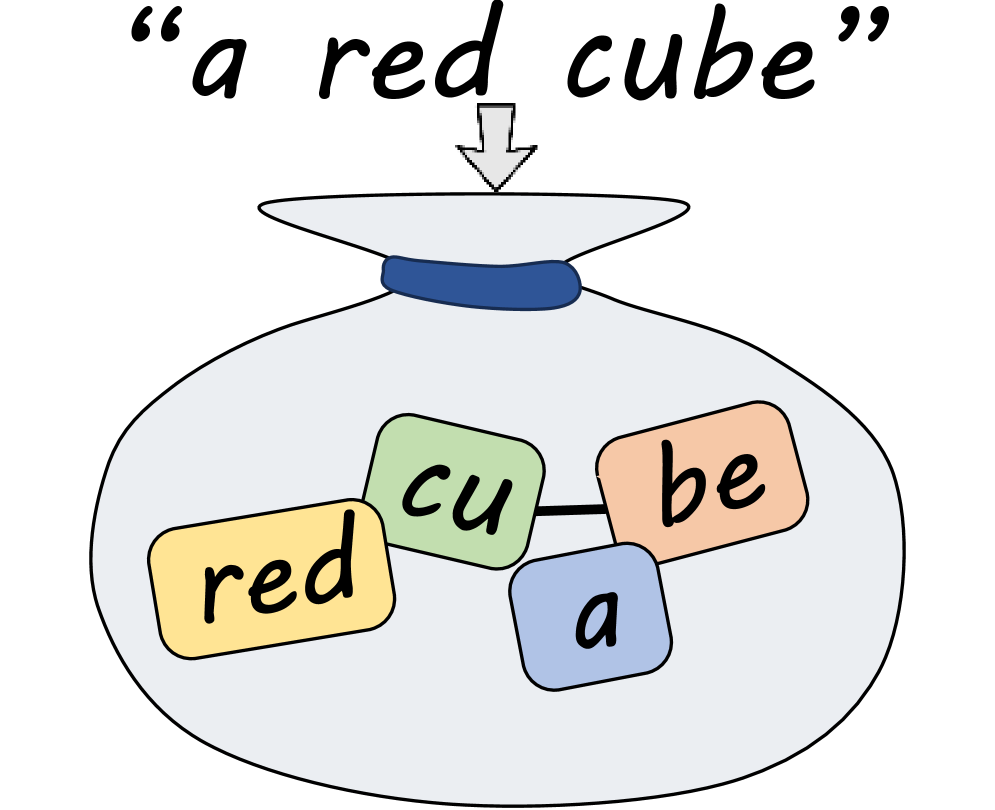
Figure 2 — 제안하는 3가지 임베딩 비교
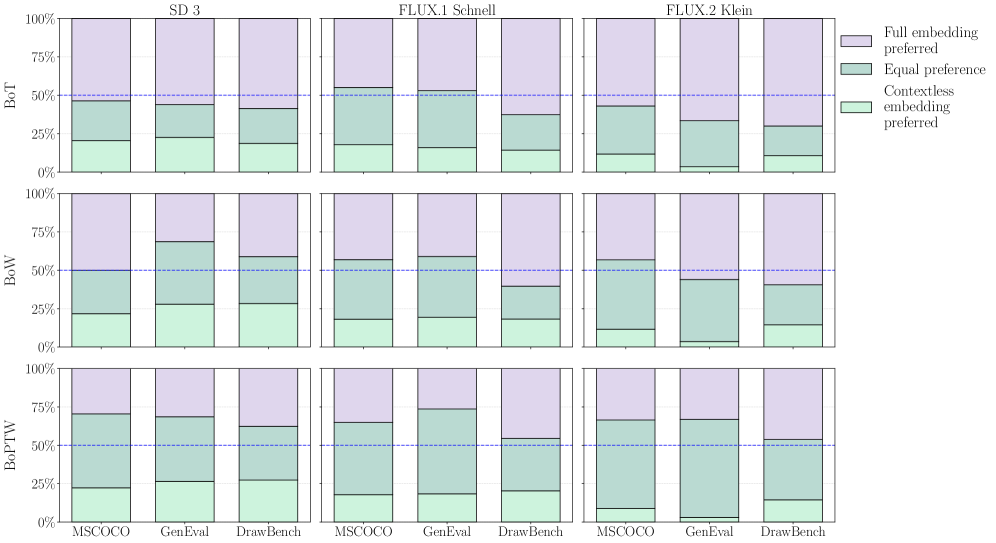
Figure 6 — 정량적 성능 비교 결과
4. Conclusion & Impact (결론 및 시사점)
본 논문은 TTI 모델이 생각보다 텍스트 인코더로부터 추출하는 정보가 적으며, 개별 단어와 위치 정보만으로도 복잡한 시각적 합성이 충분히 가능함을 밝혀냈습니다. 이러한 발견은 향후 대규모 텍스트 인코더에만 의존하는 아키텍처의 비효율성을 개선하고, 더욱 경량화되고 효율적인 인터페이스 개발의 기반이 될 것으로 예상됩니다. 결과적으로 본 연구는 텍스트 이해의 주체가 인코더가 아닌 이미지 생성 모델 자체로 이동하고 있다는 중요한 패러다임 변화를 학계에 제시합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Seedream 4.0: Toward Next-generation Multimodal Image Generation
- [논문리뷰] Where, What, Why, and Importance: Structured Defect Grounding for Text-to-Image Feedback
- [논문리뷰] SwiftVR: Real-Time One-Step Generative Video Restoration
- [논문리뷰] AHA-WAM:Asynchronous Horizon-Adaptive World-Action Modeling with Observation-Guided Context Routing
- [논문리뷰] StreamChar: Long-Horizon Streaming Character Audio-Video Generation with Decoupled Orchestration
Review 의 다른글
- 이전글 [논문리뷰] SwiftVR: Real-Time One-Step Generative Video Restoration
- 현재글 : [논문리뷰] Text-to-Image Models Need Less from Text Encoders Than You Think
- 다음글 [논문리뷰] Trajectory-Refined Distillation
댓글