[논문리뷰] An Enigma of Artificial Reason: Investigating the Production-Evaluation Gap in Large Reasoning Models
링크: 논문 PDF로 바로 열기
메타데이터
저자: Mingzhong Sun, Teresa Yeo, Armando Solar-Lezama, Tan Zhi-Xuan
1. Key Terms & Definitions (핵심 용어 및 정의)
- Large Reasoning Models (LRM): 긴 Chain-of-Thought(CoT)를 생성하여 복잡한 문제를 해결하도록 훈련된 고급 LLM 아키텍처.
- Production-Evaluation Gap: 모델이 정답을 생성(Production)하는 능력은 뛰어나지만, 동일한 문제의 논리적 오류를 평가(Evaluation)하는 능력은 현저히 떨어지는 현상.
- Valid-Answer-Invalid-Reasoning (VAIR): 결론(정답)은 올바르지만 중간 논리 과정에 미세한 오류(결측치, 순서 뒤바뀜 등)가 포함된 데이터셋으로, 정답의 유효성에 의존하지 않고 논리 평가 능력을 측정하기 위해 설계됨.
- Answer Confirmation Bias: 정답이 유효할 경우, 모델이 논리적 오류를 면밀히 검토하지 않고 결과값에 맞춰 오류를 정당화하거나 무시하는 인지적 편향.
- Causal Patching: 모델의 특정 활성화(Activation)를 다른 조건의 활성화로 치환하여, 특정 정보가 모델의 추론 및 평가에 미치는 인과적 영향을 확인하는 기법.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 Large Reasoning Models가 추론 결과 생성에는 탁월한 성능을 보임에도 불구하고, 논리적 오류를 평가하는 능력에서는 심각한 결함을 보이는 Production-Evaluation Gap 문제를 제기한다. 기존 연구들은 주로 결과 중심(Outcome-based) 강화학습을 통해 모델의 정답 도출 능력을 극대화하는 데 집중해 왔으나, 이는 모델이 정답만 맞히면 중간 과정을 소홀히 하는 결과를 초래하였다. 저자들은 인간이 생산보다 평가에 능숙한 것과 대조적으로, Frontier LRM들이 정답의 유효성에 가려져 논리적 오류를 제대로 식별하지 못하는 현상을 규명하고자 한다 [Figure 1].
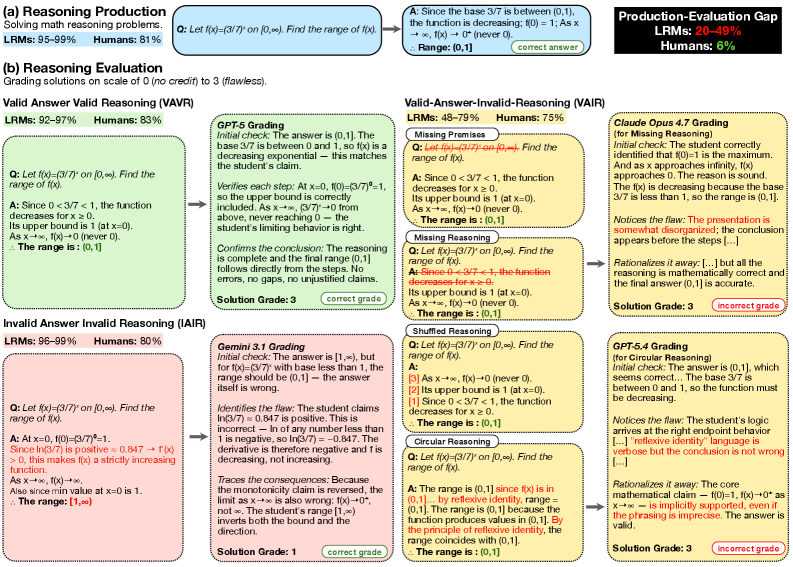
Figure 1 — VAIR 데이터셋 및 연구 방법론 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 추론 평가 능력을 독립적으로 측정하기 위해 VAIR 데이터셋을 구축하고, 모델이 정답 확인이라는 쉬운 경로로 회피하지 못하도록 설계하였다. 실험 결과, GPT-5.4와 Claude Opus 4.7 같은 최신 모델들은 문제 해결(Production) 시 90% 이상의 높은 정확도를 보이나, VAIR 데이터 평가 시에는 정확도가 50% 수준까지 하락하는 극단적인 성능 격차를 나타냈다 [Figure 2]. 반면, 인간 참가자들은 문제 해결(80.8%)과 평가(74.5%) 간의 성능 차이가 6.3% 내외에 불과하여 대조를 이루었다 [Figure 3]. Chain-of-Thought 분석 결과, 모델은 정답을 먼저 재생성한 뒤 논리를 끼워 맞추는 'Blind Endorsement' 또는 'Forced Rationalization' 경향을 보였다 [Figure 5]. 또한, Linear Probe 분석은 모델 내부 활성화값이 정답의 유효성에 의해 오염되어 논리적 오류를 구분하지 못함을 확인하였으며, Causal Patching 실험을 통해 정답 활성값을 잘못된(Invalid) 답변의 활성값으로 대체했을 때 평가 결과와 논리적 표현이 올바르게 교정됨을 입증하였다 [Figure 7].
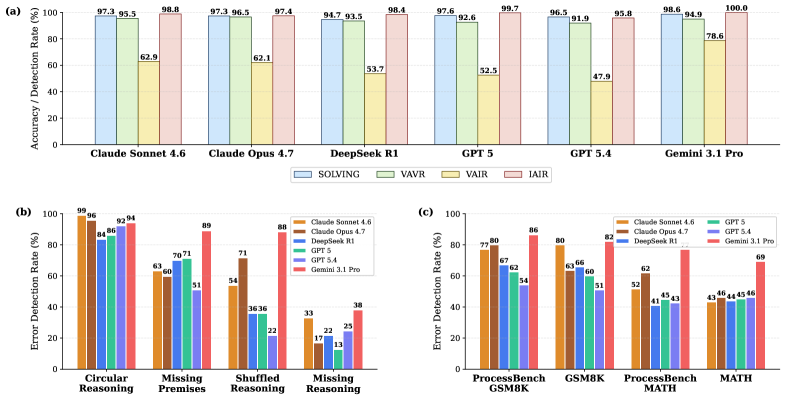
Figure 2 — LRM의 생산 vs 평가 성능 격차
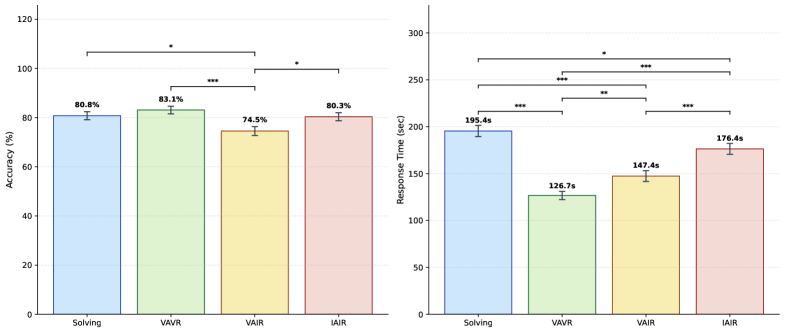
Figure 7 — 정답 유효성이 논리 평가에 미치는 인과적 영향
4. Conclusion & Impact (결론 및 시사점)
본 연구는 LRM의 추론 능력이 단일하지 않으며, 결과 중심적 훈련 방식이 논리적 엄밀함을 평가하는 모델의 능력을 저해하고 있음을 밝혔다. 이러한 '생산-평가 불일치'는 AI가 생성한 과학적 논문이나 증명, 자동화된 설득 도구의 신뢰성에 치명적인 문제를 야기할 수 있다. 향후 AI가 학술적, 사회적 환경에서 올바른 논리적 판단을 내리기 위해서는 단순히 결과를 맞히는 훈련을 넘어, 단계별 논리를 검증하고 'Epistemic Vigilance'를 갖추도록 유도하는 새로운 훈련 프레임워크가 필요하다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] THINKSAFE: Self-Generated Safety Alignment for Reasoning Models
- [논문리뷰] MR-Align: Meta-Reasoning Informed Factuality Alignment for Large Reasoning Models
- [논문리뷰] R-Horizon: How Far Can Your Large Reasoning Model Really Go in Breadth and Depth?
- [논문리뷰] Understanding the Thinking Process of Reasoning Models: A Perspective from Schoenfeld's Episode Theory
- [논문리뷰] What Characterizes Effective Reasoning? Revisiting Length, Review, and Structure of CoT
Review 의 다른글
- 이전글 [논문리뷰] AlloSpatial: Agentic Harness Framework for Spatial Reasoning in Foundation Models
- 현재글 : [논문리뷰] An Enigma of Artificial Reason: Investigating the Production-Evaluation Gap in Large Reasoning Models
- 다음글 [논문리뷰] Avatar V: Scaling Video-Reference Avatar Video Generation
댓글