[논문리뷰] Qwen-RobotWorld Technical Report: Unifying Embodied World Modeling through Language-Conditioned Video Generation
링크: 논문 PDF로 바로 열기
저자: Jie Zhang, Xiaoyue Chen, Anzhe Chen, et al.
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- QWEN-ROBOTWORLD: 다양한 로봇 플랫폼과 시나리오를 통합하여 physically grounded 미래 시각적 궤적을 예측하는 language-conditioned 비디오 월드 모델입니다.
- Double-Stream MMDiT: Frozen Qwen2.5-VL 기반의 understanding stream과 비디오 VAE 잠재 공간을 다루는 generation stream으로 구성된 60-layer의 핵심 아키텍처입니다.
- EWK (Embodied World Knowledge): 20개 이상의 로봇 embodiment와 500개 이상의 행동 카테고리를 포함한 8.6M 규모의 고품질 비디오-텍스트 데이터셋입니다.
- Action-Language Mapping: 이질적인 로봇 행동 데이터(joint angles, waypoints 등)를 범용적인 자연어 인터페이스로 표준화하여 cross-scenario 학습을 가능하게 하는 프레임워크입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 연구는 로봇 공학에서 파편화된 행동 표현과 도메인별 시뮬레이션의 한계를 극복하기 위해 통합된 언어 기반의 월드 모델링을 제안한다. 기존 모델들은 특정 도메인(예: 조작, 주행)에 과적합되어 있거나 로봇 의존적인 제어 인터페이스를 요구하여 범용적인 로봇 학습 환경으로 사용하기 어렵다는 한계가 있다. 또한, 물리적으로 타당한 동역학을 학습하기 위해 필요한 대규모의 통합 데이터셋이 부족하여 다양한 환경에서의 물리적 상호작용을 모델링하는 데 어려움을 겪어왔다. 이를 해결하기 위해 저자들은 [Figure 1]에 제시된 것과 같이 일반 영상 데이터와 embodied 데이터를 결합한 EWK 데이터셋을 구축하고, 범용적인 언어 인터페이스를 활용하는 QWEN-ROBOTWORLD를 개발하였다.
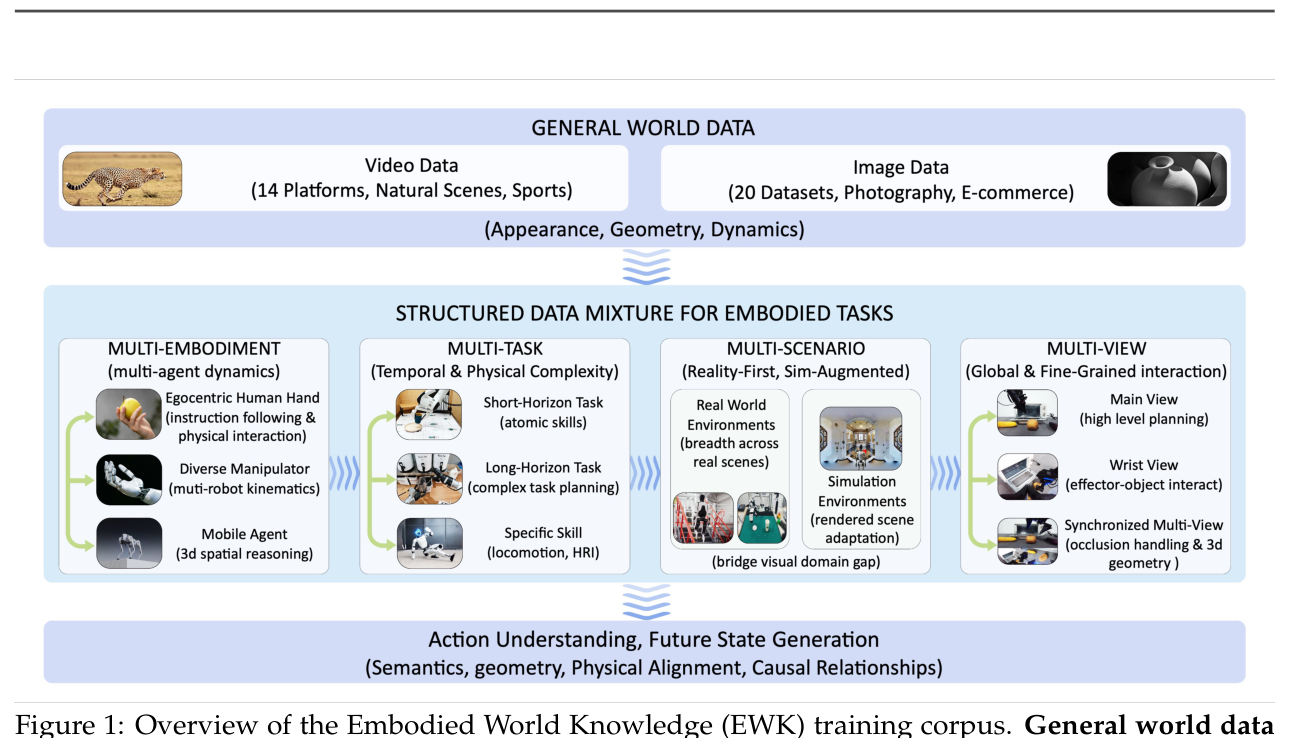
Figure 1 — 데이터셋 구조와 4가지 핵심 축을 보여주는 필수 다이어그램
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 본 논문은 Double-Stream MMDiT 아키텍처와 General+Expert Progressive Curriculum을 통해 일반적인 시각적 우선순위와 전문적인 로봇 제어 지식을 성공적으로 통합한다. 제안된 모델은 Qwen2.5-VL을 action encoder로 사용하여 복잡한 지시문을 정밀한 condition signal로 변환하며, joint attention을 통해 시각적 상태 전환을 생성한다. 성능 평가 결과, QWEN-ROBOTWORLD는 EWMBench에서 4.60점으로 1위를 차지하였으며, 특히 motion fidelity(HSD 0.566)와 scene consistency(0.914) 지표에서 압도적인 성능을 입증하였다. 또한 DreamGen Bench에서도 4.952점으로 1위를 기록하여 object-level compositional generalization과 물리적 정렬(physics alignment) 능력에서 우수성을 증명하였다. 이러한 결과는 [Table 2] 및 [Table 3]에 정량적으로 제시되어 있으며, 다양한 로봇 morphology에 대한 뛰어난 zero-shot 일반화 능력을 보여준다.
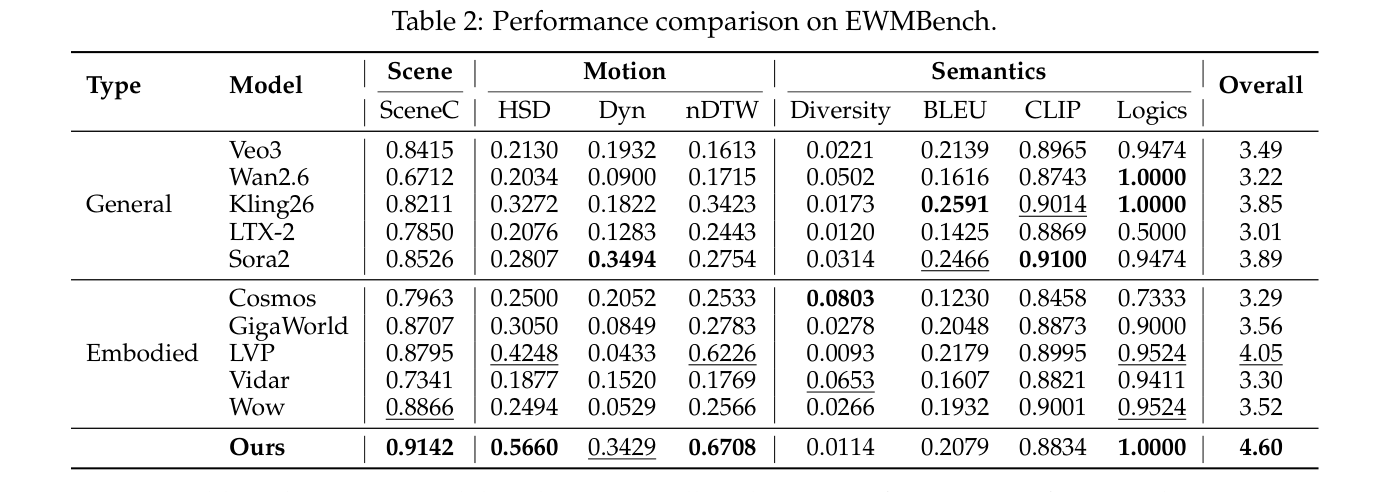
Table 2 — 주요 벤치마크인 EWMBench에서의 성능 우위를 보여주는 핵심 결과 표
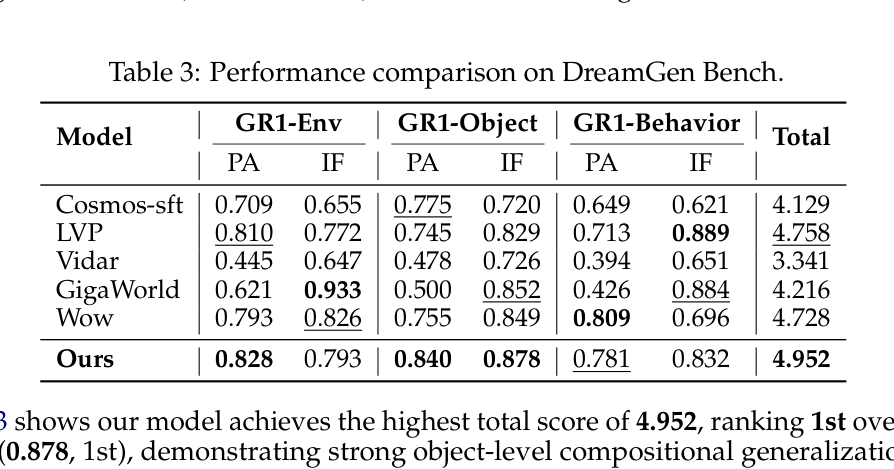
Table 3 — DreamGen Bench 결과 비교를 통해 모델의 일반화 성능을 증명
## 4. Conclusion & Impact (결론 및 시사점) 본 연구는 자연어를 유니버설 액션 인터페이스로 활용하여 embodied AI의 cross-scenario 학습을 실현한 새로운 월드 모델링 프레임워크를 정립하였다. 제안된 방식은 로봇 데이터 수집의 비용 효율성을 크게 높이고, 정책 평가 및 데이터 생성을 위한 강력한 가상 시뮬레이션 백본을 제공한다. 본 논문의 성과는 로봇 학습 분야에서 도메인 간의 물리적 지식을 상호 강화하는 새로운 학습 패러다임을 제시하며, 향후 범용 로봇 지능 개발을 위한 실질적인 토대를 마련하였다는 점에서 학계와 산업계에 큰 시사점을 준다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] DecMem: Towards Minute-Long Consistent World Generation with Decoupled Memory
- [논문리뷰] SANA-WM: Efficient Minute-Scale World Modeling with Hybrid Linear Diffusion Transformer
- [논문리뷰] WorldStereo: Bridging Camera-Guided Video Generation and Scene Reconstruction via 3D Geometric Memories
- [논문리뷰] Evaluating Gemini Robotics Policies in a Veo World Simulator
- [논문리뷰] UniUGP: Unifying Understanding, Generation, and Planing For End-to-end Autonomous Driving
Review 의 다른글
- 이전글 [논문리뷰] Prompt-Level Distillation: A Non-Parametric Alternative to Model Fine-Tuning for Efficient Reasoning
- 현재글 : [논문리뷰] Qwen-RobotWorld Technical Report: Unifying Embodied World Modeling through Language-Conditioned Video Generation
- 다음글 [논문리뷰] Retrieve, Don't Retrain: Extending Vision Language Action Models to New Tasks at Test Time
댓글