[논문리뷰] Retrieve, Don't Retrain: Extending Vision Language Action Models to New Tasks at Test Time
링크: 논문 PDF로 바로 열기
메타데이터
저자: Jeongeun Park, Juhan Park, Taekyung Kim, Sungjoon Choi, Dongyoon Han, Sangdoo Yun
1. Key Terms & Definitions (핵심 용어 및 정의)
- VLA (Vision-Language-Action) Model: 시각적 입력과 자연어 지시사항을 처리하여 로봇의 제어 명령(Action)을 생성하는 모델입니다.
- WAM (World-Action Model): 시각적 생성(Video generation) 모델을 기반으로 하여 행동 예측과 미래 상태 예측을 통합적으로 수행하는 모델 아키텍처입니다.
- ReCAP (Retrieval-Conditioned Action Policy): 새로운 태스크를 학습 없이 Retrieval pool의 시연 데이터를 참조하여 실시간으로 적응하는 제안된 방법론입니다.
- Residual Action Parameterization: 전체 행동을 예측하는 대신, Retrieval된 동작과 실제 목표 사이의 차이값(Correction)만을 학습하여 효율적인 제어를 수행하는 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 VLA 정책을 새로운 태스크에 확장할 때 발생하는 데이터 수집 및 컴퓨팅 자원의 비효율성 문제를 해결하고자 합니다. 기존 연구(Baseline)는 새로운 태스크마다 고가의 Teleoperation 데이터를 수집하고, 모델 전체를 Fine-tuning하는 과정이 필수적이어서 확장성이 낮다는 한계가 있습니다. 특히 Cosmos Policy와 같은 고성능 모델은 태스크당 약 24 GPU-hours 이상의 컴퓨팅 자원을 소모합니다. 저자들은 이러한 비용을 제거하기 위해 태스크 업데이트 대신 Retrieval을 활용하는 새로운 패러다임을 제시합니다 [Figure 1].
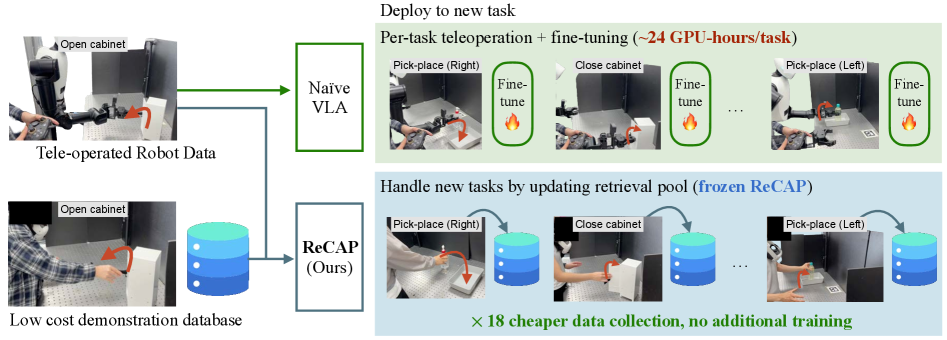
Figure 1 — ReCAP 모델 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 학습된 정책을 고정한 채, Retrieval된 시연 데이터를 Conditioning 정보로 입력받아 수행하는 ReCAP 프레임워크를 제안합니다. 제안 모델은 WAM의 미래 시각적 예측(Future-image objective) 능력을 활용하여 Retrieval된 동작의 일관성을 확보하고, Residual Action Parameterization을 통해 구현 시 발생할 수 있는 Embodiment gap을 보정합니다 [Figure 2]. PushT 실험 결과, 제안 방식은 unseen goal angles에서 34.9%의 성공률을 기록하여 Retrieval 없이 6.0%에 머무른 베이스라인을 압도했습니다. 또한 RoboTwin 2.0 환경에서 5개의 unseen 태스크에 대해 31.5%의 성공률을 달성하며 기존 Cross-embodiment 방식(26.0%) 대비 우수한 성능을 입증했습니다 [Table 1]. 이러한 수치는 정책을 별도로 Retraining 하지 않고 Retrieval pool만을 확장함으로써 달성되었다는 점에서 매우 높은 데이터 효율성을 보여줍니다 [Figure 7].
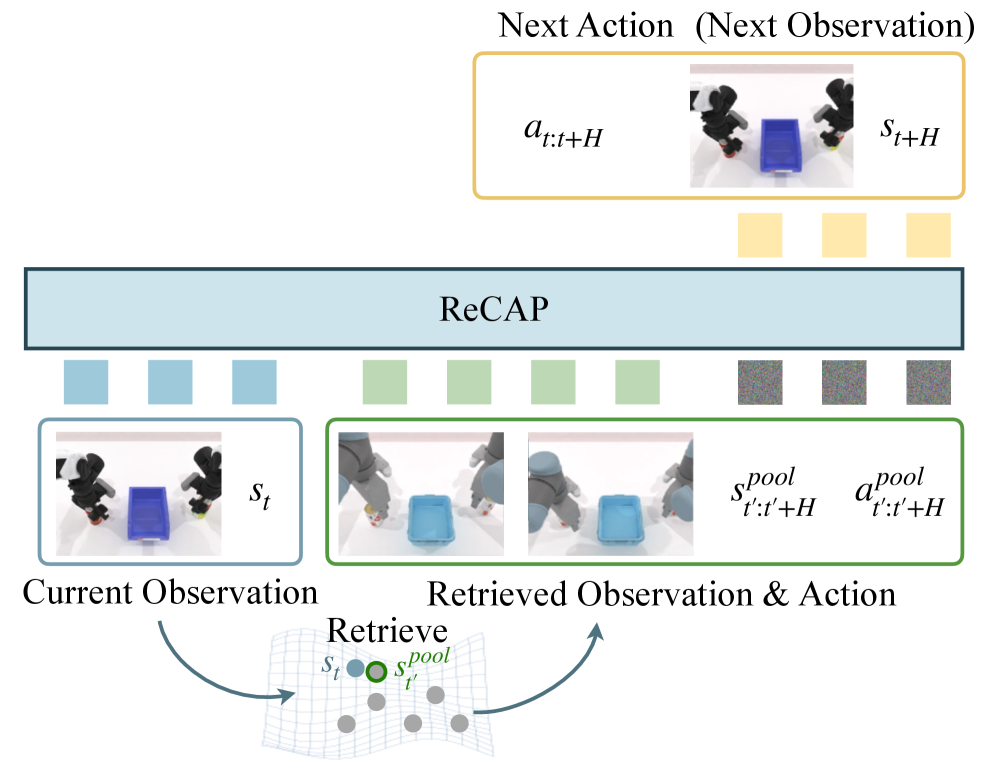
Figure 2 — ReCAP 프레임워크 구조

Table 1 — RoboTwin 성능 비교
4. Conclusion & Impact (결론 및 시사점)
본 연구는 로봇 정책의 일반화(Generalization)를 위해 고비용의 재학습 과정을 Retrieval 기반의 실시간 적응 패러다임으로 성공적으로 대체했습니다. 이 방식은 고가의 로봇 시연 데이터를 대신하여 저렴한 인간의 시연 영상(Pool-embodiment)을 활용할 수 있다는 점에서 산업계의 데이터 수집 비용을 획기적으로 낮출 수 있습니다. 본 연구의 결과는 향후 대규모 로봇 파운데이션 모델이 특정 태스크에 종속되지 않고 유연하게 새로운 동작을 습득하는 핵심적인 경로를 제시합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] Understanding the Behaviors of Environment-aware Information Retrieval
- [논문리뷰] Thinking with Visual Grounding
- [논문리뷰] Taylor-Calibrate: Principled Initialization for Hybrid Linear Attention Distillation
- [논문리뷰] Selective Synergistic Learning for Video Object-Centric Learning
Review 의 다른글
- 이전글 [논문리뷰] Qwen-RobotWorld Technical Report: Unifying Embodied World Modeling through Language-Conditioned Video Generation
- 현재글 : [논문리뷰] Retrieve, Don't Retrain: Extending Vision Language Action Models to New Tasks at Test Time
- 다음글 [논문리뷰] SP^3: Spherical Priors for Plug-and-Play Restoration
댓글